在介绍完自然语言处理的前置技术后,我们终于可以进入GPT的世界了。GPT模型是一种典型的预训练语言模型,它最先被设计用于有效理解文本,然后针对不同的下游任务(各种具体的任务)通过微调手段完成它们,实现一个模型解决所有问题的想法。
但是,在GPT的发展历程中,学者们发现,当GPT模型的参数量越来越多,预训练数据的质量越来越高、规模越来越大时,GPT模型不通过微调也可以完成各种具体的下游任务,真正实现了一个模型解决所有问题的想法。
下面,我们以GPT模型发展历程为脉络,来解释GPT为什么可以被作为一个预训练语言模型,以及它又是如何实现不做微调也可以完成各种具体任务的。
GPT-1的尝试
如图3.7所示,GPT-1模型是GPT的第一个模型,它是将12个Transformer模型的解码器叠加得到的一种预训练语言模型。由于Transformer解码器部分的主要功能是在每次训练过程中生成一个单词,因此GPT又被称为“生成式预训练语言模型”。与其他预训练语言模型一样,用GPT-1完成各种具体任务要经过两个步骤:预训练(Pre-Training)步骤与微调(Fine-Turning)步骤,下面我们依次介绍这两个步骤。
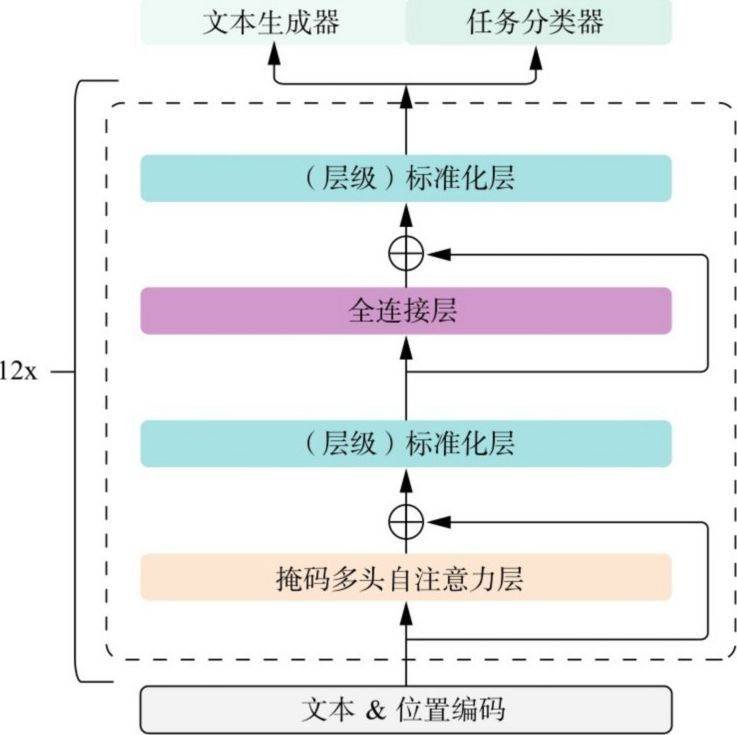
图3.7 GPT-1模型图解
无监督预训练
与前文描述的一样,预训练阶段的目标是通过设置合理的预训练任务,使GPT-1模型理解文本内容。具体来说,预训练任务可以理解为一个文本续写任务。首先,搜集大规模高质量的自然文本语料,对每条语料进行部分截断,令模型读入截断前的文本内容,然后,一个字一个字(更应该说是token)地预测截断后的内容。值得注意的是,这里预测的并不是输入文本后面的字具体是什么,而是输入文本后面的字的概率分布是什么(毕竟同样的输入文本,其后面所接的字很可能也是不一样的)。
由于该阶段训练使用的数据都是自然文本数据,不需要人工针对不同任务对数据打标签,因此该过程叫作“无监督预训练”。训练数据不需要人工标注,这让数据获取的工作量大大降低,使搜集大规模高质量的数据成为可能。
在经过预训练后,我们可以将GPT-1模型理解为一个具有续写能力的模型,也就是说,GPT-1初步具有理解文本的能力。
有监督微调
预训练后的GPT-1模型,可以通过微调来完成具体的下游任务。
下面以文本分类任务为例,讲解微调过程是如何进行的。对于文本分类任务,GPT-1模型需要将待训练的分类文本打上相应的标签,比如判断文本的情感态度是积极的还是消极的,这往往需要用数字来表示态度类别,并将态度类别对应的数字作为标签对应到各个文本上。如用0表示积极,用1表示消极,然后对每个训练文本打上0或1的标签。这一过程就是人工标注,使用这种数据进行训练,也被称为“有监督训练”。因此,微调过程也被称为“有监督微调”(Supervised Fine-Tuning,SFT)。
