线程安全的集合总览
集合框架体系总览
讲线程安全的集合之前我觉得有必要回顾下整个 Java 集合框架的体系,不过由于不是本专栏的核心内容,所以这里我就简单介绍下哈,不了解的各位可以看这里:Java 集合框架体系总览
与现代的数据结构类库的常见情况一样,Java 集合类也将接口与实现分离,这些接口和实现类都位于 java.util 包下。按照其存储结构集合可以分为两大类:
- 单列集合 Collection
- 双列集合 Map
Collection 接口
单列集合 java.util.Collection:元素是孤立存在的,向集合中存储元素采用一个个元素的方式存储。

来看 Collection 接口的继承体系图:
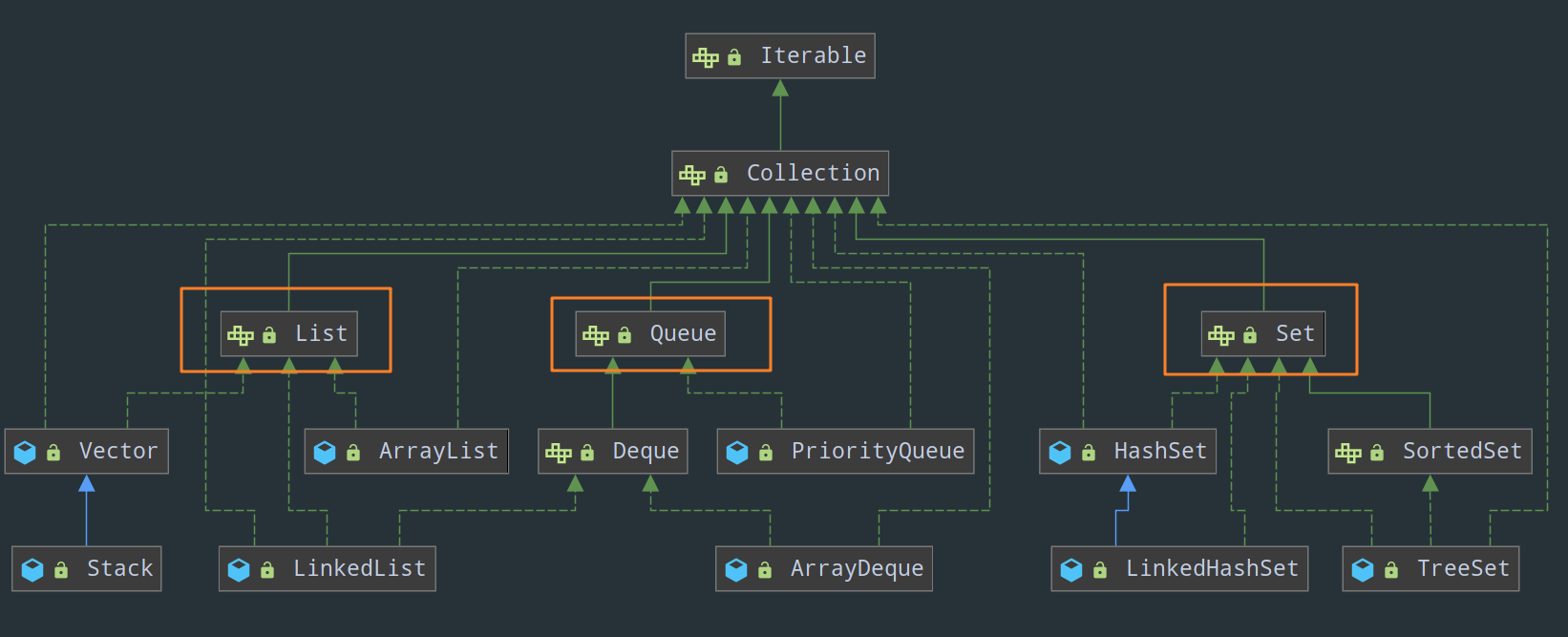
Collection 有三个子接口,分别是 List、Set 和 Queue,它们分别代表了有序集合、无序集合和队列:
1)List 的特点是元素有序、可重复。注意,这里所谓有序的意思,并不是指集合中按照元素值的大小进行有序排序,而是说,List 会按照元素添加的顺序来进行存储,保证插入的顺序和存储的顺序一致。
List 接口的常用实现类有:
- ArrayList:底层数据结构是数组,线程不安全
- LinkedList:底层数据结构是链表,线程不安全
2)Set 接口在方法签名上与 Collection 接口其实是完全一样的,只不过在方法的说明上有更严格的定义,最重要的特点是他拒绝添加重复元素,不能通过整数索引来访问,并且元素无序。同样的,所谓无序也就是指 Set 并不会按照元素添加的顺序来进行存储,插入的顺序和存储的顺序是不一致的。其常用实现类有:
- HashSet:底层基于
HashMap实现,采用HashMap来保存元素 - LinkedHashSet:
LinkedHashSet是HashSet的子类,并且其底层是通过LinkedHashMap来实现的。
3)Queue 这个接口其实用的不多,可以把队列看作一种遵循 FIFO 原则的特殊线性表(事实上,LinkedList 也确实实现了 DeQueue 接口),Queue 接口是单向队列,而 DeQue 接口继承自 Queue,它是双向队列。
Map 接口
双列集合 java.util.Map:元素是成对存在的。每个元素由键(key)与值(value)两部分组成,通过键可以找对所对应的值。显然这个双列集合解决了数组无法存储映射关系的痛点。另外,需要注意的是,Map 不能包含重复的键,值可以重复;并且每个键只能对应一个值。

来看 Map 接口的继承体系图:
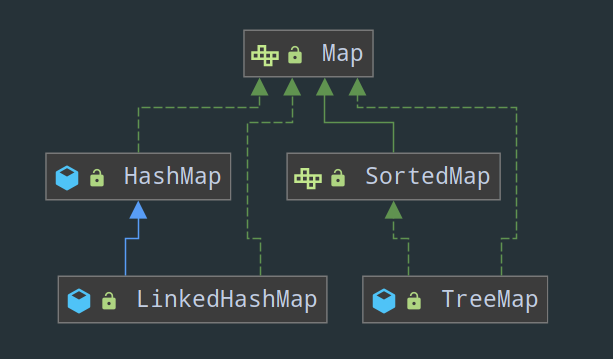
Map 有两个重要的实现类,HashMap 和 LinkedHashMap :
① HashMap:可以说 HashMap 不背到滚瓜烂熟不敢去面试,这里简单说下它的底层结构吧。JDK 1.8 之前 HashMap 底层由数组加链表实现,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法” 解决冲突)。JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树,以减少搜索时间(注意:将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)。
② LinkedHashMap:HashMap 的子类,可以保证元素的存取顺序一致(存进去时候的顺序是多少,取出来的顺序就是多少,不会因为 key 的大小而改变)。
LinkedHashMap 继承自 HashMap,所以它的底层仍然是基于拉链式散列结构,即由数组和链表或红黑树组成。另外,LinkedHashMap 在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。
线程不安全集合的表现
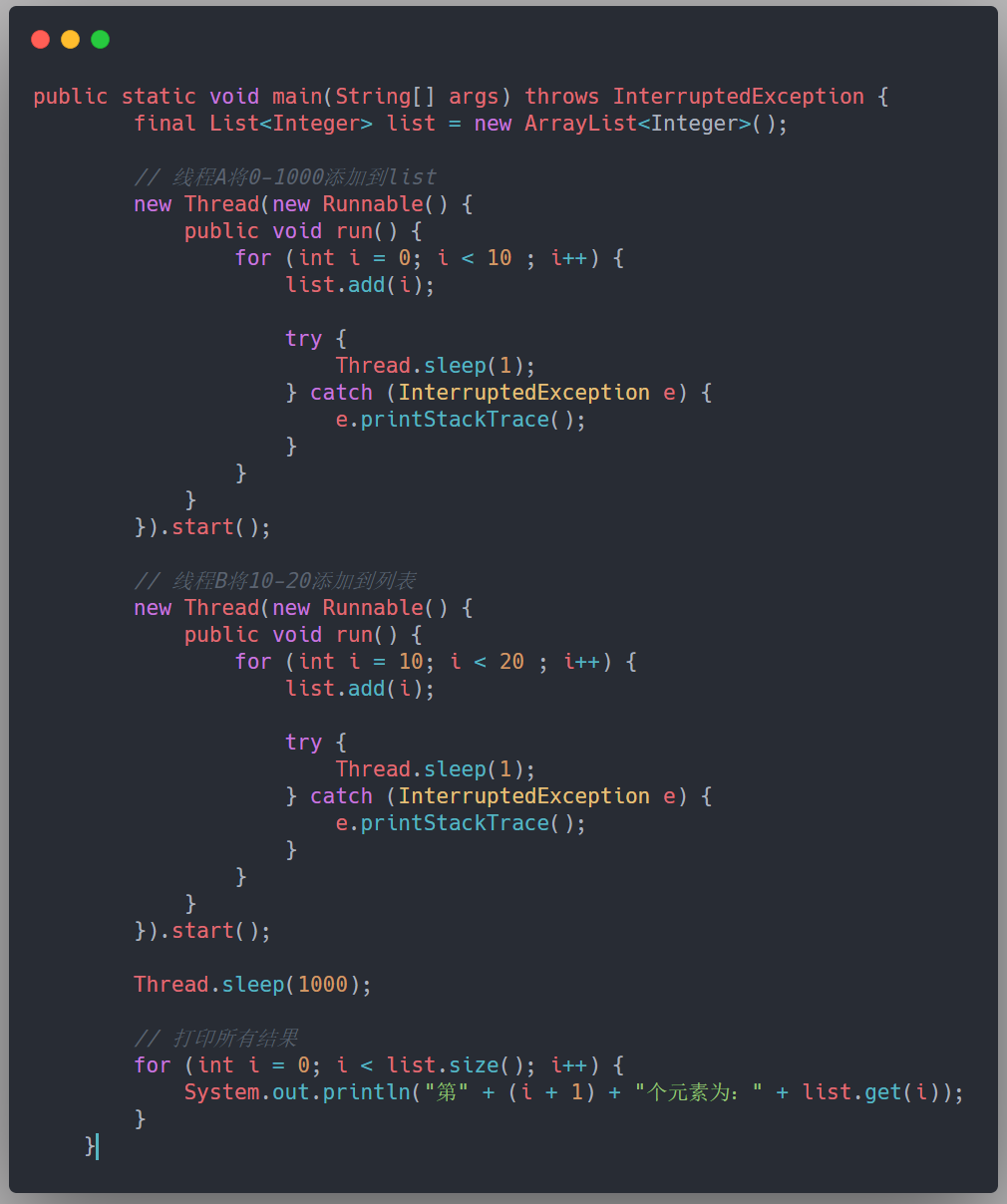
什么是线程安全的集合,什么是线程不安全的集合,有些同学可能还没有一个非常清楚的认知,这里我以比较常见的 ArrayList 来解释下,为什么 ArrayList 是线程不安全的,以在末尾添加元素的 add 方法为例:

