最近接了个活儿,要做一个针对北京周边“农家乐”用户评价的情感分析模型。需求不复杂,就是把用户的评论分成积极、消极和中性/建议三类。我心想这不就是个文本分类任务嘛,挺常规的。

第一反应当然是去“军火库”里找现成的弹药。Hugging Face Hub、Kaggle、天池……各种数据集社区我翻了个底朝天。结果你猜怎么着?关于酒店、电影、商品的评论数据集倒是成吨成吨的,但专门针对“农家乐”这种特定场景的,一个能打的都没有。现有的数据集要么太通用,要么就是领域差太远,根本抓不住“柴鸡蛋”、“烤虹鳟”、“老板娘热情”这种接地气的评价点。
得,看来是没法“站在巨人的肩膀上”了,只能自己动手,丰衣足食。
这篇文章就是想把这次从零开始“手搓”一个NLP数据集的完整过程记录下来,给刚入门的同事们当个参考。这里没有高大上的理论,只有一步一个脚印的实践,以及一路上我踩过的各种坑和一些个人吐槽。毕竟,在机器学习项目里,大家总说“算法是核心”,但真正做起来你才会发现,真正决定模型上限的,往往是这些“无聊”的数据准备工作。

1. 搜寻开始 - 界定范围与寻源
万事开头难,第一步是确定从哪儿搞原始数据。
选题思路与数据来源
既然是农家乐评论,那自然要去各种旅游、点评网站上找。我没有选那些有严格反爬机制的大厂平台(那样会把这篇文章的重点带偏到反爬攻防战上),而是找了一个中等规模、内容比较垂直的本地生活分享网站。这种网站的反爬策略相对初级,更适合作为教学案例。
开工前,有个好习惯是先看看网站的robots.txt文件,也就是所谓的“君子协议”。访问http://目标网站.com/robots.txt就能看到。这个文件会告诉你网站主人允许哪些爬虫访问哪些页面。虽然它没有强制约束力,但遵守它是一种基本的网络礼仪。当然,有时候为了数据,我们可能需要稍微“灵活”一点。
侦察:摸清数字地形
确定目标后,就该进行“战前侦察”了。我用的是最简单直接的工具:浏览器自带的开发者工具(右键 -> “检查”或“Inspect”)。
随便打开一个农家乐的评论页面,对着一条评论右键“检查”,浏览器就会高亮出这段文字对应的HTML代码。你需要像个侦探一样,仔细观察这块代码的结构。我发现,每一条评论都被包裹在一个<div>标签里,这个<div>有一个很独特的class属性,比如class="review-card"。而评论的正文内容,则在它内部的一个<p>标签里,class是review-text。
这就是我们要找的规律。通过这个规律,我们就能写程序,像“庖丁解牛”一样,精准地把成千上万条评论从杂乱的HTML代码里剥离出来。
搭建“作坊”:项目结构
在写下第一行爬虫代码之前,我强烈建议先把项目的文件结构搭好。一个清晰的结构能让你在项目后期不至于手忙脚乱,也是项目可复现、可协作的基础。别小看这一步,它能帮你从精神上把整个数据生命周期(原始、处理、标注)分离开来。
这是我习惯用的结构,可以直接抄作业:
| 目录 | 用途 |
|---|---|
/project_root |
项目根目录,会用Git进行版本管理。 |
/data/ |
所有数据集的总目录。 |
/data/raw/ |
存放爬下来的原始数据,这里的文件是只读的,绝不修改。 |
/data/processed/ |
存放清洗、标准化之后,等待标注的数据。 |
/data/annotated/ |
存放最终标注完成、可以用来训练模型的数据。 |
/scripts/ |
存放所有的Python脚本(爬虫、清洗、质检等)。 |
/notebooks/ |
存放用于探索性数据分析的Jupyter Notebook。 |
/annotation/ |
存放标注工具的配置文件、标注指南等。 |
dvc.yaml |
(后面会生成)DVC流水线定义文件。 |
2. 网页抓取 - 代码、封锁反制
结构搭好了,可以正式开干了。
初次试探:一个简单的爬虫
我用Python的requests库来发送HTTP请求获取网页内容,再用BeautifulSoup4库来解析HTML。这俩是爬虫界的黄金搭档,简单又好用。
# 先安装
# pip install requests beautifulsoup4
import requests
from bs4 import BeautifulSoup
import time
import random
# 目标URL
URL = "http://example-review-site.com/beijing-agritainment?page=1"
# 发送请求
response = requests.get(URL)
# 使用html.parser来解析
soup = BeautifulSoup(response.text, 'html.parser')
reviews =
# 根据刚才侦察到的规律,找到所有评论的容器
review_containers = soup.find_all('div', class_='review-card')
for container in review_containers:
# 提取评论文本,并去掉首尾多余的空格
review_text_tag = container.find('p', class_='review-text')
if review_text_tag:
review_text = review_text_tag.text.strip()
reviews.append(review_text)
# 打印前5条看看效果
print(reviews[:5])跑了一下,第一页的数据很顺利地拿到了。看起来不错。
踩坑:网站开始反击了
当我尝试写个循环去爬取第2页、第3页……的时候,问题来了。爬了大概十几页之后,程序开始报错,返回的状态码是403 Forbidden,或者有时候干脆返回一个空页面。这就是遇到了最常见的反爬虫机制。
服务器后台的日志一看,同一个IP地址,顶着一个python-requests/2.25.1的默认User-Agent,以每秒好几次的频率疯狂请求,这行为简直就是在脑门上贴了“我是爬虫”四个大字。不封你封谁?
