ChatGPT因其强大的功能,备受社会关注。通过前面的介绍,我们已经了解了ChatGPT的概念及特点,了解了智能对话系统。但是,为什么一直没有名气的智能对话应用在ChatGPT出现时博得了全世界的关注呢?ChatGPT到底拥有什么“黑科技”,从而能展现出类似人的机敏聪慧?本章将追根溯源,从技术角度对ChatGPT进行全方位解析,让读者了解ChatGPT到底是什么,并让读者对它产生更深层次的认识。
ChatGPT是由GPT模型驱动的,因此了解GPT的方方面面是了解ChatGPT的前提;同样,GPT也不是横空出世的,提起它就难免要提起让自然语言处理火爆的各种技术,比如编码器和解码器构成的端到端思想(Seq2Seq)、注意力机制、Transformer模型以及预训练思想(Pre-trained learning)。到底什么是解码器和编码器呢?注意力机制是什么,解决了什么问题呢?Transformer模型为什么这么重要,创新点在哪里呢?预训练思想、预训练语言模型又到底是什么?
或许读者已经在各种场合听过无数人将这些技术提起了无数遍,但是很多人依旧对它们没有具体的认知,还有些人觉得这些技术神秘莫测、晦涩难懂。不用担心,本章将以十分形象的例子和生动的讲解,带大家走近这些技术,了解它们,探寻ChatGPT的奥秘。
总而言之,本章将以技术传承为主要脉络,首先介绍与GPT有关的前置自然语言处理技术,使读者掌握进入ChatGPT的关键密码;其次介绍GPT是什么,它是如何演变的,让读者真正认识ChatGPT的内核;再次介绍GPT是如何变成如今火爆的ChatGPT,让读者完全掌握ChatGPT的核心科技;最后我们会对GPT技术的未来进行讨论,激发读者对ChatGPT未来的无限畅想。
前置自然语言处理技术
正如前文所说,如果想了解ChatGPT就要先去了解GPT本身。因此,本节内容将在读者与GPT之间搭建桥梁,介绍学习GPT前需要了解的知识。
那么,学习GPT我们都需要了解哪些前置技术呢?为了解答这个话题,我们可以从一句话讲起:“GPT是Transformer的解码器部分。”所以,要理解GPT就要先明白Transformer是什么。
释义3.1 Transformer
Transformer是一个采用注意力机制捕获上下文信息、以编码器和解码器为模型整体架构的端到端模型。它往往被用于各种转换任务,如将源语言转换成目标语言的翻译任务、将图片中的文本图像转换为文字的OCR(光学字符识别)任务等,故此得名Transformer。
可见,Transformer最重要的两个概念是“编码器和解码器构成的端到端模型”和“可以捕获上下文信息的注意力机制”。因此,作为本章的第一节,对前置技术的介绍将从解释“编码器-解码器框架是什么”以及“注意力机制是什么”开始,然后对Transformer模型进行全面介绍。
由于Transformer是一个处理“转换”任务的模型,最经典的“转换”任务就是翻译任务,即将一种语言的文字转换成另一种语言的文字。所以在对“编码器-解码器框架”“注意力机制”以及“Transformer模型”的介绍中,我们将以翻译任务串联起这三个概念。
至此还没有结束对GPT前置技术的介绍,因为GPT与Transformer在设计理念上是不同的。GPT模型的设计理念是“预训练理念”,这点是GPT与Transformer模型的本质区别。因此,在本节的最后,我们还会探讨“什么是预训练思想”。