黄色框里的并不是一个原子操作,它由两步操作构成:
elementData[size] = e;
size = size + 1;在单线程执行这两条代码时,那当然没有任何问题,但是当多线程环境下执行时,可能就会发生一个线程添加的值覆盖另一个线程添加的值。举个例子:
- 假设 size = 0,我们要往这个数组的末尾添加元素
- 线程 A 开始添加一个元素,值为 A。此时它执行第一条操作,将 A 放在了数组 elementData 下标为 0 的位置上
- 接着线程 B 刚好也要开始添加一个值为 B 的元素,且走到了第一步操作。此时线程 B 获取到的 size 值依然为 0,于是它将 B 也放在了 elementData 下标为 0 的位置上
- 线程 A 开始增加 size 的值,size = 1
- 线程 B 开始增加 size 的值,size = 2
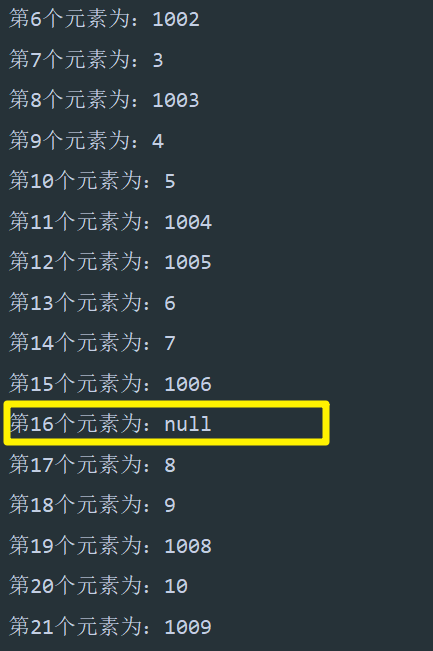
这样,线程 A、B 都执行完毕后,理想的情况应该是 size = 2,elementData[0] = A,elementData[1] = B。而实际情况变成了 size = 2,elementData[0] = B(线程 B 覆盖了线程 A 的操作),下标 1 的位置上什么都没有。并且后续除非我们使用 set 方法修改下标为 1 的值,否则这个位置上将一直为 null,因为在末尾添加元素时将会从 size = 2 的位置上开始。
上段代码验证下:
结果和我们分析的一样:
线程安全的集合总览
J.U.C 为每一类集合都提供了线程安全的实现,等会往下看各位就会发现很多线程安全的集合都是以 Concurrent 或者 CopyOnWrite 开头的。这里先给大家解释下:
以 Concurrent 开头的集合类通常采用某些比较复杂的算法(以 ConcurrentHashMap 为首,相信各位八股文都已经背恶心了)来保证永远不会锁住整个集合,因此在并发写入时有较好的性能。
而以 CopyOnWrite(COW)开头的集合类采用了 写时复制 的思想来支持并发读。
具体来说,就是我们往一个 COW 集合中添加元素的时候,底层并不是直接向当前的集合中添加,而是先将当前的集合 copy 出一个新的副本,然后在这个副本李添加元素,添加完元素之后,再将原集合的引用指向这个副本。这样做的好处是我们可以对 COW 集合进行并发的读,而不需要执行加锁操作。
所以,CopyOnWrite 集合其实是一种读写分离的集合。
下面我们来捋一下具体都有哪些线程安全的集合:
Collection 接口
1)List:
Vector(这个没啥好说的,它就是把 ArrayList 中所有的方法统统加上synchronized)CopyOnWriteArrayList
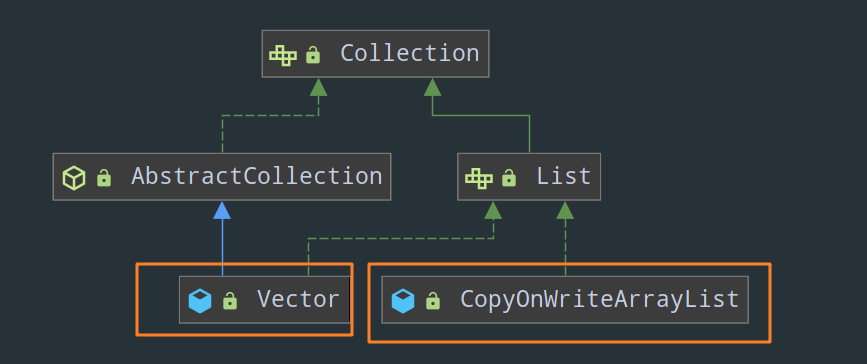
2)Set:
CopyOnWriteArraySetConcurrentSkipListSet
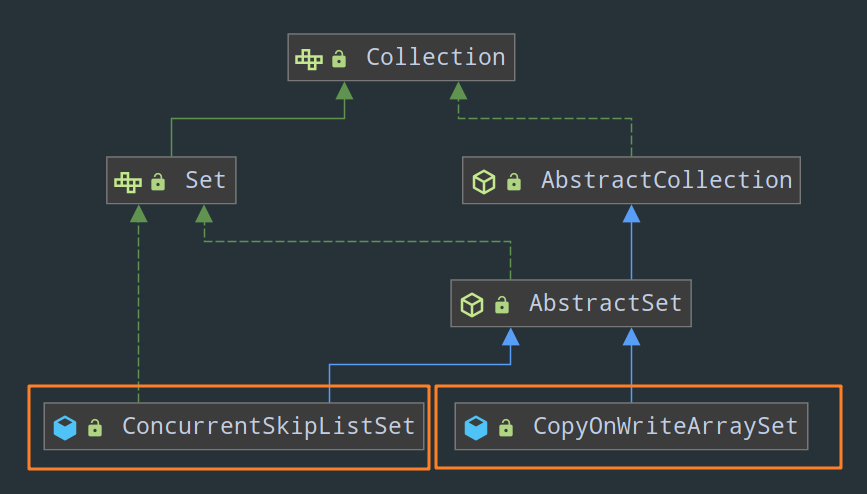
3)Queue:
- BlockingQueue 接口
LinkedBlockingQueueDelayQueuePriorityBlockingQueueConcurrentLinkedQueue
- TransferQueue 接口
LinkedTransferQueue
- BlockingDeque 接口
LinkedBlockingDequeConcurrentLinkedDeque
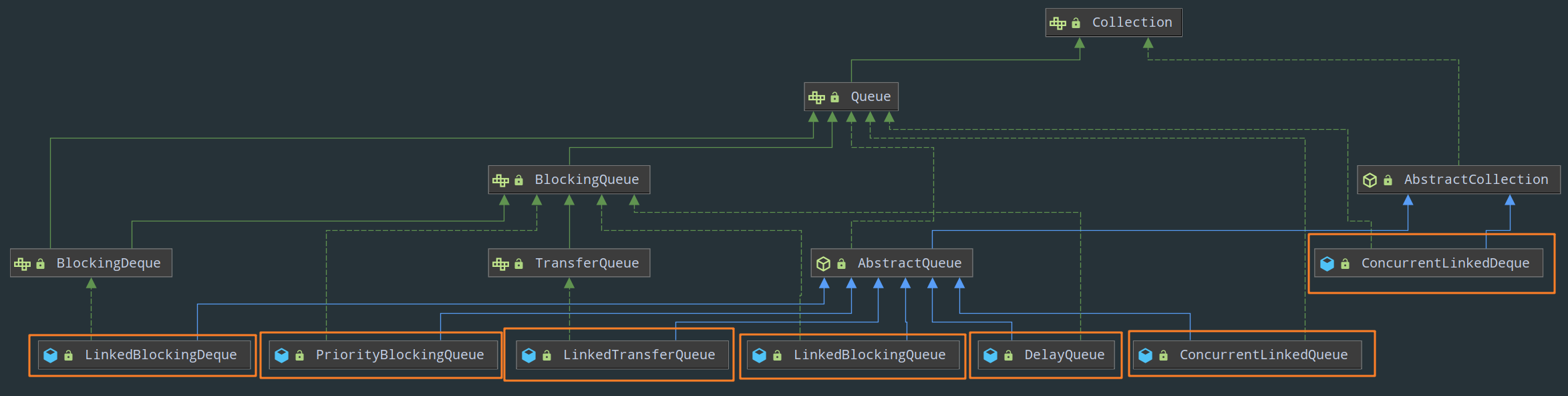
来一张 Collection 接口下线程安全集合的全家福:

Map 接口
- HashTable(这个有一些细节需要注意,可以看这里 Hashtable 渐渐被人们遗忘了,只有面试官还记得,不过在线程安全方面其实也没啥好说的,就是把 HashMap 中所有的方法统统加上
synchronized) - ConcurrentMap 接口
ConcurrentHashMapConcurrentSkipListMap
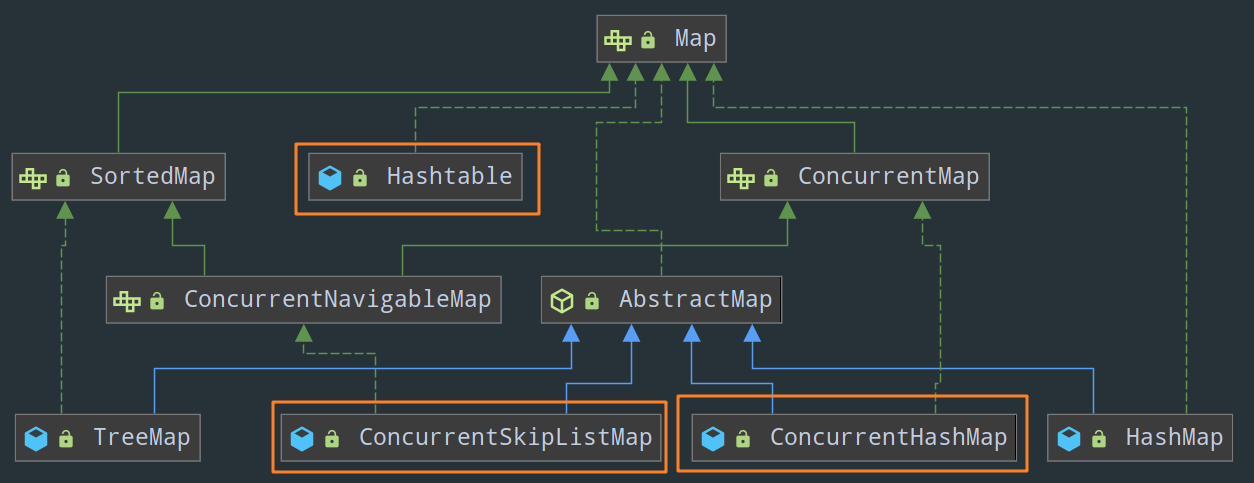
ConcurrentHashMap 这套八股不得背个十来遍?