爬虫和反爬虫的斗争,本质上是一场“伪装游戏”。你要让你的程序看起来尽可能像一个真实的人类用户。

解决方案1:伪装身份 (Headers)
User-Agent是HTTP请求头的一部分,它会告诉服务器你用的是什么浏览器。我们可以把它改成主流浏览器的User-Agent,这是最基础的伪装。
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
# 在请求时带上headers
response = requests.get(URL, headers=headers)你可以在网上轻松找到一堆主流浏览器的User-Agent列表,甚至可以搞一个列表,每次请求随机选一个,伪装得更彻底。
解决方案2:放慢脚步 (Rate Limiting)
真人浏览网页是有间隔的,不可能一秒钟点开好几个页面。所以在每次请求之间,加上一个随机的延迟是十分必要的。这既是对目标网站服务器的尊重,也是一种有效的反反爬策略。
# 在循环的末尾加上
time.sleep(random.uniform(2, 5)) # 随机休眠2到5秒解决方案3:隐身斗篷 (Proxies)
如果目标网站的反爬策略更严格,比如会封禁单个IP,那就需要用上代理IP池了。每次请求都通过不同的代理服务器发送,这样在目标网站看来,就是不同的用户在访问。对于我们这个项目来说,前两种方法已经足够,但代理是爬虫工程师工具箱里必备的一项大杀器。
全面开火
把上面的反反爬策略整合进代码,写一个完整的循环来处理分页,然后把爬取到的所有评论逐行写入文件,存放在之前创建的/data/raw/目录下。
#... (前面的代码)...
all_reviews =
# 假设总共有50页
for page_num in range(1, 51):
page_url = f"http://example-review-site.com/beijing-agritainment?page={page_num}"
print(f"正在爬取第 {page_num} 页...")
try:
response = requests.get(page_url, headers=headers, timeout=10)
response.raise_for_status() # 如果状态码不是200,会抛出异常
soup = BeautifulSoup(response.text, 'html.parser')
review_containers = soup.find_all('div', class_='review-card')
if not review_containers:
print(f"第 {page_num} 页没有找到评论,可能已到达末页。")
break
for container in review_containers:
review_text_tag = container.find('p', class_='review-text')
if review_text_tag:
all_reviews.append(review_text_tag.text.strip())
# 礼貌地等待
time.sleep(random.uniform(2, 5))
except requests.exceptions.RequestException as e:
print(f"请求第 {page_num} 页失败: {e}")
continue
# 保存到文件
with open('data/raw/raw_reviews.txt', 'w', encoding='utf-8') as f:
for review in all_reviews:
f.write(review + '\n')
print(f"爬取完成!共获得 {len(all_reviews)} 条评论。")经过一番折腾,我最终爬取了大概2万多条原始评论,文件大小约60MB。数据有了,但现在它还是一块“毛坯”,需要精加工。
3. 清洗 - 从数字泥潭到可用文本
数据清洗是整个流程中最繁琐但也最见功底的一环。
初探“案发现场”
我用pandas把原始数据加载进来,初步审视一下这批数据的“尊容”。
import pandas as pd
df = pd.read_csv('data/raw/raw_reviews.txt', sep='\n', header=None, names=['raw_text'])
print(df.info())
df.head()不看不知道,一看吓一跳。数据里混杂着各种“牛鬼蛇神”:
- 残留的HTML标签,比如
<br/>、 - 繁体字和简体字混用(估计是港台同胞也来京郊玩了)。
- 各种表情符号,比如😂、👍。
- 无意义的模板化文本,比如“——来自iPhone客户端”。
踩坑:“一国两字”与表情包泛滥
对于中文NLP任务,文本清洗有其特殊性。通用的清洗流程(比如转小写、去标点)是远远不够的。
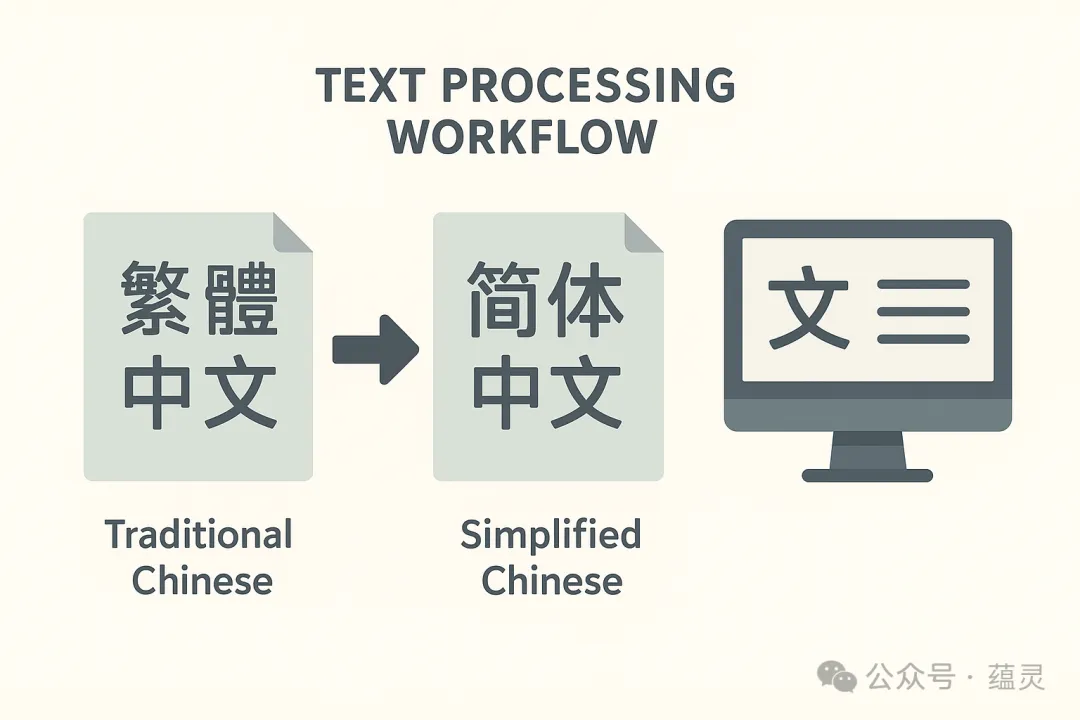
解决方案1:统一文字
模型会把“飯店”和“饭店”当成两个完全不同的词,这会严重干扰模型的学习。所以,我们需要把所有的繁体字都转换成简体字。这里我推荐一个纯Python实现的库opencc-python-reimplemented,它不需要安装额外的C++依赖,非常方便。
# pip install opencc-python-reimplemented
from opencc import OpenCC
cc = OpenCC('t2s') # t2s 表示 Traditional to Simplified
df['clean_text'] = df['raw_text'].apply(lambda x: cc.convert(x))当然,也有其他选择,比如chinese-converter 或 dragonmapper,效果大同小异。
解决方案2:处理表情包和HTML

表情符号对于情感分析任务来说,有时候是有用的信息。但在这个项目中,为了简化问题,我选择将它们全部移除。移除表情符号最有效的方法是使用正则表达式。
下面这个函数是我从网上搜集并改良的一个比较全面的版本,可以过滤掉大部分Unicode中的表情和符号。
import re
def remove_emojis_and_symbols(text):
# 移除表情符号
emoji_pattern = re.compile(
"+",
flags=re.UNICODE,
)
