内容纲要
在向量检索里,search_type = dense / sparse / hybrid指的是“用什么信号来判断‘相关’”。三者不是版本高低,而是信息来源不同。
一句话先给直觉
- dense(稠密向量):
用语义相似度找“意思像”的内容 - sparse(稀疏向量):
用关键词匹配找“词一样”的内容 - hybrid(混合):
语义 + 关键词一起算分
一、dense(稠密向量检索)

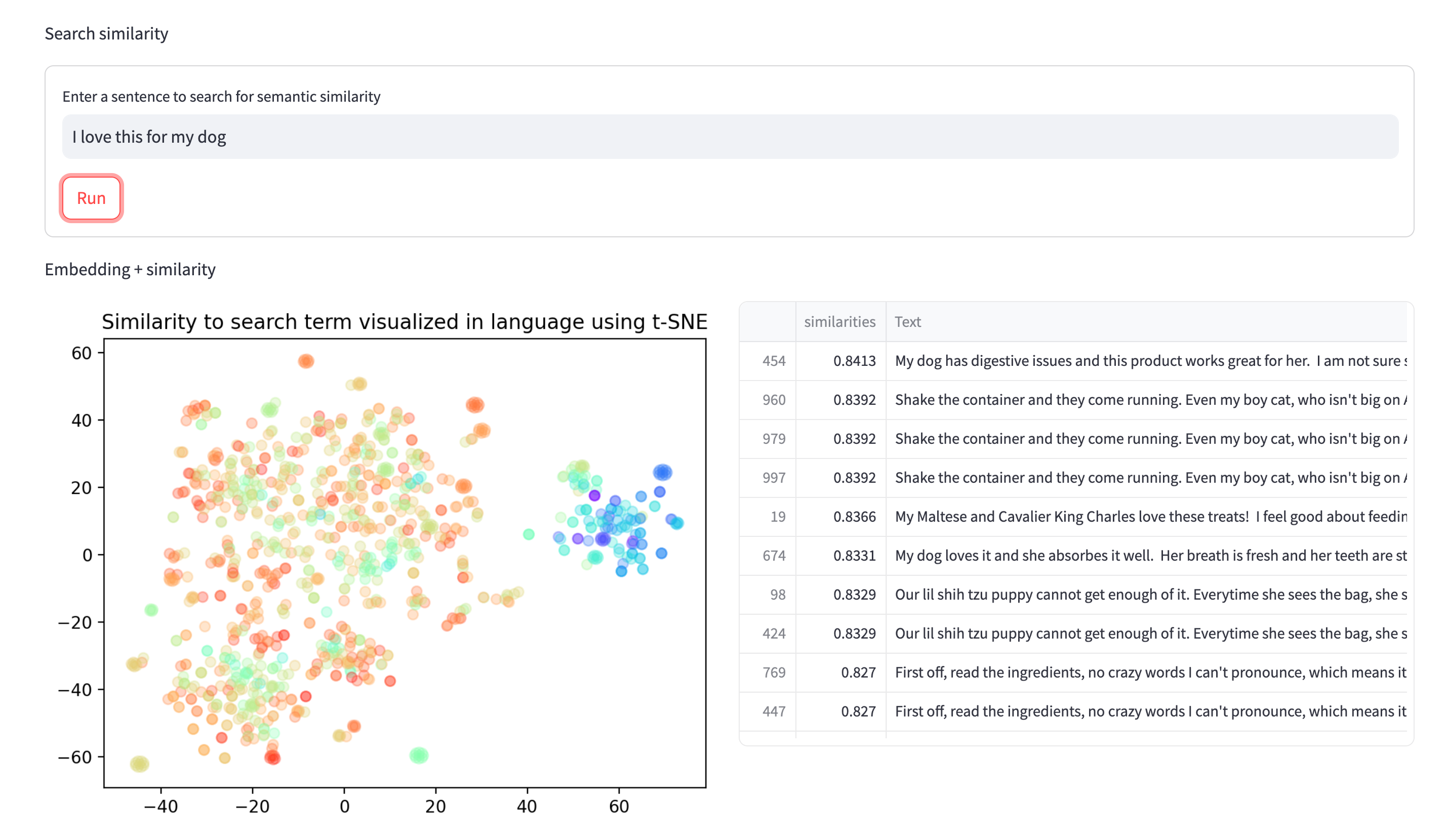
是什么
把文本编码成一个低维、稠密的向量(如 768 / 1024 维),用向量距离(cosine / dot / L2)衡量语义相似度。
解决什么问题
“词不一样,但意思一样,能不能找到?”
典型能力
- 同义表达
- 改写、口语化
- 抽象问题
示例
用户问:
“怎么提高 RAG 检索效果?”
即使文档里写的是:
“检索召回率优化策略”
dense 也能命中。
优缺点
优点
- 语义强
- 抗表达变化
缺点
- 对专有名词/精确词不敏感
- 可能“语义像但不对题”
适合场景
- 问答
- 分析 / 总结
- 文档理解
- 用户自然语言输入
二、sparse(稀疏向量检索,关键词检索)


是什么
用词频 / 关键词匹配(BM25、TF-IDF、倒排索引),向量维度极高但绝大多数为 0。
解决什么问题
“我就要这个词,一个字都不能错”
典型能力
- 精确字段
- 报错信息
- 代码 / 参数 / ID
示例
用户问:
“Milvus 中 IVF_FLAT 和 HNSW 区别?”
sparse 能直接锁定这些词。
优缺点
优点
- 精准
- 可解释
- 对专业术语极强
缺点
- 不懂同义
- 不会“联想”
适合场景
- 报错排查
- API / 配置查询
- 法律条文 / 标准
- 日志、字段、SQL
三、hybrid(混合检索)


是什么
dense + sparse 一起用,然后合并打分(加权 / rerank)。
本质
“意思像 + 关键词对,才是真的相关”
两种常见实现
-
并行检索
- dense 查一批
- sparse 查一批
- 合并 → rerank
-
联合打分
score = α * dense_score + β * sparse_score
优缺点
优点
- 稳定
- 召回高
- 工业级默认
缺点
- 复杂
- 成本更高
- 参数更多
适合场景
- 企业知识库
- RAG 生产系统
- 技术文档问答
- Agent 工具检索
四、三者对比速查表
| 维度 | dense | sparse | hybrid |
|---|---|---|---|
| 关注点 | 语义 | 关键词 | 二者 |
| 抗改写 | 强 | 弱 | 强 |
| 精确命中 | 中 | 强 | 强 |
| 复杂度 | 低 | 低 | 中 |
| 工业推荐 | ⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐ |
五、什么时候选哪个?(直接抄)
✅ 选 dense
- 用户问题自然
- 表达不稳定
- 想“懂意思”
search_type = dense
top_k = 20~50✅ 选 sparse
- 问题短
- 专有名词多
- 要“一字不差”
search_type = sparse
top_k = 5~10✅ 选 hybrid(强烈推荐)
- 生产环境
- 企业知识库
- 不想赌用户表达
search_type = hybrid
dense_weight = 0.6
sparse_weight = 0.4
rerank = on六、一句工程师总结(很关键)
dense 解决“你在说什么”,
sparse 解决“你说的是不是这个词”,
hybrid 解决“这事能不能稳定跑”。