关于 HashMap 的线程不安全性以及线程安全的 HashTable 的局限性,本文就不作详细解释了,具体可以看这两篇文章:HashMap 这套八股,不得背个十来遍? 和 Hashtable 渐渐被人们遗忘了,只有面试官还记得
在高并发的情况下,开发常用的一般都是 ConcurrentHashMap,和 HashMap 一样,其 JDK 1.7 版本和 JDK 1.8 版本的底层实现略有不同。我们先从经典的 JDK 1.7 开始讲起
JDK 1.7
ConcurrentHashMap 其实几句话就能说明白,你要是不信,你就往下看我给你讲两句:
第一句:ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成
第二句:Segment 继承自 ReentrantLock,是一种可重入锁;其中,HashEntry 是用于真正存储数据的地方
static final class Segment<K,V> extends ReentrantLock implements Serializable {
// 真正存放数据的地方
transient volatile HashEntry<K,V>[] table;
// 键值对数量
transient int count;
// 阈值
transient int threshold;
// 负载因子
final float loadFactor;
Segment(float lf, int threshold, HashEntry<K,V>[] tab) {
this.loadFactor = lf;
this.threshold = threshold;
this.table = tab;
}
}其实这里的 HashEntry 和 HashMap 中的 HashEntry 是一样的,每个 HashEntry 是一个链表结构的元素,其成员变量包含 key、value、hash 值以及下一个节点:
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
}可以看到,value 用 volatile 修饰起来了,用于保证数据的可见性
第三句:一个 ConcurrentHashMap 包含一个 Segment 数组,一个 Segment 里包含一个 HashEntry 数组,当对某个 HashEntry 数组中的元素进行修改时,必须首先获得该元素所属 HashEntry 数组对应的 Segment 锁
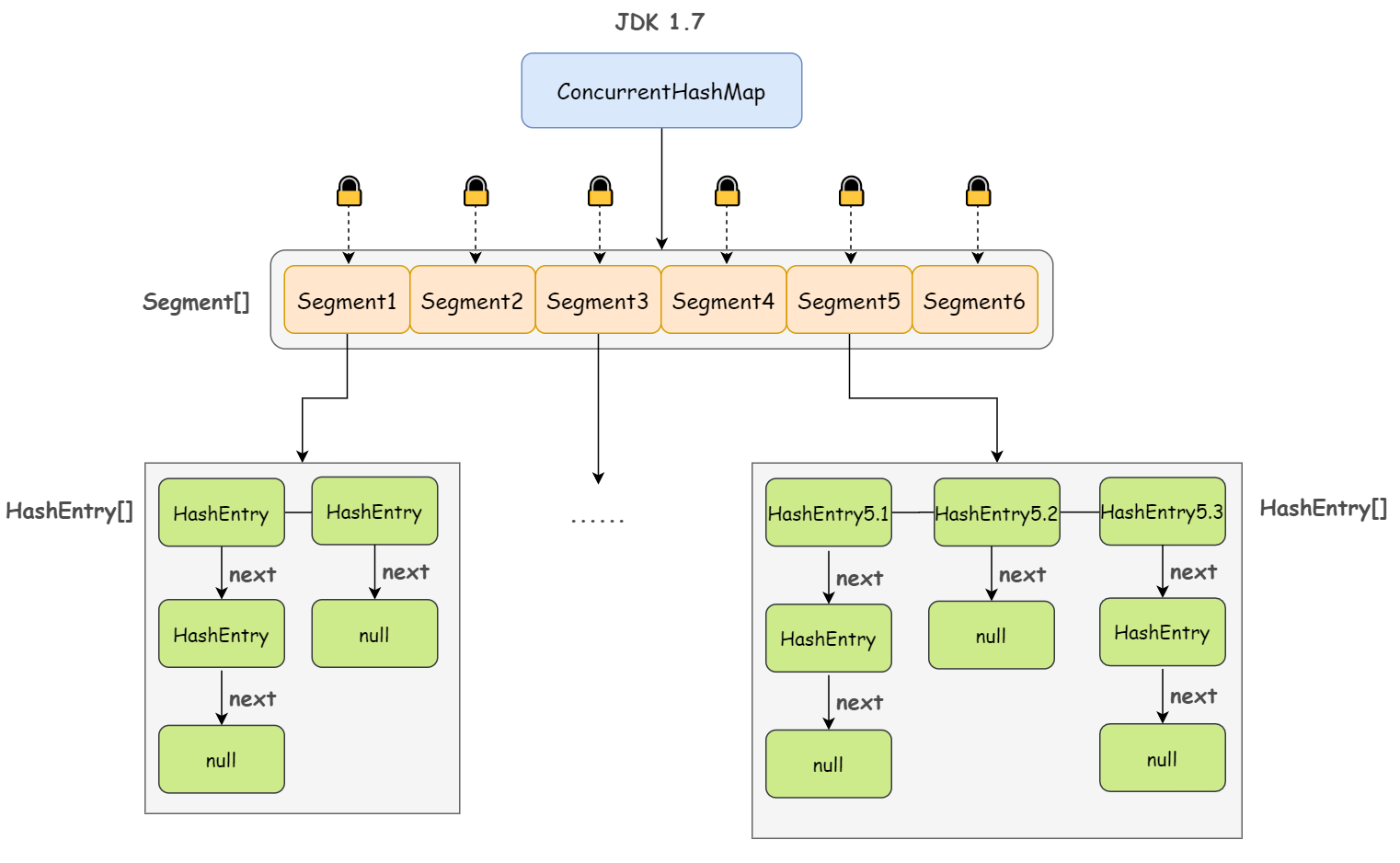
如此,JDK 1.7 版本下的 ConcurrentHashMap 的线程安全性其实已经跃然纸上了,简单来说:
ConcurrentHashMap 采用分段锁(Segment 数组,一个 Segment 就是一个锁)技术,每当一个线程访问 HashEntry 中存储的数据从而占用一个 Segment 锁时,并不会影响到其他的 Segment,也就是说,如果 Segment 数组中有 10 个 元素,那理论上是可以允许 10 个线程同时执行的。
put
来看它的 put 操作
首先,既然 ConcurrentHashMap 使用分段锁 Segment 来保护不同段的数据,那么在插入和获取元素的时候,必须先通过 Hash 算法定位到 Segment:
事实上,这里会对元素的 hashCode 进行一次再 hash,其目的就是减少 hash 冲突,使元素能够均匀地分布在不同的 Segment 上,从而提高容器的存取效率。毕竟如果散列的质量非常差的话,分段锁也就失去意义了。
public V put(K key, V value) {
Segment<K,V> s;
// 1. 通过 key 定位到具体的 Segment
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject
(segments, (j << SSHIFT) + SBASE)) == null)
s = ensureSegment(j);
// 在对应的 Segment 中进行真正的 put
return s.put(key, hash, value, false);
}然后在对应的 Segment 中进行真正的 put:
1)尝试获取锁,如果获取失败则利用 scanAndLockForPut() 进行自旋
2)遍历该 HashEntry 数组:
- 如果当前遍历到的 HashEntry 不为空则判断传入的 key 和当前遍历到的 key 是否相等,相等则覆盖旧的 value
- 为空则新建一个 HashEntry 并加入到 Segment 中(先判断是否需要对 Segment 数组进行扩容)
3)释放锁
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 1. 尝试获取锁,如果获取失败则利用 scanAndLockForPut() 进行自旋
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
// 2. 遍历该 HashEntry
for (HashEntry<K,V> e = first;;) {
// 2.1 如果不为空则判断传入的 key 和当前遍历的 key 是否相等,相等则覆盖旧的 value。
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
// 2.2 为空则新建一个 HashEntry 并加入到 Segment 中
else {
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
// 先判断是否需要扩容
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
// 3. 释放锁
unlock();
}
return oldValue;
}简单总结一下,put 方法首先定位到 Segment,尝试获取锁,如果失败则自旋。然后在 Segment 里进行插入操作,插入操作需要经历两个步骤,第一步判断是否需要对 Segment 里的 HashEntry 数组进行扩容,第二步定位添加元素的位置,然后将其放在 HashEntry 数组里。
get
get 就更简单了,效率也非常高,因为整个过程都不需要加锁:
1)将 Key 通过 Hash 定位到具体的 Segment
2)再通过一次 Hash 定位到具体的元素上
public V get(Object key) {
Segment<K,V> s;
HashEntry<K,V>[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
// 1. 通过 Hash 定位到具体的 Segment
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
// 再通过一次 Hash 定位到具体的元素上
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}小结
总结下 JDK 1.7 版本下的 ConcurrentHashMap,其实就是数组(Segment 数组) + 链表(每个 HashEntry 是链表结构),存在的问题也很明显,和 HashMap 一样,那就是 get 的时候都需要遍历链表,效率实在太低。
So,JDK 1.8 做了一些结构上的小调整
JDK 1.8
不同于 JDK 1.7 版本的 Segment 数组 + HashEntry 链表,JDK 1.8 版本中的 ConcurrentHashMap 直接抛弃了 Segment 锁,一个 ConcurrentHashMap 包含一个 Node 数组(和 HashEntry 实现差不多),每个 Node 是一个链表结构,并且在链表长度大于一定值时会转换为红黑树结构(TreeBin)。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
Node(int hash, K key, V val, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}TreeBin 节点继承自 Node:

我们大概可以画出这样的图:
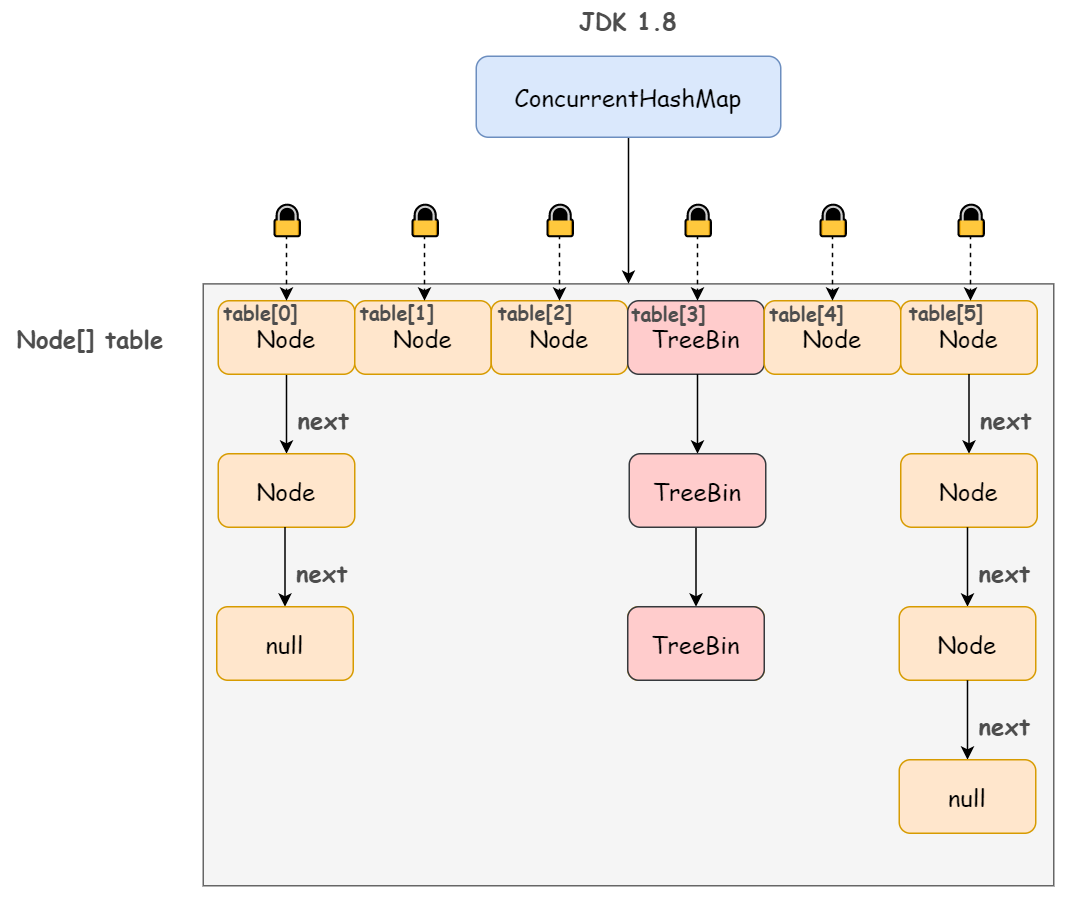
那既然没有使用分段锁,如何保证并发安全性的呢?
synchronized + CAS!