text = emoji_pattern.sub(r'', text)
# 移除残留的HTML标签
html_pattern = re.compile('<.*?>')
text = html_pattern.sub(r'', text)
return text
df['clean_text'] = df['clean_text'].apply(remove_emojis_and_symbols)解决方案3:将emoji替换为有意义的情绪表达替代词
直接删除表情符号会导致情感信息丢失,影响后续情感分析的准确性。更好的做法是将表情符号映射为对应的情绪描述词,保留用户情感表达的语义(可根据实际业务场景定夺)。
import re
import emoji
def replace_emojis_with_emotion_words(text):
"""
将文本中的表情符号替换为有意义的情绪表达词汇
参数:
text (str): 包含表情符号的文本
返回:
str: 表情符号被替换为情绪描述的文本
"""
# 创建表情符号到情绪词汇的映射字典
emoji_emotion_map = {
# 积极情绪
"😀": "开心", "😃": "非常开心", "😄": "大笑", "😁": "咧嘴笑",
"😆": "爆笑", "😊": "微笑", "😇": "善良", "🙂": "满意",
"😉": "俏皮", "😌": "安心", "😍": "喜爱", "🥰": "心动",
"😘": "亲吻", "😗": "亲亲", "🥳": "庆祝", "🤗": "拥抱",
"🤩": "惊叹", "🤔": "思考", "🤭": "偷笑", "👍": "赞同",
"👏": "鼓掌", "🙌": "欢呼", "💪": "加油", "👌": "好的",
# 消极情绪
"😞": "失望", "😔": "沮丧", "😟": "担心", "😕": "困惑",
"🙁": "难过", "☹️": "伤心", "😣": "痛苦", "😖": "烦恼",
"😫": "疲惫", "😩": "绝望", "😢": "哭泣", "😭": "大哭",
"😤": "生气", "😠": "愤怒", "😡": "暴怒", "🤬": "咒骂",
"👎": "反对", "💔": "心碎", "😱": "惊恐", "😨": "害怕",
# 中性/其他
"😐": "平淡", "😑": "无语", "😶": "沉默", "😏": "得意",
"😒": "不屑", "🙄": "白眼", "😬": "尴尬", "🤐": "闭嘴",
"🤥": "撒谎", "😴": "睡觉", "😷": "生病", "🤒": "发烧",
# 心形表情
"❤️": "爱心", "🧡": "橙心", "💛": "黄心", "💚": "绿心",
"💙": "蓝心", "💜": "紫心", "🖤": "黑心", "🤍": "白心",
"💕": "双心", "💞": "旋转心", "💓": "心跳", "💗": "成长心",
"💖": "闪亮心", "💘": "箭头心", "💝": "礼物心",
# 常见手势
"✌️": "胜利", "🤞": "交叉手指", "🤟": "摇滚", "🤘": "金属",
"🤙": "给我打电话", "👈": "左边", "👉": "右边", "👆": "向上",
"👇": "向下", "☝️": "向上", "✋": "停", "🤚": "举手",
"🖐️": "张开手", "🖖": "瓦肯手势", "🤲": "祈祷",
# 其他常见表情
"🔥": "火爆", "⭐": "星星", "✨": "闪亮", "💫": "闪耀",
"💥": "爆炸", "💦": "水花", "💨": "风", "🌈": "彩虹",
"☀️": "太阳", "🌙": "月亮", "☁️": "云", "💧": "水滴",
"🌊": "波浪", "🌸": "樱花", "🌺": "花", "🌻": "向日葵",
"🍀": "四叶草", "🌹": "玫瑰", "🍄": "蘑菇", "🌲": "树",
}
# 首先应用我们的自定义映射
for emoji_char, emotion_word in emoji_emotion_map.items():
text = text.replace(emoji_char, f" {emotion_word} ")
# 使用emoji库处理不在自定义映射中的表情符号
try:
# demojize会将emoji转为如":smiling_face_with_heart_eyes:"的形式
text = emoji.demojize(text)
# 清理emoji库生成的格式,移除冒号和下划线,使其更自然
text = re.sub(r':([^:]+):', lambda m: m.group(1).replace('_', ' '), text)
except:
# 如果emoji库不可用,只使用我们的自定义映射
pass
# 清理多余的空格
text = re.sub(r'\s+', ' ', text).strip()
return text
# 应用函数到DataFrame的文本列
df['clean_text'] = df['clean_text'].apply(replace_emojis_with_emotion_words)此解决方案3的优势:
-
保留情感信息:将表情符号转换为对应的情绪词汇,保留了用户评论中的情感色彩,对情感分析任务尤为重要。
-
双重保障机制:
- 首先使用自定义的高质量映射字典,覆盖常见表情符号
- 然后使用emoji库处理其他表情符号,确保全面覆盖
-
格式优化:对emoji库生成的描述进行格式化,移除特殊符号,使文本更自然流畅。
-
空格处理:在替换的词汇周围添加适当空格,确保后续文本处理(如分词)能正确识别这些情绪词。
-
可扩展性:可以轻松扩展emoji_emotion_map字典,添加更多表情符号或调整现有映射的情绪词汇。
使用示例:
原始文本:
"这家餐厅的菜品太棒了!😍服务态度也很好👏,强烈推荐给大家!👍"处理后文本:
"这家餐厅的菜品太棒了! 喜爱 服务态度也很好 鼓掌 ,强烈推荐给大家! 赞同"通过这种方式,我们保留了原始评论中的积极情感,使后续的情感分析模型能够准确捕捉用户的情绪倾向,提高了NLP任务的准确性。
解决方案4:去除无意义的模板化文本
用户评论中常包含一些无意义的模板化文本,如客户端标识、广告语等,这些内容对情感分析没有帮助,反而会引入噪音。
import re
def remove_template_text(text):