探秘编码器—解码器
在讲述编码器和解码器之前,我们说说文本的特点,即文本是一个有顺序概念的数据。
举例来说,“我爱你”和“你爱我”这两句话的语义是完全不同的。但是,传统的前馈神经网络(Feedforward Neural Network,FNN)和卷积神经网络(Convolutional Neural Networks,CNN)并不能将语序纳入模型的学习中,去理解文字语序带来的语义差别。于是,学者们就提出了循环神经网络(Recurrent Neural Network,RNN)概念,即在每一个时刻只向模型传送一个输入数据,并且按照序列前进的方向,递归地令模型进行学习。
释义3.2 前馈神经网络
前馈神经网络,是一种最简单的神经网络,各神经元分层排列,每个神经元只与前一层的神经元相连。接收前一层的输出,并输出给下一层,各层间没有反馈,也没有顺序接受输入的功能。
释义3.3 卷积神经网络
卷积神经网络,是一类包含卷积计算且具有深度结构的前馈神经网络,是深度学习的代表算法之一。卷积神经网络具有表征学习能力,能够按其阶层结构对输入信息进行平移不变分类,因此也被称为“平移不变人工神经网络”。卷积神经网络没有顺序接受输入的功能。
释义3.4 数字编码形式
字符的数字编码形式是指将数字通过各种方法变成的可以用于计算的向量。
图3.1是用RNN解决翻译问题的示例图。在t1时刻,只向模型传送一个字符,即“我”(实际上是“我”这个字符的数字编码形式x1),经由计算,形成一个在RNN网络中按照输入方向传播的隐层向量h,在t1时刻称为h1。接下来h1会向两个方向传播,首先是经由计算形成t1时刻的输出,即图中的y1,它就是英文“I”的数字编码形式;更重要的是,h1会结合t2时刻的输入,即汉字“爱”的数字编码x2形成t2时刻的隐层向量h2。相似地,在每一个时刻都如此反复,直到翻译任务完成。这就是最初使用RNN完成翻译任务的模型架构。我们可以直观地理解为,每个时刻的输出结果都是由之前所有时刻的输入综合影响而形成的隐层向量和当前时刻的输入共同作用得到的。
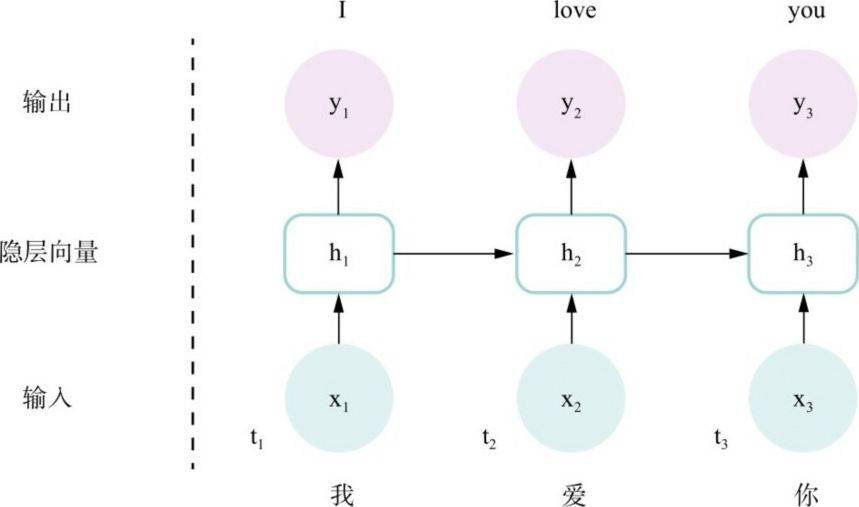
图3.1 RNN基本模型图例
这个模型存在一个致命的缺陷,即它没有考虑到翻译任务中不同语言语序不一致的问题。为了形象地解释这个问题,请看图3.2。英语中的“I love you”对应到日语的语序应该是“I you love”,此时如果用图3.1的模型完成英语到日语的翻译任务的话,t2时刻模型接受的应该是由“I”形成的隐层变量hI和“love”对应的数字编码xlove,但是模型需要输出的是“you”对应的日语单词,记作yyou,这显然是不合理的。

图3.2 不同语言语序的不同例图
一个合理的想法是先按照顺序读取所有的输入,形成一个隐层向量,然后再按照顺序用隐层向量一次次地形成所有的输出,这样语序不同的问题就可以部分解决。形象地说,先将所有输入按照顺序一层层地叠加在一起,形成一个“卷心菜”,然后再一层层剥开,每一层都是一个输出。将所有输出整合成一个隐层向量的过程叫做编码过程,对隐层向量一层层求解得到输出的过程就被称为解码过程。