简单来说,Node 数组其实就是一个哈希桶数组,每个 Node 头节点及其所有的 next 节点组成的链表就是一个桶,只要锁住这个桶的头结点,就不会影响其他哈希桶数组元素的读写。桶级别的粒度显然比 1.7 版本的 Segment 段要细。
这里我多说一嘴,JDK 1.8 没有使用 ReentrantLock 而是改用 synchronized,足以说明新版 JDK 对 synchronized 的优化确有成效。
put
来看 put 方法,实际上是调用了 putVal:
1)根据要 put 数据的 key 计算出 hashcode
2)遍历 table 数组,根据 hashcode 定位 Node:
- 如果 Node 为空表示当前位置可以写入数据,利用 CAS 尝试写入(失败则自旋)
- 如果当前位置的 hashcode == MOVED == -1,则需要对 Node 数组进行扩容
- 如果 Node 不为空并且也不需要进行扩容,则利用 synchronized 锁写入数据
final V putVal(K key, V value, boolean onlyIfAbsent) {
// 根据 key 计算出 hashcode
int hash = spread(key.hashCode());
int binCount = 0; // 链表长度
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// f 为当前 key 定位出的 Node
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 如果 Node 为空表示当前位置可以写入数据,利用 CAS 尝试写入(失败则自旋)
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break;
}
// 如果当前位置的 hashcode == MOVED == -1,则需要对 Node 数组进行扩容
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
// 如果 Node 不为空并且也不需要进行扩容,则利用 synchronized 锁写入数据
else {
V oldVal = null;
synchronized (f) {
// 省略......
}
if (binCount != 0) {
// 如果链表长度大于 TREEIFY_THRESHOLD,则要将链表转换为红黑树
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}get
get 代码我就不贴了,比较简单,三步走:
1)根据 key 对应 hashcode 找到对应的桶,如果正好是桶的头节点,则直接返回值
2)如果不是桶的头节点,并且是红黑树结构,那就按照树的方式去查找值
3)如果既不是桶的头节点,也不是红黑树结构,那就按照链表的方式去查找值(也就是遍历)
阻塞队列知多少
什么是阻塞队列
什么是阻塞队列?
很好理解:“阻塞” + “队列”
队列是一种先进先出的数据结构,和阻塞这个特性相结合起来,通俗来讲就是 “阻塞进 + 阻塞出”
1)所谓 “阻塞进”,就是说,当队列满时,队列会阻塞向其中插入元素的线程,直到队列不满
2)而所谓 ”阻塞出“,指的是,当队列为空时,获取队列中元素的线程会一直等待,直到队列变为非空
阻塞队列最常见的应用场景,莫过于生产者-消费者模式,生产者把产品放到阻塞队列(缓冲池)中,消费者从阻塞队列中获取产品,当队列满时,生产者阻塞,当队列空时,消费者阻塞。
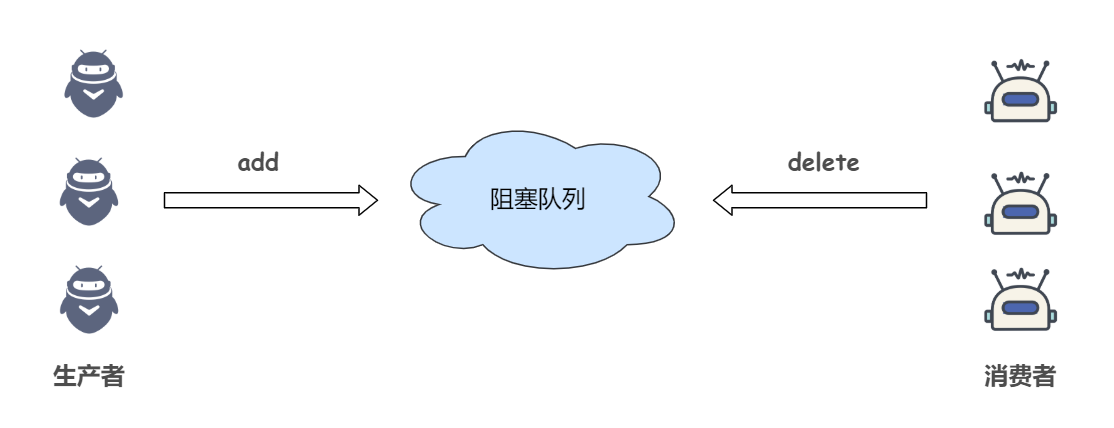
Java 中的阻塞队列 BlockingQueue
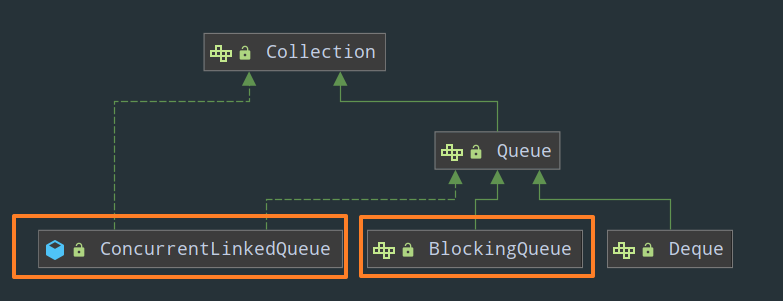
毫无疑问,阻塞队列既然属于队列,那在 Java 中一定是 Queue 的子类。
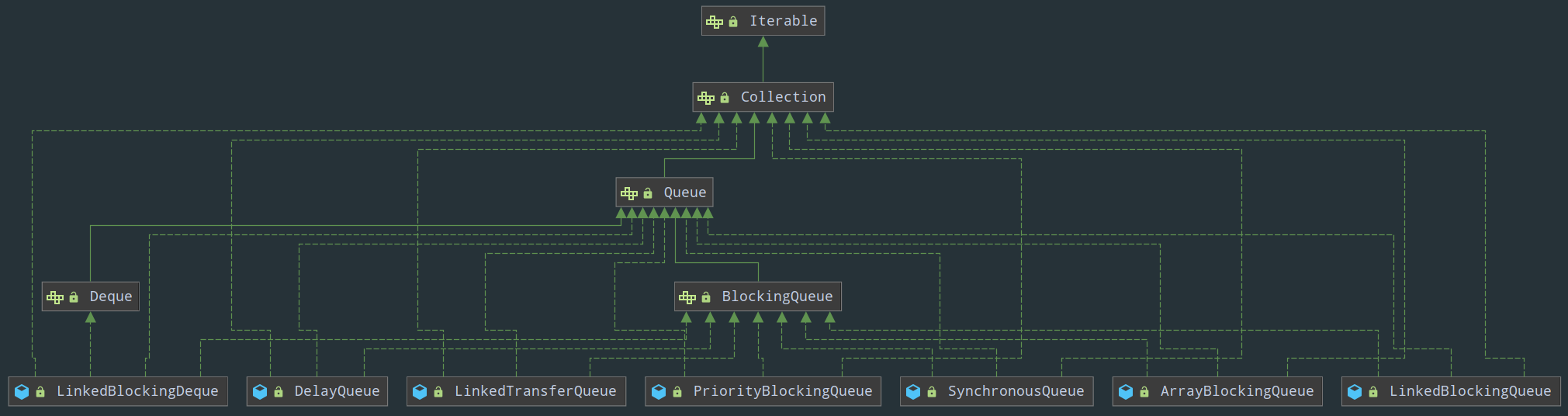
可以看见,Java 中提供了一个阻塞队列的接口 BlockingQueue 以及 7 个具体的实现(6 个单向队列和 1 个双端队列):
- ArrayBlockingQueue:一个由数组结构组成的有界阻塞队列
- LinkedBlockingQueue:一个由链表结构组成的有界阻塞队列
- PriorityBlockingQueue:一个支持优先级排序的无界阻塞队列
- DelayQueue:一个使用 PriorityBlockingQueue 实现的无界阻塞队列
- SynchronousQueue:一个不存储任何元素的阻塞队列
- LinkedTransferQueue:一个由链表结构组成的无界阻塞队列
- LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列
这里大家一定发现了一个问题,啥是有界队列啥是无界队列?