"""
去除无意义的模板化文本,如客户端标识、广告语等
参数:
text (str): 原始文本
返回:
str: 去除模板化文本后的结果
"""
# 定义常见的模板化文本模式
template_patterns = [
# 客户端标识
r'——来自[a-zA-Z0-9\u4e00-\u9fa5]+(客户端|App|应用)$',
r'来自[a-zA-Z0-9\u4e00-\u9fa5]+(客户端|App|应用)',
r'[a-zA-Z0-9\u4e00-\u9fa5]+(客户端|App|应用)发布',
r'发布自[a-zA-Z0-9\u4e00-\u9fa5]+(客户端|App|应用)',
# 广告模板
r'广告时间:.*$',
r'赞助内容:.*$',
r'本文为商业推广,.*$',
r'以上内容为广告,.*$',
# 自动生成内容标识
r'系统自动回复',
r'自动回复',
r'机器人回复',
r'AI助手',
# 引用模板
r'回复.*:',
r'引用.*:',
r'@.*:',
# 常见无意义结尾
r'仅供参考$',
r'谢谢观看$',
r'谢谢阅读$',
r'以上仅代表个人观点$',
r'侵删$',
r'图源网络,侵删$',
]
# 应用所有模式进行清理
for pattern in template_patterns:
text = re.sub(pattern, '', text)
# 清理可能产生的多余空格和标点
text = re.sub(r'\s+', ' ', text) # 合并多个空格
text = re.sub(r'([,。!?;:、])\s+', r'\1', text) # 移除标点后的空格
text = text.strip()
# 处理因移除模板文本导致的句末标点缺失
if text and not text[-1] in ',。!?;:、':
text += '。'
return text
# 应用函数到DataFrame的文本列
df['clean_text'] = df['clean_text'].apply(remove_template_text)解决方案4的优势:
-
全面覆盖:涵盖了多种常见的模板化文本类型,包括客户端标识、广告语、自动回复等。
-
正则表达式优化:使用精心设计的正则表达式模式,准确匹配目标文本,避免误删有效内容。
-
后处理机制:清理后自动处理可能产生的格式问题,如多余空格、标点符号缺失等。
-
保留文本完整性:在移除模板文本的同时,确保剩余内容的完整性和可读性。
-
可扩展性:可以轻松添加新的模板模式,适应不同平台和场景的需求。
使用示例:
原始文本:
"这家餐厅的菜品质量很好,环境也不错。——来自iPhone客户端"处理后文本:
"这家餐厅的菜品质量很好,环境也不错。"解决方案5:规范化标点符号和特殊字符
中文文本中常存在全角半角标点混用、特殊符号使用不规范等问题,这会影响文本的一致性和后续NLP处理效果。
import re
import unicodedata
def normalize_punctuation_and_special_chars(text):
"""
规范化标点符号和特殊字符,统一全角半角,处理特殊符号
参数:
text (str): 原始文本
返回:
str: 规范化后的文本
"""
# 全角转半角映射
full_to_half = {
',': ',', '。': '.', '!': '!', '?': '?', ';': ';', ':': ':',
'(': '(', ')': ')', '【': '[', '】': ']', '{': '{', '}': '}',
'《': '<', '》': '>', '、': ',', '·': '.', '…': '...',
'「': '"', '」': '"', '『': '"', '』': '"', '【': '[', '】': ']',
'〖': '[', '〗': ']', '〔': '[', '〕': ']', '〘': '[', '〙': ']',
'〚': '[', '〛': ']', '〜': '~', '•': '*', '‧': '*',
}
# 应用全角转半角映射
for full, half in full_to_half.items():
text = text.replace(full, half)
# 处理特殊Unicode字符和符号
# 保留中文、基本标点、常用符号,其他替换或删除
cleaned_chars = []
for char in text:
# 中文、英文、数字、基本标点
if ('\u4e00' <= char <= '\u9fff') or ('a' <= char <= 'z') or ('A' <= char <= 'Z') or ('0' <= char <= '9'):
cleaned_chars.append(char)
# 基本标点符号
elif char in ' ,.!?;:[]{}()<>"\'-_/\\|@#$%^&*+=~`':
cleaned_chars.append(char)
# 其他情况,根据Unicode类别决定
else:
category = unicodedata.category(char)
# 保留一般标点、货币符号等
if category in ('Po', 'Sc', 'Sm', 'Sk'):
cleaned_chars.append(char)
# 其他特殊字符替换为空格
else:
cleaned_chars.append(' ')
text = ''.join(cleaned_chars)
# 规范化空格
text = re.sub(r'\s+', ' ', text) # 多个空格合并为一个
text = re.sub(r'([,.!?;:])\s+', r'\1 ', text) # 标点后保留一个空格
text = re.sub(r'\s+([,.!?;:])', r' \1', text) # 标点前保留一个空格
text = text.strip()
# 规范化省略号
text = re.sub(r'\.{2,}', '...', text) # 两个或以上点替换为省略号
text = re.sub(r'…+', '...', text) # 多个中文省略号替换为标准省略号
# 规范化引号
text = re.sub(r'"([^"]*)"', r'"\1"', text) # 确保引号配对
return text