如图3.3所示,与图3.1模型不同的是,在t1到t3时刻,模型并没有相应输出,这一过程可以看作将输入文字“I”“love”和“you”统一编码形成一个隐层向量,这一过程被称为编码过程,对应的这部分模型被称为编码器。从t4时刻开始,输入首先是源语言终止符“<end>”,之后每个时刻的输入是上一时刻的输出,直到得到所有输出为止,这一过程被称为解码过程,对应的模型结构被称为解码器(当然,这只是编码器-解码器模型的一种,它还有各种变体,但是整体理念是一致的)。
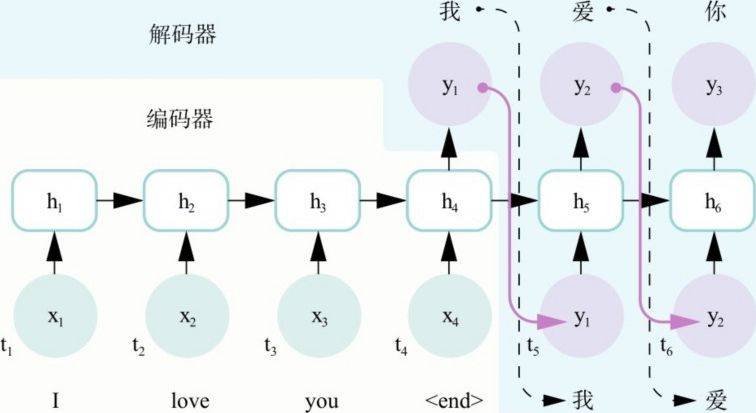
图3.3 解码器—编码器模型结构例图
Transformer模型架构也采用编码器-解码器架构。这个架构不仅考虑到如何学习数据的顺序特点,也针对输入数据与输出数据顺序可能不同的特点而给出了相应对策。
但同时,这个架构也有其局限性:首先,每个时刻的输入限制了模型的计算速度;其次,由于模型本身学习方法的限制(反向传播,通过求导寻找参数梯度方向),各时刻的输入对编码器形成的隐层向量所做出的贡献并不是均等的,也就是第一个时刻的输入或者最后一个时刻的输入对隐层向量的影响是最大的,这也被称为RNN梯度爆炸或者梯度消失。为了解决这些问题,Transformer又引入了注意力机制。
探秘注意力机制
注意力机制到底是什么呢?它究竟是怎么实现的呢?它的后续影响又如何呢?首先,按照惯例,我们先对注意力机制进行简单的概括。
释义3.5 注意力机制
注意力机制是一种使用卷积计算解决RNN不能真正双向捕获上下文以及不能并行计算的双向捕获上下文机制。
别急,在了解完释义后,探究“注意力”前,我们再次明确一下RNN的两个问题。
(1)RNN不能真正双向捕获上下文是由于其模型的数据输入方向在每一层只能固定一个方向,这一点是模型结构本身造成的缺陷。此外,由于这个缺陷,RNN还存在梯度消失或梯度爆炸的问题。换句话说,在某一时刻ti时,之前各个时刻的输入x对其隐层向量hi的影响是不一致的,并且不能自由调整。
(2)RNN由于需要按照输入顺序进行模型前向传播和反向传播,因此不能使用并行方式来加快训练速度(也有关于如何使RNN并行计算的相关研究,但RNN本身的设计理念是排斥并行计算的)。
事物的发展规律总是符合否定之否定规律,关于如何捕获上下文的研究也是如此。当前馈神经网络和卷积神经网络大行其道时,人们根据时序数据的顺序特点提出了RNN。但是为了解决RNN的两个缺陷,2017年谷歌公司又将捕获上下文的方法回归到卷积计算中,这个计算方法被称为“注意力机制”。我们应该称这种进步为“螺旋式的进步”。
释义3.6 Q、K、V向量
为了让注意力机制模拟人类对不同事物具有不同注意力的特点,人们提出使用三种向量以及相应的计算方法来模拟注意力行为。举例来说,Q向量可以理解为某个人,V向量可以理解为具体的事物,K向量可以理解为人对不同事物的关注度程度,Q向量和K向量的点乘计算结果可以理解为人对某一个事物的关注度程度,将这个关注度程度与V向量相乘可以理解为这个事物在这个人眼中的表现形式。
下面我们以自注意力机制为例,简要介绍注意力机制的实现流程:简单来说,注意力机制为每一个输入设计了三种参数向量,分别称作Q向量、K向量和V向量;对于一个输入x(这里指代一个token,可以理解为中文文本数据的一个字),首先使用它的Q向量与其他所有输入的K向量分别做卷积计算,除以一个定值,并使用Softmax(一种缩放算法)缩放之后,得到每个输入对输入x的影响力权重;然后,将所有输入的影响力权重乘以V向量,并将结果相加求和,得到最终输入x综合各输入之后的注意力结果。