以 LinkedBlockingQueue 为例,来看它的构造函数:
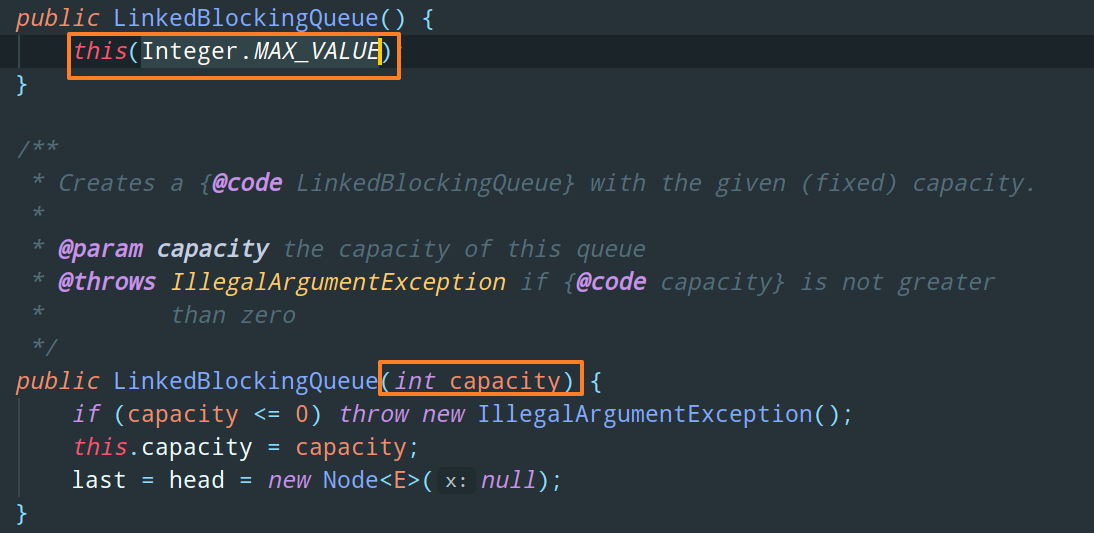
如图所示,LinkedBlockingQueue 有两个构造函数:
- 其中,带参构造函数需要指定队列的长度,并且当队列满了之后也不会对其进行扩容,这就是有界队列
- 而无参构造函数赋给队列的长度是
Integer.MAX_VALUE,显然现实几乎不会有这么大的容量超过Integer.MAX_VALUE,所以从使用者的体验上,可以无限入队,相当于无界队列
阻塞队列的基本原理
我不打算在这篇文章里挨个讲解这 7 个阻塞队列的具体实现细节,但是阻塞队列的基本原理,我们有必要现在就弄清楚。
不同于寻常队列,BlockingQueue 接口分别提供了 4 种不同的方法来对入队和出队操作进行处理:

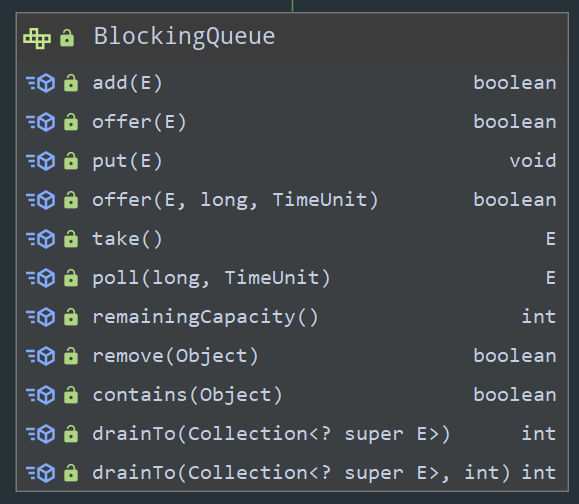
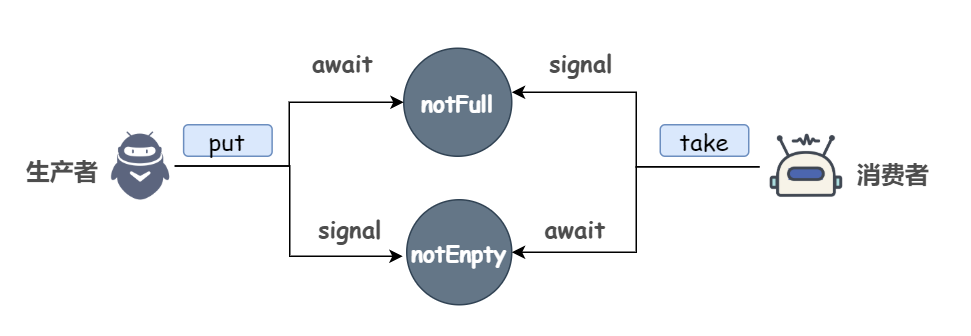
显然,最重要的两个方法就是 “阻塞进” put() 和 “阻塞出” take()
上面说过,对于经典的生产者-消费者模式来说,当队列满时,生产者阻塞,即无法执行 put 操作,当队列空时,消费者阻塞,即无法执行 take 操作。那么很容易想到一个问题,当生产者开始添加元素的时候,消费者该如何知道队列中已经开始有元素了呢?
首先,我们简单的思考一下,阻塞该如何实现?
是的,没错,“锁” Lock。
再想一下,生产者或者消费者阻塞的意思是不是可以理解为生产者或者消费者线程持有锁并处于等待态?
那有没有一种机制可以使线程陷入沉睡然后还能唤醒它呢?
答案已经呼之欲出了:
Condition也就是说所谓的通知模式。
以 ArrayBlockingQueue 为例,我们先来看一下它的基本成员变量:

如我们所分析的那样,lock 是一个可重入锁,notEmpty(队列不为空) 和 notFull(队列不满) 是两个等待条件。
其他的,ArrayBlockingQueue 中用来存储元素的实际上是一个 Object 数组 items,takeIndex 和 putIndex 分别表示队首元素和队尾元素的下标,count 表示队列中元素的个数。
然后来看 put 方法的实现:
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
// 获取可中断锁
lock.lockInterruptibly();
try {
// 如果当前元素个数等于队列的最大长度,则调用 notFull.await() 进行等待
while (count == items.length)
notFull.await();
// 向队列中插入元素
enqueue(e);
} finally {
// 入队成功,释放锁
lock.unlock();
}
}分为四步走:
- 获取可中断锁
- 如果当前元素个数等于队列的最大长度,notFull(队列不为空) 这个条件不成立,则调用
notFull.await()进行等待 - 如果当前元素个数小于队列的最大长度,向队列中插入元素
- 最后,入队成功,释放锁
既然在 notFull 这个条件上执行了等待,那当元素个数小于队列的最大长度时,notFull 这个条件成立,应该对其进行唤醒。也就是说,当元素的个数开始变少的时候,应该执行 notFull.signal。不用说,take 方法中肯定是这样做的:
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
// 获取可中断锁
lock.lockInterruptibly();
try {
// 如果队列中没有元素,则调用 notEmpty.await() 进行等待
while (count == 0)