继续以文本分类任务为例,为了完成该任务,GTP-1模型还需要使用打好标签的数据进行有针对性的训练(此时数据量和训练量远远小于预训练阶段,因此被称为“微调”)。具体来说,GPT-1模型中解码器部分输出的最后一个单词的输出结果作为特征,送入一层线性层进行类别的预测。其实,这与预训练阶段是十分相似,预训练阶段是将解码器部分的输出送入线性层生成一个概率分布结果,而文本分类任务也是将解码器部分的输出送入线性层得到类别结果。此外,GPT-1的技术报告也指出,在微调阶段将预训练阶段的任务目标作为辅助任务有助于微调阶段模型提高泛化能力,并且也会加快模型的收敛速度。
除了分类任务,还有很多种下游任务。图3.8是GPT-1针对下游任务设计不同的输入数据样式图解。从图中可以看到,不同的任务需要对输入数据的形式做出改变,但模型整体架构的变化十分微小,其只需要在解码器部分之后增加相应的线性层就可以完成不同的下游任务。
由图3.8可以看到,对于分类任务,输入文本并没有做出多大的改变,其依旧是文本与其前后的起止符。但是,对于相似度比较的问题,其往往是先将两个进行相似度比较的文本按照两种前后顺序生成两条数据,然后分别通过GPT模型的解码器部分得到相应的中间结果,最后将中间结果拼接送入线性层获得相似度结果。按照两种前后顺序生成两条数据的目的是排除数据前后顺序不同对相似度结果的干扰。
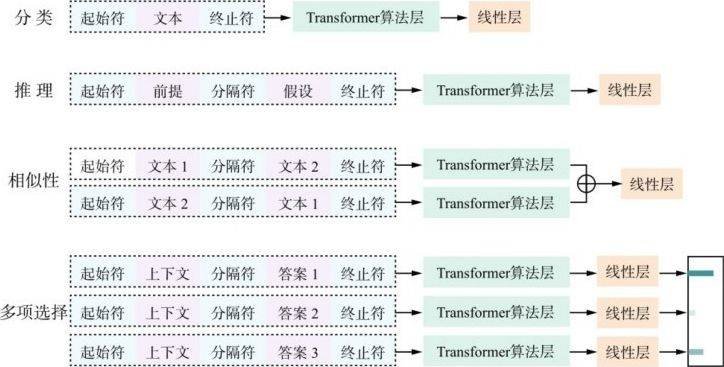
图3.8 GPT-1下游任务改造图解
其他下游任务,也是通过设计相应的输入数据类型,并对模型进行微调,通过少量的微调训练即可完成任务。这充分展现了GPT作为一种预训练模型的巨大潜力。
GPT-2的探索
提出GPT-1模型的学者对其潜力进行了进一步挖掘,提出了一个大胆假设:如果GPT模型理解文本的能力进一步提升,是不是针对各种下游任务,只通过文本的形式询问模型问题,它就能给出合理的答案呢?基于这种假设,学者们进一步研发了GPT-2模型。
GPT-2模型的核心思想是舍弃GPT-1中的微调环节和预训练后,将合理问题作为输入,令模型直接通过文字生成的方式生成答案,这种输入往往被称为一个“Prompt”。
释义3.7 文本情感分类任务的Prompt设计样式
针对判断“我今天很不开心”这句话的情感是消极还是积极的问题,Prompt可以设计为“问题:请判断<文本开始符>我今天很不开心<文本结束符>的情感为积极或是消极,答案:”。
对于文本情感分类任务,判断“我今天很不开心”的情感,可以设计相应的Prompt来表达具体问题(如释义3.7)。通过文字生成模型可以直接生成“积极”或是“消极”,完成文本分类。相似地,其他任务也可以通过设计相应的Prompt来完成。值得注意的是,这里的Prompt中并没有任何关于问题应该如何回答的提示,这种情况也被称为“零样本学习”(Zero-shot Learning)。
从以这种方式完成各种任务的效果上来看,GPT-2模型的表现要好于一些微调之后的语言模型,且它还有很大的发展空间。下面我们来介绍GPT-2在模型结构和预训练阶段相较于GPT-1做了哪些改变,从而使其可以具备如此神奇的能力。
从模型结构上来说,GPT-2与GPT-1的基本结构是一样的,都是多个Transformer解码器的堆叠。但GPT-2在一些解码器的细节方面做了调整,比如它调整了归一化层的位置,并新增了一层归一化层。更重要的是,GPT-2通过将解码器堆叠个数扩展到48个,增加多头注意力机制头数以及位置编码个数,大大增加了参数量。GPT-1只有1.2亿个参数,GPT-2的参数量却扩展到了15亿,这大大提高了模型学习文本的能力。