# 应用函数到DataFrame的文本列
df['clean_text'] = df['clean_text'].apply(normalize_punctuation_and_special_chars)解决方案5的优势:
-
标点符号统一:将全角标点转换为半角标点,确保文本格式一致性。
-
特殊字符处理:基于Unicode类别智能处理特殊字符,保留有意义的符号,过滤无意义字符。
-
空格规范化:处理文本中的多余空格,确保标点符号周围的空格格式统一。
-
特殊符号处理:专门处理省略号、引号等特殊符号,使其符合标准格式。
-
保留关键信息:在规范化的同时,保留对文本分析有用的货币符号、数学符号等。
使用示例:
原始文本:
"这家餐厅的菜品质量很好,环境也不错!!服务态度超级棒~~~【五星推荐】"处理后文本:
"这家餐厅的菜品质量很好, 环境也不错!! 服务态度超级棒... [五星推荐]"解决方案6:处理数字和日期信息
评论中常包含电话号码、日期、价格等数字信息,这些可能需要特殊处理,以避免对NLP模型产生干扰或提取有用信息。
import re
from datetime import datetime
def normalize_numbers_and_dates(text):
"""
规范化数字和日期信息,处理价格、电话号码、日期等
参数:
text (str): 原始文本
返回:
str: 处理后的文本
"""
# 1. 处理电话号码
# 匹配中国大陆手机号码
phone_pattern = r'1[3-9]\d{9}'
text = re.sub(phone_pattern, '[手机号码]', text)
# 匹配固定电话号码
landline_pattern = r'0\d{2,3}[- ]?\d{7,8}'
text = re.sub(landline_pattern, '[电话号码]', text)
# 2. 处理价格信息
# 匹配人民币价格格式
price_patterns = [
r'\d+元',
r'\d+块',
r'\d+\.?\d*元',
r'\d+\.?\d*块',
r'¥\d+\.?\d*',
r'RMB\s*\d+\.?\d*',
r'人民币\s*\d+\.?\d*',
]
for pattern in price_patterns:
text = re.sub(pattern, '[价格]', text)
# 3. 处理日期信息
# 匹配常见日期格式
date_patterns = [
r'\d{4}[-/年]\d{1,2}[-/月]\d{1,2}[日号]?', # 2023-05-20, 2023年05月20日
r'\d{1,2}[-/月]\d{1,2}[日号]', # 05-20, 5月20日
r'\d{1,2}月\d{1,2}日', # 5月20日
r'\d{4}年', # 2023年
r'(?:周|星期)[一二三四五六七天日]', # 周一, 星期二
r'(?:今|明|前|后|昨)天', # 今天, 明天
r'[上下]午', # 上午, 下午
r'(?:早|中|晚)上', # 早上, 晚上
]
for pattern in date_patterns:
text = re.sub(pattern, '[日期]', text)
# 4. 处理纯数字序列
# 匹配连续数字(长度超过3位)
long_number_pattern = r'\d{4,}'
text = re.sub(long_number_pattern, '[数字]', text)
# 5. 处理百分比
percentage_pattern = r'\d+\.?\d*%'
text = re.sub(percentage_pattern, '[百分比]', text)
# 6. 处理数量词
quantity_patterns = [
r'\d+\s*[个只条张件份片把套台座辆]', # 数量+单位
r'\d+\s*[克千克吨公斤里米厘米毫米]', # 重量/长度单位
r'\d+\s*[秒分时天周月年]', # 时间单位
]
for pattern in quantity_patterns:
text = re.sub(pattern, '[数量]', text)
# 7. 处理年龄信息
age_pattern = r'\d+\s*[岁岁]'
text = re.sub(age_pattern, '[年龄]', text)
# 8. 清理可能产生的多余空格
text = re.sub(r'\s+', ' ', text)
text = text.strip()
return text
# 应用函数到DataFrame的文本列
df['clean_text'] = df['clean_text'].apply(normalize_numbers_and_dates)解决方案6的优势:
-
隐私保护:将电话号码等敏感个人信息替换为通用标记,保护用户隐私。
-
信息规范化:将各种格式的数字和日期信息统一替换为标准化标记,减少模型需要处理的变体。
-
多维度覆盖:全面处理价格、日期、电话号码、百分比、数量等多种数字信息类型。
-
保留语义:通过使用有意义的标记(如[价格]、[日期])而非简单删除,保留了文本的语义结构。
-
模式匹配优化:使用精心设计的正则表达式模式,准确匹配目标数字信息,避免误匹配。
使用示例:
原始文本:
"这家餐厅人均消费150元,我上周五(2023-05-20)去的,联系电话是13812345678,点了3个菜,分量很足,5个人吃刚好。"处理后文本:
"这家餐厅人均消费[价格],我[日期]去的,联系电话是[手机号码],点了[数量]菜,分量很足,[数量]人吃刚好。"解决方案7:处理网络用语和缩写
中文网络评论中常见的网络用语、缩写和拼音缩写,如"yyds"、"xswl"等,这些非标准表达会影响NLP模型的理解。
import re
def normalize_internet_slang(text):
"""
将网络用语和缩写转换为标准表达,提高文本可读性和模型理解能力
参数:
text (str): 原始文本
返回:
str: 处理后的文本
"""
# 创建网络用语到标准表达的映射字典
slang_dict = {
# 常见网络用语
"yyds": "永远的神",
"xswl": "笑死我了",
"zqsg": "真情实感",
"nbcs": "没人关心",
"dbq": "对不起",
"bhys": "不好意思",
"yygq": "阴阳怪气",
