ChatGPT在GPT-3的基础上进行了人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)并对回答内容进行了“无害化”处理。ChatGPT的无害化处理更像是对模型结果的后处理步骤,并没有引入新技术。相比之下,RLHF是一个崭新的技术,它切实有效地拉大了ChatGPT与GPT-3的表现差异。可以说,RLHF是GPT-3进化成ChatGPT的关键技术。下面我们来详细介绍,人们如何通过RLHF将GPT-3训练成ChatGPT。
一句话概括RLHF,可以将其理解为“通过训练一个反馈模型(Reward Model,RM)来模拟人类对语言模型回答的喜好程度,然后借助这个反馈模型使用强化学习的方式来训练语言模型,使其生成的回答越来越符合人类的喜好。”
如图3.10所示,RLHF的训练过程可分为三个核心步骤。
(1)收集以往用户使用GPT-3的数据,进行有监督微调。
(2)收集回答质量不同的数据,组合训练反馈模型。
(3)借助反馈模型,采用强化学习算法PPO训练语言模型。
下面我们来具体介绍这三个步骤。
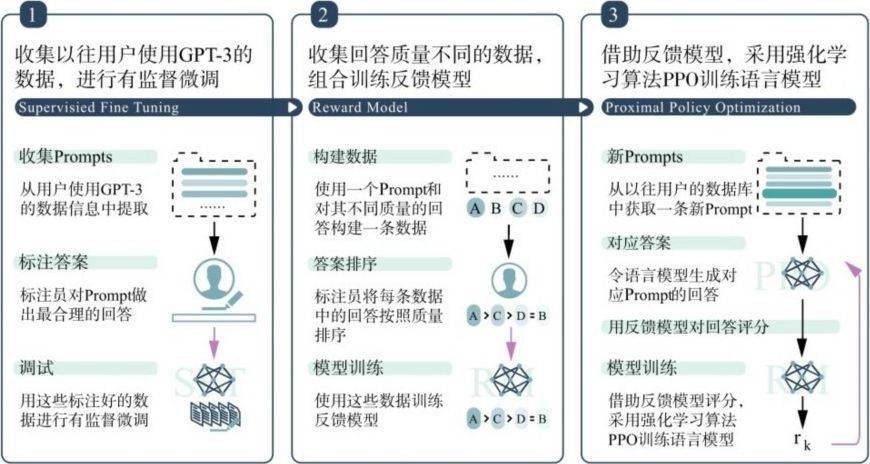
图3.10 RLHF流程示例图
有监督微调
第一步,从以往用户使用GPT-3时保留下的数据中选择大概1万条Prompt作为初始数据。这些Prompt应包含尽可能多样的任务类型与话题领域。并且,需要标注员对这些Prompt写出质量较高的回答,作为每条数据的标记结果。因为有监督微调中所有Prompt的回答最好由人工生成,因此这个阶段被称为“有监督微调”阶段。
实际上,有监督微调阶段与模型预训练阶段的训练方式是一样的,两者的唯一不同在于数据集的构成不同。预训练阶段采用的是大量自然文本,而有监督微调阶段采用的是“问题—答案”文本。
从宏观的角度来看,有监督微调阶段是为了让模型学习文字指令的意思(也就是Prompt的含义),并且能够根据不同的Prompt生成相应的答案。如上一段提到的,之所以有监督微调阶段让模型学习Prompt的含义,是因为生成式模型预训练阶段往往采用的是自然文本数据,其中可能包含一些文字指令,但其含量绝对没有有监督微调阶段数据集中指令文本的含量高。因此,有监督微调阶段可以被看作为了让模型理解文字指令而进行的“突击训练”。此外,在这一阶段并不要求模型可以回答符合人类喜好的答案,只是尽可能地保证答案格式和内容的正确性。
反馈模型的改进
第二步,训练一个反馈模型来对语言模型生成的回答进行质量考核,分数越高代表回答的质量越高,越符合人类的喜好。
反馈模型的技术要点在于其训练任务的设计。在对文本质量的考察上,分数往往是一个比较主观的考量方式。举例来说,面对两篇作文,不同的人对它们的评分可能并不在一个分数区间。有些人打分较高,有些人打分较低。如果只让人对模型生成的答案进行打分,很容易导致同一个文本分数差距较大的情况。计算平均分或许是一个不错的想法,但是平均分依然无法消除人的主观因素。
以相对分数为反馈模型的学习目标是一个好的想法。因为,虽然不同人的打分区间不一样,但是如果一篇作文的质量明显比另一篇质量高的话,不同人给好作文打的分数会高于差作文的分数。借助这个想法,将相对分数作为反馈模型学习的任务或许比将绝对分数作为模型学习的任务要合理。
具体来说,在这一步中,学者们首先会针对每一个Prompt搜集不同的回答,并将它们组合成一条条数据。然后,标注人员会根据每条数据中回答的质量进行排序。最后,其将回答的顺序作为学习目标去训练反馈模型。所以,当训练好的模型对一个回答的评分高于另一个回答时,我们有理由相信前一个回答的质量更好。
第二步完成后,反馈模型还可以用于评定第一阶段模型训练的效果。比如在第一阶段中选择了多个语言模型进行有监督微调,我们可以使用反馈模型对这几个语言模型生成的答案进行评分,选取生成分数最高回答的、次数最多的模型作为表现最好的模型。
近端策略优化算法
第三步,将借助反馈模型和选择的语言模型,采用近端策略优化算法PPO进一步提高模型的表现。
具体来说,近端策略优化算法是一种优化的强化学习算法。形象地说,在这个算法中,语言模型就如同舞台上的舞者,反馈模型就如同台下的评委。语言模型根据反馈模型的评分动态调整自己的策略,以获得更高的分数。由于反馈模型打出的分数越高,回答越受人类青睐,因此这个训练使得模型生成的回答越来越符合人类的喜好。
总而言之,RLHF训练的三个步骤可以让语言模型的回答越来越符合人类的喜好。也正是RLHF技术,使GPT-3进化为ChatGPT。值得注意的是,不论是GPT模型的预训练还是RLHF训练,其技术难点并不在于训练任务的设计,而在于高质量、大规模数据的获取。如果想得到一个表现优秀的中文ChatGPT应用,如何获取质量高、话题面广的中文数据集,如何对其进行数据预处理是最重要的。
至此,对ChatGPT的相关技术介绍告一段落。总结来说,ChatGPT的前身是一种基于Transformer解码器的预训练生成式大语言模型——GPT-3;在此基础上,ChatGPT通过RLHF技术使其回答更符合人类的喜好,并且通过合理的数据后处理保证了回答内容的安全性。