相比于模型参数量的增加,预训练数据规模的扩大也是GPT-2不需要微调的关键。GPT-1的预训练数据规模是5GB(吉字节),GPT-2的数据规模扩大到GPT-1的8倍,达到40GB。
从数据的选择上来说,GPT-2的预训练数据搜集的依旧是自然语言文本,其中有部分任务相关的文本,比如翻译任务的文本。但是,GPT-2数据搜集的理念是搜集尽可能多样化的数据以及覆盖尽可能广的领域,这使得GPT-2预训练所用的数据质量进一步提高。
因此,通过如此规模的数据预训练,GPT-2模型理解文本的能力进一步提升,模型的知识面也进一步扩大,模型展现出了不需要微调就可以完成下游任务的能力。此时,基于GPT的智能对话,算法的雏形已经形成。
GPT-3的强化
GPT-3可以说是GPT-2的强化版。从模型结构上来说,GPT-3相较于GPT-2只做了微乎其微的改变,因此这里不做过多介绍。但是GPT-3的参数量进一步增加,从GPT-2的15亿个参数量增加到1750亿个。理论上说,拥有1750亿个参数的模型的学习能力将会进一步提升。关于是否参数量越多,模型能力就会越大,还没有准确的说法。但是无论如何,GPT-3已经将参数量扩大到了千亿级的规模。
有关GPT-3的另一个重要发现在于Prompt的设计。OpenAI的研究员受到GPT-2不需要微调就可完成下游任务的启发,提出在Prompt设计时加入一定的提示,以提高模型完成具体任务的表现。他们基于这个想法,提出了GPT-3模型。具体来说,GPT-3的训练数据不再是单纯的自然语言文本,而是针对具体任务的高质量Prompt,并且每个Prompt中都会包含十几个到几百个案例提示。
以文本情感翻译任务为例,对应的Prompt可以设计为如图3.9所示的样子。在这个例子中,中间几个例子被称为小样本(Few-shot),模型根据这些小样本的提示,只需要通过前向计算的方式就可以获得期望的答案,这也被称为小样本学习(Few-shot Learning)。
 图3.9 GPT-3小样本学习的Prompt设计示例图
图3.9 GPT-3小样本学习的Prompt设计示例图
实验表明,通过这种小样本学习的方式,GPT-3即使只有几亿个参数,其表现也会好于拥有15亿个参数的GPT-2,这进一步证实了合理的Prompt设计对这种大语言模型来说是至关重要的。从数据质量和数据规模上来看,GPT-3预训练使用的数据量是远超GPT-2的。从其他千亿级别的大语言模型使用的数据规模来推测,GPT-3预训练使用的语料规模也应该达到了TB(太字节)的级别。
总而言之,GPT-3可以被看作模型参数和预训练数据量增加的GPT-2。此外,GPT-3也向人们展示了小样本学习的能力。至此,GPT-3已经可以作为一个比较不错的智能问答应用来使用了,它与ChatGPT的差距只在于如何给出更符合人类喜好的回答,以及如何保证回答的安全性。
ChatGPT也被称为GPT-3.5,可见其与GPT-3的关系之密切。在下一节,我们将继续从技术的角度介绍ChatGPT是如何给出符合人类喜好的回答,以及如何保证回答安全性的。