"awsl": "啊我死了",
"nsdd": "你说得对",
"ssfd": "笑死",
"djwl": "顶级流量",
"cxk": "蔡徐坤",
"wyf": "吴亦凡",
"xz": "肖战",
"wyb": "王一博",
"gql": "搞清楚",
"xfxy": "腥风血雨",
"yjjc": "一骑绝尘",
"jjyx": "绝绝子",
"yyqx": "易烊千玺",
"xhz": "小欢喜",
"aqy": "爱奇艺",
"txsp": "腾讯视频",
"zj": "周杰伦",
"ldh": "刘德华",
"wjl": "王健林",
"mby": "马云",
"zjl": "周杰伦",
"wsc": "王思聪",
"cyy": "陈奕迅",
"lyf": "刘亦菲",
"zdy": "张艺兴",
"lh": "鹿晗",
"gxt": "关晓彤",
"dlrb": "迪丽热巴",
"zxy": "张学友",
"wym": "王源",
"wy": "王源",
"wjk": "王俊凯",
"yy": "易烊千玺",
"cwt": "陈伟霆",
"hjt": "胡歌",
"lyx": "刘宇宁",
"xnb": "虚拟币",
"zfb": "支付宝",
"wx": "微信",
"qq": "QQ",
"sg": "顺丰",
"yd": "移动",
"dx": "电信",
"lt": "联通",
"bd": "百度",
"xl": "新浪",
"wb": "微博",
"dy": "抖音",
"ks": "快手",
"xhs": "小红书",
"bdj": "百度知道",
"zh": "知乎",
"bilibili": "哔哩哔哩",
"bili": "哔哩哔哩",
"blbl": "哔哩哔哩",
"tb": "淘宝",
"tm": "天猫",
"pdd": "拼多多",
"jd": "京东",
"amz": "亚马逊",
"xhm": "小红帽",
"xlm": "小蓝帽",
"xcm": "小草帽",
"xwh": "小问号",
"xss": "小松鼠",
"xzm": "小芝麻",
"xqe": "小企鹅"最后抛光
完成上述关键步骤后,再用pandas自带的字符串处理方法做一些收尾工作,比如去除多余的空格、统一处理换行符等。
# 去除首尾空格
df['clean_text'] = df['clean_text'].str.strip()
# 将多个空格替换为单个空格
df['clean_text'] = df['clean_text'].str.replace(r'\s+', ' ', regex=True)
# 移除空行或纯空格的行
df.dropna(subset=['clean_text'], inplace=True)
df = df[df['clean_text']!= '']最后,将清洗好的数据保存到/data/processed/processed_reviews.csv。至此,我们得到了一份相对干净、标准化的文本数据,可以进入下一阶段了。
4.人工参与 - 标注与主观性的陷阱
数据清洗干净了,但它们还没有“灵魂”——标签。对于情感分析这种主观性很强的任务,我们需要人工来告诉模型,哪条评论是积极的,哪条是消极的。
选择“兵器”:标注工具
市面上有很多开源的文本标注工具,各有千秋。选择哪个工具,主要看你的任务复杂度和团队规模。
对于我们这个项目,需求很简单:文本三分类。我需要一个安装部署简单、界面清爽、能快速上手的工具。经过一番比较,我最终选择了doccano。
| 工具 | 核心特性 | 部署复杂度 | 适用场景 |
|---|---|---|---|
| doccano | 界面简洁,专注文本任务 | 低 (Docker一行命令搞定) | 快速搭建分类、实体识别项目 |
| Label Studio | 支持多模态 (文本、图像、音频) | 中 (配置项较多) | 复杂、多格式的综合性项目 |
| brat | 擅长关系、语法结构标注 | 中 (需要配置Web服务器) | 语言学、学术研究 |
Label Studio功能强大,但对于我们这个小项目来说有点“杀鸡用牛刀”。
brat更偏学术。而doccano是基于Python Django开发的,对我们这些工程师非常友好,而且用Docker部署简直不要太方便,是新手的绝佳选择。
用Docker搭建标注环境
doccano官方提供了Docker镜像,我们可以用几行命令快速启动一个标注服务实例。
# 从Docker Hub拉取最新的doccano镜像
# GitHub:https://github.com/doccano/doccano
docker pull doccano/doccano
# 创建并运行一个名为doccano的容器
docker container create --name doccano \
-e "ADMIN_USERNAME=admin" \
-e "ADMIN_PASSWORD=password" \
-e "ADMIN_EMAIL=admin@example.com" \
-v doccano-db:/data \
-p 8000:8000 doccano/doccano
# 启动容器
docker container start doccano
# 启动后再查看日志,确认是否正常运行:
docker logs -f doccano这几行命令的意思是:
-
-e:
用于设置环境变量。ADMIN_USERNAME=admin:设置 Doccano 的管理员用户名为admin。ADMIN_PASSWORD=password:设置管理员的登录密码为password。ADMIN_EMAIL=admin@example.com:设置管理员的邮箱地址(必填),系统初始化时会用到。
-
-v doccano-db:/data:
创建一个名为doccano-db的数据卷,并将它挂载到容器的/data目录。
这样容器内的项目配置和标注数据会保存在宿主机上,即使容器被删除,数据也能持久化保存,不会丢失。 -
-p 8000:8000:
将宿主机的 8000 端口 映射到容器的 8000 端口。
这样我们就能通过浏览器访问http://localhost:8000来使用 Doccano 的 Web 界面。 -
--name doccano:
给容器取一个名字doccano,方便后续通过名字来启动、停止或查看容器,而不用记复杂的容器 ID。 -
doccano/doccano:
指定要运行的镜像,这里使用的是 Doccano 官方提供的镜像。 -