实际上,相应的Q、K、V向量是通过输入x乘以相应的权重向量得到的,这里称为WQ、WK、WV。更进一步,当同时训练多条数据时(也就是Batch Size大于1),WQ、WK、WV则是标准权重矩阵,整个注意力机制计算也就是一种标准的卷积计算。
如图3.4所示,这是一个形象的自注意力机制计算图例,它展示的是通过自注意力计算,将上下文加入a1,形成b1的具体过程。整个过程与上一段的描述一致,先通过a1的Q向量q1与其他输入的K向量做卷积计算,并通过缩放形成各个输入对a1的影响比重a'1,1;然后,将各个输入的V向量与各自的比重做乘法之后加在一起,就得到了a1添加上下文之后的结果——b1。
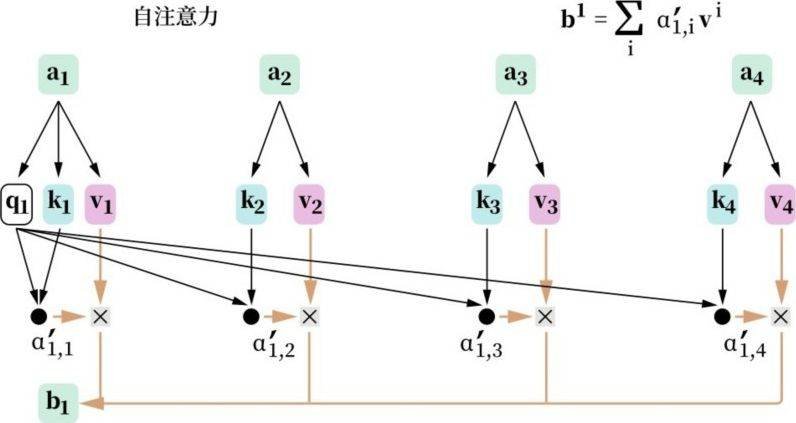
图3.4 自注意力机制计算图例
这种自注意力机制的好处有两点:(1)通过对相应权重进行控制,不同输入对学习结果的影响是可控的,解决了RNN的梯度消失问题。(2)由于注意力机制主要通过卷积计算完成,不存在计算顺序的问题,因此可以用并行计算的方式实现。当然,注意力机制的优点还有很多,如因其通过参数可以灵活调整相似权重,这为大参数量的语言模型理解语言的能力提供了无限可能性。
总而言之,注意力机制的提出可以说是划时代的创新。
Transformer:端到端模型的里程碑
了解了编码器-解码器原理和注意力机制,我们已经掌握了Transformer最核心的两把钥匙。下面我们来一睹Transformer的真容。按照惯例,我们再次对Transformer进行概括:它是一个采用注意力机制捕获上下文信息、以编码器和解码器为模型整体架构的端到端模型,它常被用于各种输入和输出格式不一样的转换任务,比如翻译任务。
图3.5是Transformer模型的详细图解。整体来看,它是基于编码器-解码器概念设计的模型,图中左边部分是模型的编码器,右边部分是模型的解码器。
以中文翻译成英文任务为例,整个模型的训练流程是将中文文本作为模型,在左边编码器进行输入,获取每一个输入单词(更准确地说是一个token)的Q值和K值,将其输送到解码器部分;解码器部分每次预测一个单词的内容,并且每次预测都将之前预测的结果作为解码器的输入(这一点与上文RNN编码器-解码器是一致的);解码器部分将之前输出的英文内容结合编码器传过来的中文Q值和K值来预测下一次的英文内容。
 图3.5 Transformer模型图解
图3.5 Transformer模型图解
还是基于图3.5,下面详细介绍图中的具体细节。Trans-former的输入不仅是单词的数字编码形式,也将位置信息(使用位置编码,Positional Encoding)融入其中;这是因为注意力机制虽然考虑了上下文信息,但没有考虑上下文对应某个词的位置信息,这是对注意力机制的进一步改良。但值得注意的是,Transformer采用的位置编码是一种绝对位置编码,后来的GPT采用的是一种可以学习的相对位置编码,是对Transformer的进一步改良。
至于Transformer的编码器部分,每个编码器都由4部分组成:多头自注意力层、残差层和(层级)标准化层、全连接层、第二个残差层和(层级)标准化层。它们各自的功能如下。