notEmpty.await();
// 从队列中取出元素
return dequeue();
} finally {
// 出队成功,释放锁
lock.unlock();
}
}take 同样是四步走:
- 获取可中断锁
- 如果队列中没有元素,notEmpty(队列不满) 这个条件不成立,则调用
notEmpty.await()进行等待 - 如果队列中有元素,则从队列中取出元素
- 最后,出队成功,释放锁
唤醒生产者线程的 notFull.signal 就写在 dequeue 方法中:
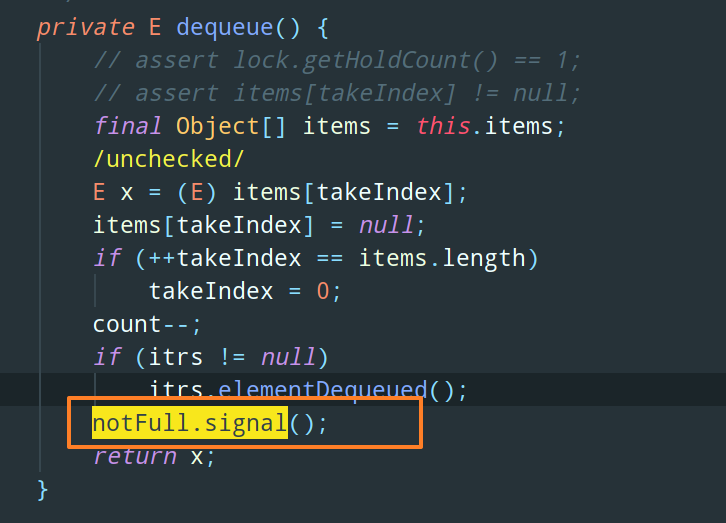
同样的,当队列中元素开始增加的时候,notEmpty 这个条件成立,需要调用 notEmpty.signal 唤醒消费者,这写在 put 方法调用的 enqueue 中:
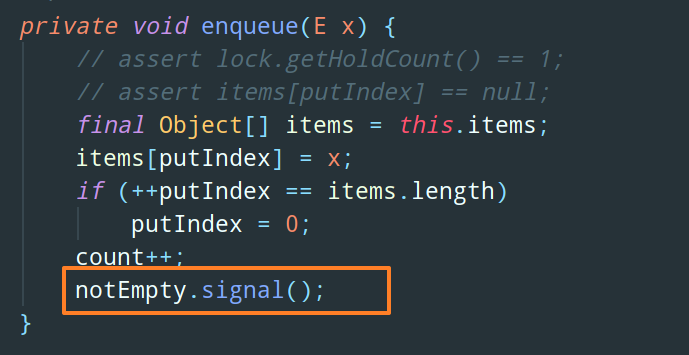
整体如下图所示:
Java 中的非阻塞队列
Java 中 Queue 其实可以分为两大类,除了阻塞队列 BlockingQueue,还有非阻塞队列 ConcurrentLinkedQueue,它不会阻塞线程,而是利用 CAS 来保证线程安全。本文就先不做详细介绍了
经典写时复制 CopyOnWriteArrayList
众所周知,ArrayList 并不是一个线程安全的集合,如果想要使用线程安全的 ArrayList 的话,其替代品有 Vector,但是 Vector 其实是一个比较老的容器了,并且类似于 HastTable 和 HashMap 的区别,Vector 其实是非常粗暴的给所有方法都加上了锁,导致并发度不高。

juc 中为 HashMap 提供了一个并发度更高的线程安全实现 ConcurrentHashMap ,同样的,也为 ArrayList 提供了 CopyOnWriteArrayList,不过相对于 ConcurrentHashMap 统治级的使用频率和面试时的出镜率来说,CopyOnWriteArrayList 这个线程安全的集合似乎有点冷门了,很容易被大伙儿忽略掉。
但事实上,CopyOnWriteArrayList 中所涉及的 Copy-On-Write(COW) 思想,其实还是很重要的。
ArrayList 的线程不安全问题
抛开写操作冲突这种简单的线程不安全问题不说,我们来看下读写操作冲突的情况:
在单线程环境下,是没有任何问题的。
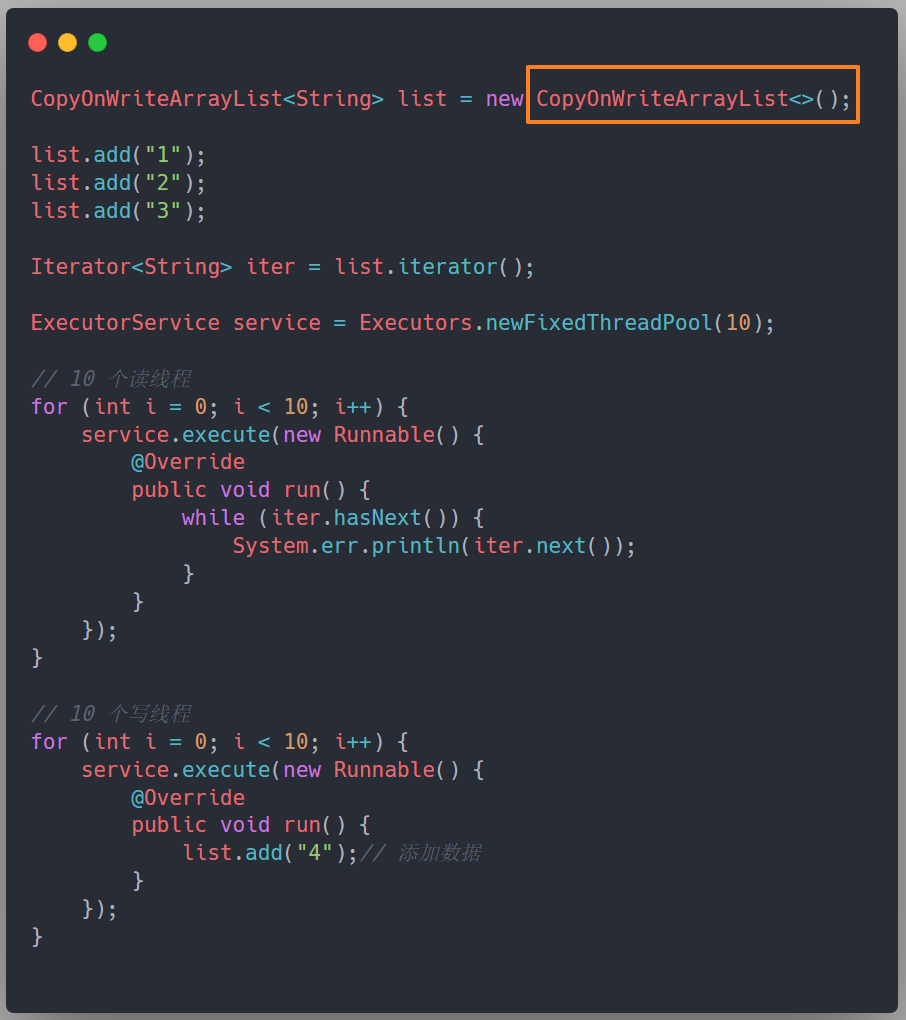
但是,在多线程环境下,如果存在线程对这个 list 进行修改,就会抛异常,因为 ArrayList 在迭代的时候是不允许有其他线程对这个集合进行修改的。如下,我们模拟了读写线程并发的情况,会抛出 java.util.ConcurrentModificationException 的异常:
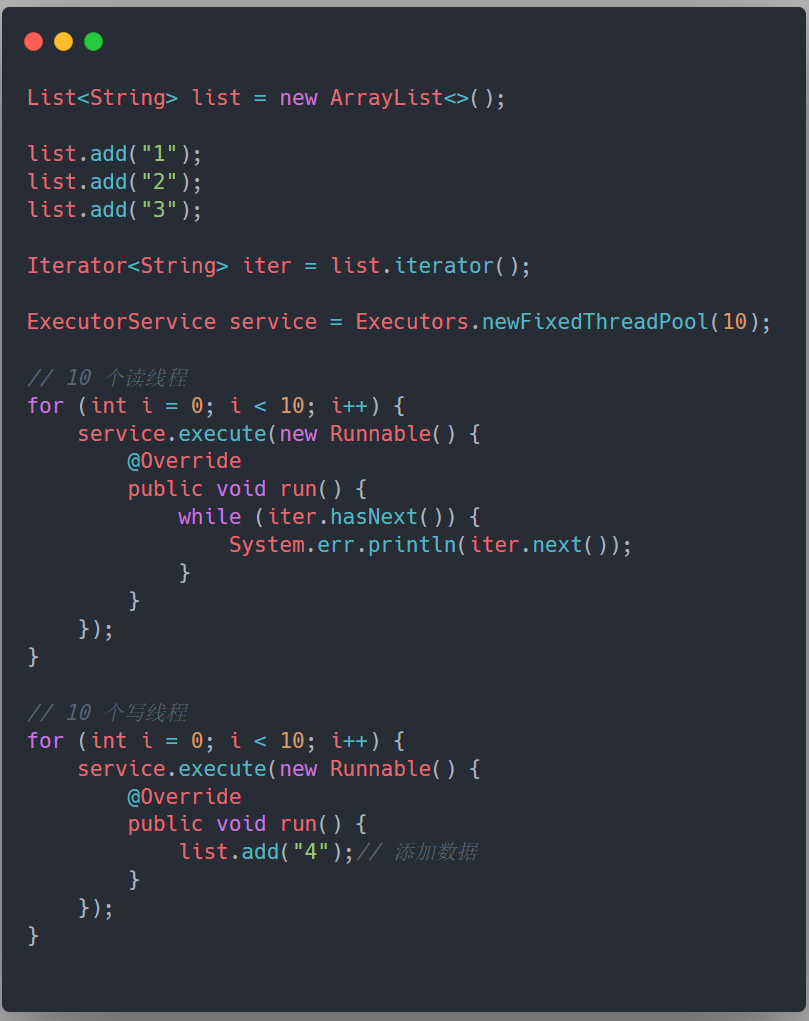
暴露的问题已经很显然,所以,如何能够在保证并发度的情况下,避免多线程操作 ArrayList 的线程不安全问题呢?
什么是 Copy-On-Write
大部分的业务场景都是读多写少的,就算很多个读线程同时来读数据,也不会对数据本身产生影响,所以如果想要提升并发度,很自然的就会想到读写分离,这个我们在 ReentrantReadWriteLock 文章中讲过:即写锁是排他锁,在写线程访问时,所有的读线程和其他写线程均被阻塞;读锁是共享锁,在同一时刻可以允许多个读线程进行访问。
但是上述这个读写分离的思想其实还是有一定的局限性,那就是写线程在访问的时候,读线程仍然会被阻塞住,如果我们想要读线程无论在什么时候都不会被阻塞,这样并发度岂不是可以更高?
看到这里肯定马上就有小伙伴抛出疑问了:如果一个写线程在修改数据的时候,不对读线程其进行加锁,那读线程读到的不就是旧数据吗?