docker container start doccano:
启动刚刚创建的doccano容器。 -
docker logs -f doccano:
实时查看容器日志,确认服务是否正常运行,并检查是否有报错。
命令执行成功后,在浏览器访问http://localhost:8000,就能看到doccano的登录界面了。登录后,创建一个新项目,项目类型选择“Text Classification”,然后把我们之前清洗好的processed_reviews.csv文件导入进去,就可以开始标注了。
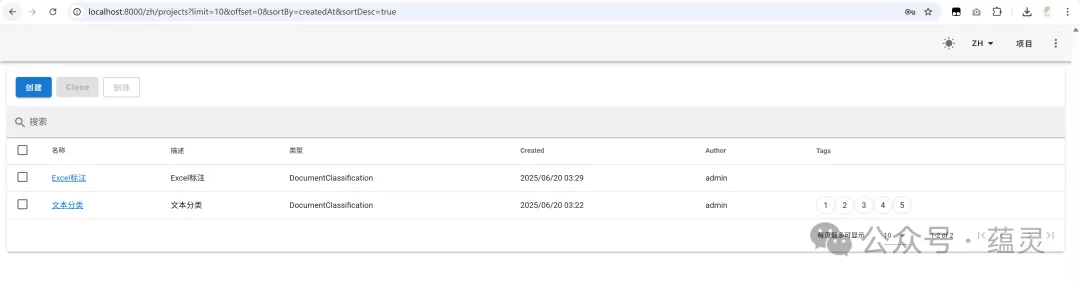
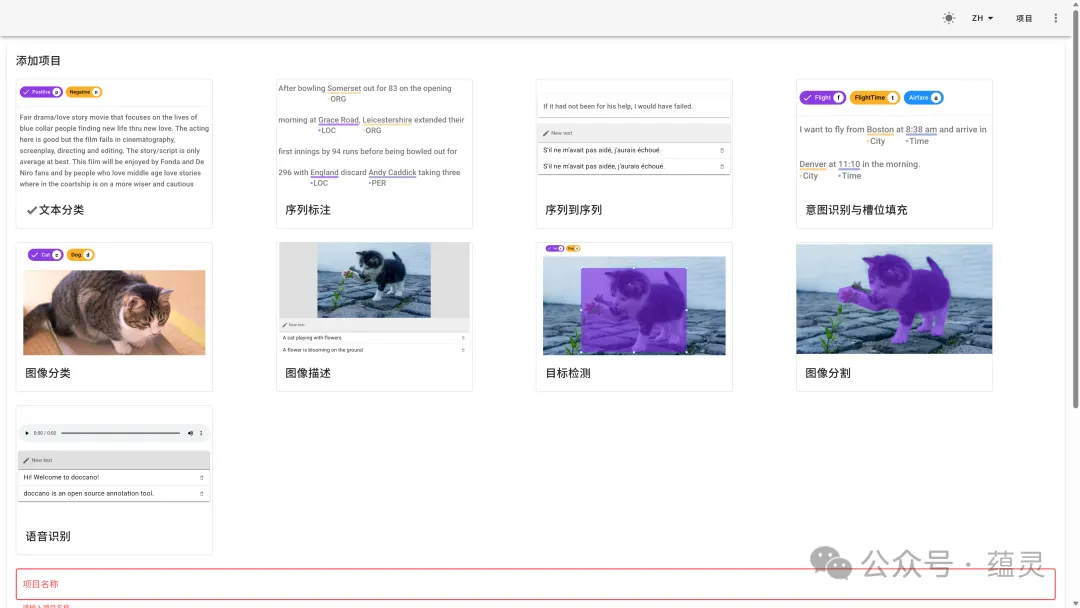
踩坑:“你说这个算反讽,我觉得是中性”
我拉上组里一个实习生小哥,准备两人合力把这2万条数据标完。我们各自领了任务,埋头苦干。标了大概100条之后,我俩对了下进度,顺便抽查了几条。结果发现,分歧相当大。
比如这条评论:“上菜速度真是‘快’啊,呵呵,我们等了40分钟才给上一杯水。” 我标的是消极,因为这明显是反讽。但小哥犹豫了半天,觉得虽然有抱怨但也有陈述事实,就标了中性/建议。
这就是人工标注最大的坑:人的主观性。如果没有一个统一、明确的标准,不同的人对同一条数据的理解可能天差地别。用这样充满噪声的标签训练出来的模型,效果可想而知。
解决方案1:制定“法律”——标注指南
高质量的标签不是靠工具本身,而是靠一套高质量的、无歧义的规则。这份规则,就是标注指南 (Annotation Guideline)。它是整个标注环节中最重要的文档,是所有标注员的“最高指示”。
一份好的指南,至少要回答三个问题:为什么标?标什么?怎么标?特别是要包含大量正反案例,以及对模棱两可情况的明确裁决。
下面是我们经过讨论后制定的部分指南,供参考:
| 标签 | 定义 | 明确案例 | 模糊案例处理 |
|---|---|---|---|
| 积极 | 明确表达对菜品、服务、环境的满意。 | “菜品味道很好,环境也安静。” | “还行吧。” -> 标为中性/建议。避免将弱赞美标为积极。 |
| 消极 | 明确表达不满、抱怨或失望。 | “服务员态度太差了,等了半小时才点上菜。” | “上菜速度真是‘快’啊,呵呵。” -> 标为消极。将明确的反讽视为消极情绪。 |
| 中性/建议 | 陈述事实、提问或不带强烈情绪的建设性意见。 | “他家车位比较紧张,建议早点去。” | “要是能多点辣菜就好了。” -> 标为中性/建议。这是反馈,而非抱怨。 |
解决方案2:量化一致性 (理智检查)
光有指南还不够,我们还需要一个方法来衡量大家是否真的在遵守指南。这个方法就是计算标注者间一致性 (Inter-Annotator Agreement, IAA)。
最常用的指标是科恩卡帕系数 (Cohen's Kappa)。你不需要深究它的复杂公式,只需要理解它的核心思想:它衡量了两个标注员的意见一致程度,并且剔除了“瞎蒙也能蒙对”的概率成分。Kappa值范围在-1到1之间,通常认为0.7以上算比较好的一致性。
我们的工作流变成了这样:
- 两个人同时标注一小批相同的数据(比如100条)。
- 用脚本计算这100条数据的Kappa值。
- 如果值很低(比如低于0.6),就找出所有不一致的标注,坐下来一起复盘,讨论分歧点,然后更新我们的标注指南。
- 重复以上步骤,直到Kappa值稳定在一个比较高的水平(比如0.8左右)。
这个迭代优化的过程虽然耗时,但对保证最终数据集的质量至关重要。
5.完成资产最终处理 - 格式化、质检与版本管理
经过几轮的“磨合”,我们终于完成了所有数据的标注。现在,是时候把这份来之不易的成果打包成一个专业的、可用的“数据资产”了。
导出与格式化
在doccano里,我们可以很方便地将标注好的数据导出。我选择的导出格式是JSON Lines (.jsonl)。
JSON Lines格式很简单,就是一个文本文件,每一行都是一个独立的、完整的JSON对象。对于NLP任务,尤其是使用Hugging Face生态的工具时,这是一种非常流行和高效的格式。
为什么不用一个大的JSON文件呢?因为JSON Lines格式支持流式读写。处理一个10GB的单体JSON文件,你需要把它全部加载到内存里才能解析,非常消耗资源。而JSON Lines文件可以一行一行地读取和处理,内存占用极小,对大规模数据处理非常友好。
导出的sentiment_dataset.jsonl文件内容大概是这样:
{"text": "菜品味道很好,环境也安静。", "label": "积极"}
{"text": "服务员态度太差了,等了半小时才点上菜。", "label": "消极"}
{"text": "他家车位比较紧张,建议早点去。", "label": "中性/建议"}最后的质检 (程序化QA)
在宣布大功告成之前,我会用程序对导出的标注文件做最后一次“体检”。这一步能发现一些人工标注时可能忽略的低级错误。
我写了一个简单的Python脚本,用pandas来做以下检查:
- 检查是否有
text或label字段缺失的行。 - 检查
text字段是否为空字符串。 - 统计并打印最终的标签分布。看看是否存在严重的类别不平衡问题,这对后续的模型训练策略至关重要。
- 检查
label字段中是否出现了预定义(积极,消极,中性/建议)之外的“非法”标签(比如手滑打错了字)。
踩坑:dataset_final_v3_reviewed_fixed.jsonl
项目进行到这里,很容易出现一个灾难性的场景:你的文件夹里堆满了sentiment_dataset_v1.jsonl、sentiment_dataset_v2_fix.jsonl、sentiment_dataset_final_final.jsonl……时间一长,你自己都搞不清哪个版本对应哪个实验,哪个模型是用哪个数据训练的了。
这说明,数据和代码一样,需要进行严格的版本控制。Git擅长管理代码(文本文件),但对于动辄几百MB甚至上GB的数据文件,它就力不从心了。强行用Git LFS也行,但有更专业的工具。
解决方案:用DVC进行专业版本管理
DVC (Data Version Control) 是一个专门为机器学习项目设计的数据和模型版本控制工具。它和Git无缝集成,基本工作流程是:
- 用DVC追踪你的数据文件。
- DVC会生成一个很小的元数据文件(
.dvc文件),这个文件里包含了数据的哈希值等信息。 - 你把这个小小的