(1)多头自注意力层:编码器使用多头注意力机制进行注意力计算。这里的多头注意力机制可以理解为将多个自注意力计算结果合并在一起。
(2)残差层和(层级)标准化层:在进行完注意力计算后,还需要经过一层残差层(就是简单的加运算)和(层级)标准化层。残差层的目的是解决深层神经网络无法有效学习的问题。(层级)标准化层的目的是消除输入长度不同对模型预测结果的影响。
(3)全连接层:再下一步采取了一个标准的全连接神经层。该层设计的目的是通过激活函数对数据进行一次非线性变换,以进一步激活模型对数据的学习能力。
(4)第二个残差层和(层级)标准化层:此层的作用与第一个残差层和(层级)标准化层的作用一致。
整个编码器部分由多个编码器叠加组成。采用多个编码器是为了通过增加参数量以提高模型的学习能力,标准的Trans-former叠加6个编码器。经过6个编码器计算后,将最后一次计算得到的每个单词的Q、K值传送给解码器来进行辅助预测。
解码器的输入与编码器的输入一样,都需要加一个位置编码。此外,每个解码器的构造与编码器大体一样。解码器与编码器的区别如下。
(1)解码器采用掩码多头注意力机制:解码器的第一步采取的不是多头注意力机制,而是掩码多头注意力机制。掩码可以理解为不让模型看到的部分。通过掩码,让解码器部分不能看到当前预测位置及其之后位置的内容(也就是无法将掩码部分纳入注意力计算当中),以实现文字的预测。这是因为注意力机制并不能像RNN那样是顺序预测的,因此需要通过掩码来模仿预测的顺序。
(2)多头注意力机制的输入不同:除了掩码多头注意力计算,解码器部分还包含一个多头注意力计算模块,不过该模块的三个输入中的Q值和K值是由编码器部分传送过来的,只有V值采用的是掩码多头注意力计算的结果。这可以理解为达到综合编码器结果和之前预测的输出结果来生成当前输出的效果。
通过6层解码器,再经由线性(Linear)层和Softmax层之后,解码器部分可以输出预测的数字编码。在这个中译英的翻译任务中对应的是一个英文数字编码。
所以,Transformer模型是将编码器-解码器思想和注意力机制有效融合的模型。从模型结构上来说,GPT模型只使用了Transformer模型的解码器部分,但是GPT与Transformer模型的用法是完全不同的。Transformer的提出是基于完成实际的翻译类任务,而GPT的提出是基于预训练思想。在下一小节中,我们将介绍预训练模型。
预训练模型的前世今生
依惯例,先用一句话概括预训练模型的核心思想:只通过一个通用模型即可完成不同的算法任务。
也就是说,通用模型如同一把万能钥匙,它可以打开任何“任务”的锁。比如,一个预训练语言模型既可以完成自然语言理解的分类任务、命名实体识别任务和指代消解任务等,又可以完成自然语言生成的智能对话任务、阅读理解任务和续写任务等。
举一个形象的例子,如图3.6所示,预训练语言模型的终极思想是可以根据不同的输入,生成相应的回答。比如:当你问它常识问题或者进行对话时,它会回答有意义的文字内容;当你问它分类问题时,它只回答你简短的类别答案。
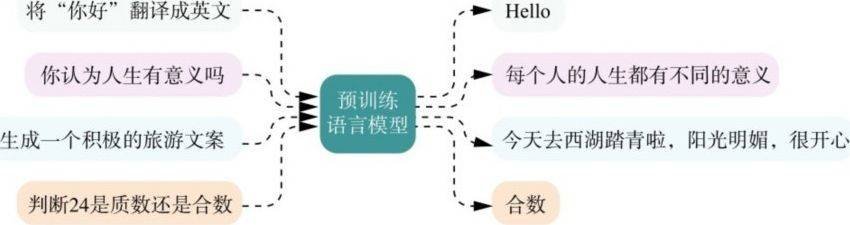 图3.6 预训练模型理念图解
图3.6 预训练模型理念图解