确实是这样的。但是 COW 思想就是放弃了这种数据实时性,通过满足数据的最终一致性从而提升并发度。
所以,可以理解为 COW 其实就是一种优化手段,一种你需要在实时性和最终一致性之间做权衡的优化手段。
COW,Copy On Write,顾名思义,写时复制。
通俗来说,当我们往一个集合 A 中添加元素的时候,并不是直接就实实在在地插入这个集合 A 中,而是先对当前的集合进行一个拷贝(Copy)得到一个新的集合 A_copy,然后再往这个 A_copy 中插入元素。当写操作执行完毕后,集合 A 就没有用了,将指向原来集合 A 的指针指向新集合A_copy。
这样,就相当于,读线程读到的仍然是集合 A 中的元素,不需要对读线程进行任何的加锁操作,因为集合 A 不会被修改;而写线程其实修改的是 A_copy 这个集合。
来看源码:
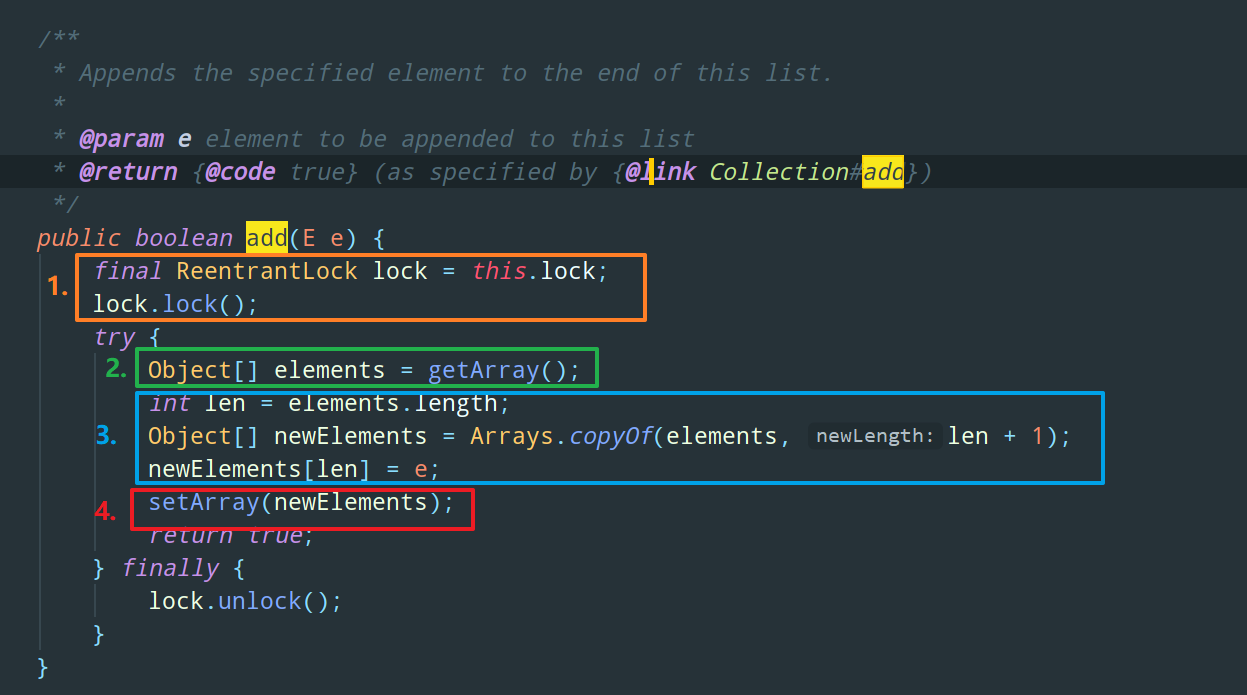
分为四步走:
-
采用
ReentrantLock进行加锁,保证同一时刻只有一个写线程对这个数据进行修改 -
获取原数组
-
copy 一份新的数组
newElemnets[]出来,并且新数组的长度 + 1,然后往这个新数组中插入元素 -
最后,这个
setArray,就是把CopyOnWrite底层真正存储元素的 array 数组指向newElements可以理解为,经过这一步,之前获得的那个旧数组
elements[]就正式的消失了,以后用的都是newElements[]这个数组了
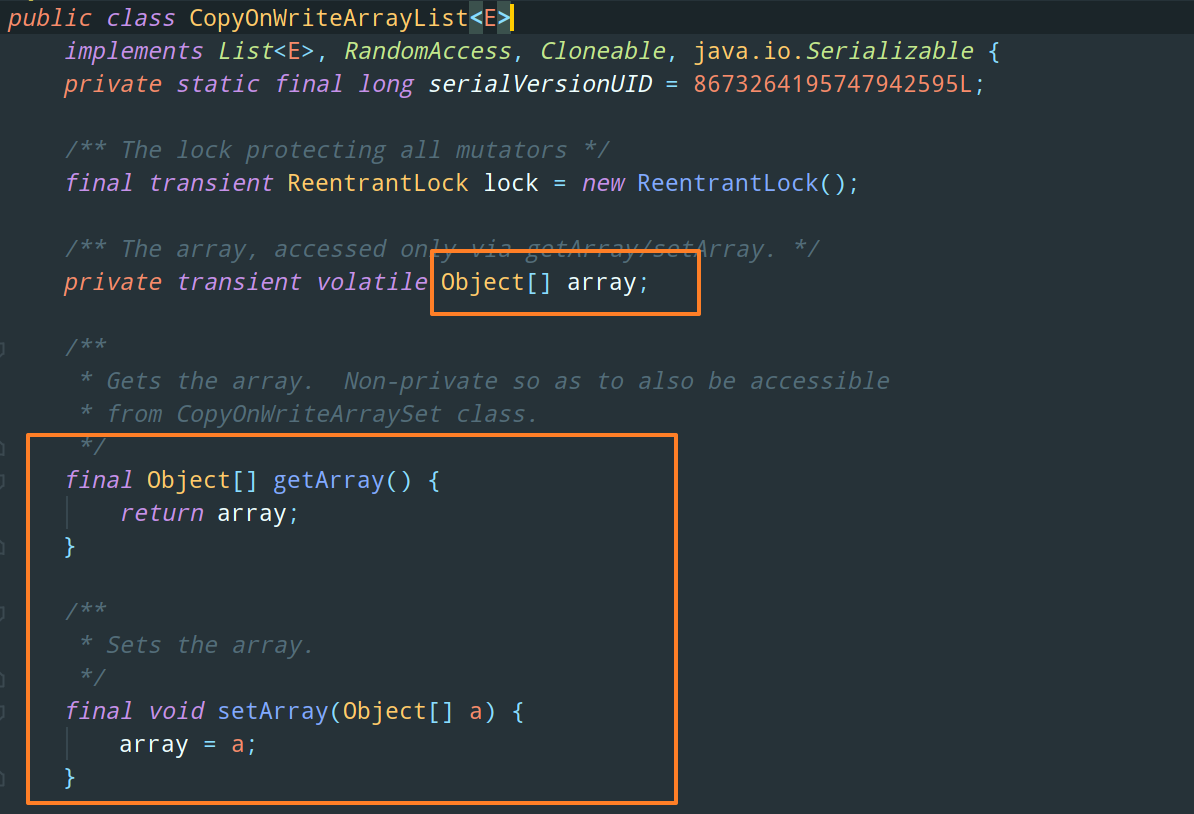
所以,我们把上述 ArrayList 线程不安全问题的那段代码中的 ArrayList 换成 CopyOnWriteArrayList 就不会抛异常了,毕竟读线程正在遍历的集合是旧的(尴尬了):
延时感知
我们上面说 COW 牺牲了实时性而保证最终一致性,简单来说,读线程对于数据的更新是延时感知的,是有一定滞后的。
我们可以在 add 方法修改数组引用指向新数组之前打个断点来看一下:
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
// 打个断点
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}假设此时有两个线程,一个读线程,一个写线程,数组一开始是 [1],写线程往这个数组中添加了一个元素 2,即生成了一个新数组 [1,2],并且停在了我们打的断点处,也就是说此时数组引用仍然指向旧数组。同时,读线程不会阻塞,读取到的仍然是旧数组中的值。
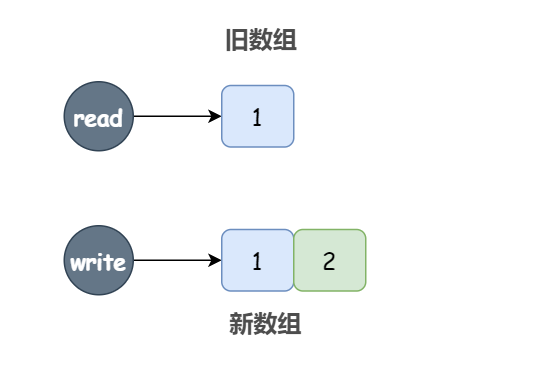
当我们从断点继续往下执行时,读线程才能够读到新数组上,读到完整的数据 [1,2],也就是说这中间有一小段的延迟,但是最终的结果是正确的。
COW 的缺点
看到这里其实 COW 的缺点已经非常明显了,那就是内存占用问题,每修改一次数组,就意味着需要开辟内存空间生成一个新数组,对于写操作比较频繁的场景,频繁的元素添加会造成数组的不断扩容和复制,十分消耗性能和内存,并且如果原数组的数据比较多的话,还可能会导致 Young GC 或者 Full GC。
另外,如果业务场景对数据实时性要求比较高的话,也是不建议使用 COW 的。
1 Comment
Comments are closed.