.dvc文件提交到Git里。 - 而真实的数据文件,则被DVC上传到一个远程存储(比如S3、SSH服务器,甚至本地文件夹)里。
这样一来,你的Git仓库保持轻量,同时又完整地记录了每个代码版本所对应的数据版本,实现了真正的可复现性。
下面是DVC的核心命令流,非常简单:
# 在你的Git项目根目录下初始化DVC
dvc init
# 添加远程存储,这里用一个本地文件夹做演示
mkdir -p /tmp/dvc_storage
dvc remote add -d myremote /tmp/dvc_storage
# 用DVC追踪你的数据集文件
dvc add data/annotated/sentiment_dataset.jsonl
# 现在,把生成的.dvc文件和.gitignore的修改提交到Git
git add data/annotated/sentiment_dataset.jsonl.dvc data/annotated/.gitignore
git commit -m "Add annotated sentiment dataset v1.0"
# 将数据推送到远程存储
dvc push(小提示:dvc add适合用来追踪那些“源数据”,比如你从外部获取的原始数据或标注好的数据。而dvc stage add则更强大,它可以定义一个数据处理步骤,把输入、输出和执行的命令都记录下来,形成一个可复现的流水线。可以理解为dvc add是给“食材”建档,而dvc stage add是把“菜谱和做出来的菜”一起记录下来。)
创建可复现的数据集切分
训练模型前的最后一步,是把数据集切分成训练集、验证集和测试集。这里用scikit-learn的train_test_split函数。
有一个参数极其重要,但新手很容易忽略,那就是stratify。在我们的质检步骤中,我们已经知道了标签的分布。如果某个类别的样本非常少,随机切分很可能导致训练集或测试集中该类别的样本过少甚至没有,这会严重影响模型的训练和评估。stratify=y参数能保证切分后的每个子集都保持和原始数据集相同的类别比例,这对于处理类别不均衡的数据集来说是“救命稻草”。
from sklearn.model_selection import train_test_split
import pandas as pd
# 假设df已经从jsonl加载
df = pd.read_json('data/annotated/sentiment_dataset.jsonl', lines=True)
X = df['text']
y = df['label']
# 切分训练集和测试集 (80/20)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# 可以在训练集中再切分出验证集
X_train, X_val, y_train, y_val = train_test_split(
X_train, y_train, test_size=0.1, random_state=42, stratify=y_train # test_size=0.1 of 80% is 8%
)
print(f"训练集大小: {len(X_train)}")
print(f"验证集大小: {len(X_val)}")
print(f"测试集大小: {len(X_test)}")6. 最终数据展示
经过前面几步的搜集、清洗和标注,我们终于得到了一个可用于训练农家乐情感分析模型的初版数据集。这里展示一下结果,让大家对数据的形态和规模有一个直观印象。
数据规模
- 原始评论数:约 12,000 条
- 清洗后可用评论:9,800 条
- 最终标注完成评论:9,500 条
类别分布
- 积极:5,100 条(53.7%)
- 消极:2,700 条(28.4%)
- 中性/建议:1,700 条(17.9%)
示例数据
| 评论文本 | 标签 |
|---|---|
| “老板娘特别热情,烤鱼味道一绝!” | 积极 |
| “环境一般,菜上得太慢了,下次不会再来了。” | 消极 |
| “建议多准备点停车位,节假日真的不够用。” | 中性/建议 |
可视化(类别分布饼图)
积极 ██████████████████████████ 53.7%
消极 ██████████ 28.4%
中性 ████ 17.9%(实际项目中可以用 matplotlib 或 seaborn 绘制更美观的图表)
import matplotlib.pyplot as plt
# 使用英文避免中文乱码
labels = ["Positive", "Negative", "Neutral/Suggestion"]
sizes = [5100, 2700, 1700]
colors = ["#66c2a5", "#fc8d62", "#8da0cb"]
explode = (0.05, 0.05, 0.05)
plt.figure(figsize=(6, 6))
plt.pie(sizes, labels=labels, autopct='%1.1f%%', startangle=140,
colors=colors, explode=explode, shadow=True, textprops={'fontsize': 12})
plt.title("Sentiment Distribution of Agritainment Reviews", fontsize=14)
plt.tight_layout()
plt.show()通过这个阶段,数据终于达到了可用的形态,也能为后续的模型训练提供扎实的基础。
7.一点感想
从最初的无从下手,到最后拿到一个能看得见、用得上的数据集,这一路其实挺“反常识”的。很多人以为做机器学习,核心是模型、是算法,但这次亲身实践让我更加确信:数据才是地基,模型只是盖在上面的房子。
在收集和清洗评论的过程中,我踩过不少坑:网站的反爬机制、评论里的表情符号和乱码、标注时的歧义……这些问题单独看都不算难,但当它们叠加到一起,就成了真正考验耐心和细致程度的“大工程”。
最终数据集出来时,看着那张积极、消极、中性的分布饼图,心里会有种奇妙的踏实感——这些冰冷的评论文本,终于被我们加工成了能驱动模型的“燃料”。模型准确率能不能再高几个百分点,已经不那么重要了。至少在这个项目里,我更看重的是如何把数据这件事做扎实。
所以,最后留一句送给刚入门或者正在摸索的同学们:别小看那些“繁琐”的环节,很多时候决定项目成败的,就是这些看似不起眼的细节。