在上一小节的各种模型例图中,模型的输入并不是原本的单词,因为模型并不能用单词完成各种数学计算,而是将单词变成相应的数字表示。因此,设计单词合适的数字表现形式是十分重要的问题。预训练思想也诞生于对单词的数字表现形式的探索。
换句话说,预训练思想最早可以追溯到学者对词向量的研究。下面我们从预训练思想的源头——独热编码开始,探究预训练思想的前世今生。
预训练思想的源头——独热编码
单词的数字表现形式被称为“独热编码”(One-Hot)。这种编码旨在用数字表示单词在词典中的顺序,比如词典中有5个排好顺序的词,分别为“我”“爱”“北京”“天安门”“。”,那么“我”对应的独热编码为“[1,0,0,0,0]”,而“天安门”对应的独热编码为“[0,0,0,1,0]”。
这种独热编码简单直观,但当词典中词的数量增加时,它会出现编码过于稀疏的问题。也就是说,单词的数字表示中有太多的“0”,进而使模型无法进行有效计算,使模型表现不佳。为了解决独热编码的问题,学者进行了各种研究,其中对后世极具意义的就是关于词向量的研究。
独热编码的进化——词向量
在独热编码提出后不久,学者们提出了词向量的概念。词向量是通过预设各种训练任务,训练多层感知机(也就是多层前馈神经网络)模型,让模型可以有效预测文字,进而将模型参数矩阵当作单词的数字表示方法。
经典的词向量包括Word2Vec[插图]和GloVe。它们的训练基本思想一致,我们以Word2Vec为例来简要介绍一下词向量的思想。
Word2Vec的训练往往可以采用两种类型的经典训练任务:一种是输入目标单词邻近单词的独热编码,令模型预测目标单词的独热编码;另一种是输入目标单词的独热编码,令模型预测其相邻单词的独热编码。通过这两种类型训练任务后,模型认为已“理解”文字本身。此时可以将模型的参数矩阵作为词向量矩阵,然后以单词的独热编码与词向量矩阵的乘积结果作为该单词的词向量。
实验表明,用这种词向量作为单词的数字表示的效果要优于独热编码。但这种词向量也存在一个问题,一旦词向量矩阵确认之后,这个单词的词向量就是固定的,这不符合一词多义的实际情况。比如“我想买个苹果手机”和“我吃了个苹果”这两句话中的“苹果”一词并不是一个意思,它们的词向量也应该是不同的。
预训练的本质——可学习的词向量
为了解决一词多义的问题,学者们又提出了将词向量模型作为后续任务模型的一部分参与后续模型训练过程的想法。这个想法就是预训练模型的雏形,其首个成功案例就是采用Bi-LSTM(一种改良版的RNN模型)的ElMo模型。该模型提出后不久,划时代的预训练模型GPT和BERT相继问世,这里对该模型不做过多介绍。
通过上文的介绍,我们可以对GPT有一个初步的概念,它是一个通过设计合理的预训练任务模型学习单词数字表示的模型,并且这个模型可以作为其他模型的一部分参与完成各种具体任务的学习过程。GPT使用了Transformer解码器部分,它可以通过注意力机制获得极强的捕获上下文能力,可以根据不同语境生成符合语境的单词数字表示,解决Word2Vec和GloVe词向量固定的问题。并且由于GPT模型本身体量较大,学习能力较好,因此以GPT为基础完成实际任务的模型只需稍作改动,通过极少次数的训练即可完成各种实际任务,初步实现了一个预训练模型完成各种任务的想法。这种对GPT模型结构小幅度的改动和预训练以及之后针对具体任务的训练被称为对预训练模型的微调(Finetuning)过程。
在下一节,我们将详细介绍GPT的发展历程及其训练任务。