下面的文档描述了一些可以在Redis中使用的新开发模式。
批量加载
使用Redis协议批量写入数据
使用Redis协议批量写入数据
批量加载是用大量预先存在的数据加载Redis的过程。理想情况下,您希望快速有效地执行此操作。本文档描述了在Redis中批量加载数据的一些策略。
使用Redis协议进行批量加载
使用普通的Redis客户端执行批量加载并不是个好主意,原因如下:一个命令接一个命令发送的简单方法很慢,因为你必须为每个命令的往返时间付费。可以使用流水线,但是要批量加载许多记录,您需要在读取回复的同时编写新命令,以确保您尽可能快地插入。
只有一小部分客户端支持非阻塞I/O,并不是所有的客户端都能够以一种有效的方式解析应答以最大化吞吐量。由于所有这些原因,将大量数据导入Redis的首选方法是生成一个包含Redis协议的文本文件,以原始格式,以便调用插入所需数据所需的命令。
例如,如果我需要生成一个大型数据集,其中有数十亿个键的形式:' keyN -> ValueN',我会创建一个包含以下命令的文件,以Redis协议格式:
SET Key0 Value0
SET Key1 Value1
...
SET KeyN ValueN一旦创建了这个文件,剩下的动作就是尽快将它提供给Redis。在过去,这样做的方法是使用netcat和下面的命令:
(cat data.txt; sleep 10) | nc localhost 6379 > /dev/null然而,这不是一个非常可靠的方式来执行大规模导入,因为netcat并不真正知道所有的数据是什么时候传输的,也不能检查错误。在2.6或更高版本的Redis中,Redis -cli实用程序支持一种名为管道模式的新模式,该模式是为了执行批量加载而设计的。
使用管道模式运行的命令如下所示:
cat data.txt | redis-cli --pipe这将产生类似于下面的输出:
All data transferred. Waiting for the last reply...
Last reply received from server.
errors: 0, replies: 1000000Redis -cli实用程序还将确保只将从Redis实例接收到的错误重定向到标准输出。
生成Redis协议
Redis协议的生成和解析非常简单,文档在这里。然而,为了生成用于批量加载的协议,你不需要了解协议的每个细节,只需了解每个命令以以下方式表示即可:
*<args><cr><lf>
$<len><cr><lf>
<arg0><cr><lf>
<arg1><cr><lf>
...
<argN><cr><lf>其中\<cr>表示“\r”(或ASCII字符13),
例如,命令SET键值由以下协议表示:
*3<cr><lf>
$3<cr><lf>
SET<cr><lf>
$3<cr><lf>
key<cr><lf>
$5<cr><lf>
value<cr><lf>或表示为带引号的字符串:
"*3\r\n$3\r\nSET\r\n$3\r\nkey\r\n$5\r\nvalue\r\n"您需要为批量加载生成的文件只是由上述方式表示的命令组成,一个接一个。
下面的Ruby函数可以生成有效的协议:
def gen_redis_proto(*cmd)
proto = ""
proto << "*"+cmd.length.to_s+"\r\n"
cmd.each{|arg|
proto << "$"+arg.to_s.bytesize.to_s+"\r\n"
proto << arg.to_s+"\r\n"
}
proto
end
puts gen_redis_proto("SET","mykey","Hello World!").inspect使用上面的函数,可以很容易地在上面的例子中生成键值对,使用这个程序:
(0...1000).each{|n|
STDOUT.write(gen_redis_proto("SET","Key#{n}","Value#{n}"))
}我们可以直接在pipe to redis-cli中运行程序,以执行第一个大规模导入会话。
$ ruby proto。Rb | redis-cli—pipe
所有数据传输。等待最后的回复…
从服务器收到的最后一个回复。
错误:0,回复:1000管道模式在引擎盖下是如何工作的
在redis-cli的管道模式中需要的魔法是与netcat一样快,同时仍然能够理解服务器在同一时间发送的最后一个回复。
这是通过以下方式获得的:
- Redis-cli——pipe试图尽可能快地将数据发送到服务器。
- 与此同时,当数据可用时,它会读取数据,并尝试解析数据。
- 一旦没有更多的数据要从stdin读取,它会发送一个特殊的ECHO命令,其中包含一个随机的20字节字符串:我们确信这是最新发送的命令,并且我们确信我们可以匹配应答检查,如果我们接收到与批量应答相同的20字节。
- 一旦发送了这个特殊的final命令,接收应答的代码就开始用这20个字节来匹配应答。当到达匹配的应答时,它可以成功退出。
- 使用这个技巧,我们不需要解析我们发送给服务器的协议来了解我们发送了多少命令,只需要回答就可以了。
但是,在解析应答时,我们对解析的所有应答进行计数器,以便在结束时能够告诉用户批量插入会话传递给服务器的命令量。
使用Redis的分布式锁
Redis的分布式锁模式
在许多环境中,不同的进程必须以互斥的方式对共享资源进行操作,分布式锁是一种非常有用的原语。
有许多库和博客文章描述了如何使用Redis实现DLM(分布式锁管理器),但是每个库都使用不同的方法,许多库使用简单的方法,与稍微复杂一些的设计相比,保证更低。
这个页面描述了一个更规范的算法来实现Redis的分布式锁。我们提出了一种名为Redlock的算法,它实现了一种DLM,我们认为它比普通的单实例方法更安全。我们希望社区能够分析它,提供反馈,并将其作为实现或更复杂或替代设计的起点。
实现
在描述算法之前,这里有一些已有实现的链接,可供参考。
- Redlock-rb (Ruby implementation). There is also a fork of Redlock-rb that adds a gem for easy distribution.
- Redlock-py (Python implementation).
- Pottery (Python implementation).
- Aioredlock (Asyncio Python implementation).
- Redlock-php (PHP implementation).
- PHPRedisMutex (further PHP implementation).
- cheprasov/php-redis-lock (PHP library for locks).
- rtckit/react-redlock (Async PHP implementation).
- Redsync (Go implementation).
- Redisson (Java implementation).
- Redis::DistLock (Perl implementation).
- Redlock-cpp (C++ implementation).
- Redis-plus-plus (C++ implementation).
- Redlock-cs (C#/.NET implementation).
- RedLock.net (C#/.NET implementation). Includes async and lock extension support.
- ScarletLock (C# .NET implementation with configurable datastore).
- Redlock4Net (C# .NET implementation).
- node-redlock (NodeJS implementation). Includes support for lock extension.
- Deno DLM (Deno implementation)
安全活性保障
我们将用三个属性来建模我们的设计,从我们的角度来看,这三个属性是有效使用分布式锁所需的最低保证。
- 安全性质:互斥。在任何给定时刻,只有一个客户端可以持有一个锁。
- 活动属性A:无死锁。最终总是可以获得一个锁,即使锁定资源的客户端崩溃或被分区。
- 活属性B:容错。只要大多数Redis节点都启动了,客户端就能够获取和释放锁。
为什么基于故障转移的实现是不够的
为了理解我们想要改进什么,让我们分析一下大多数基于redis的分布式锁库的当前状态。
使用Redis锁定资源的最简单方法是在实例中创建一个密钥。密钥通常是在有限的时间内创建的,使用Redis的expires特性,因此最终它将被释放(属性2在我们的列表中)。当客户端需要释放资源时,它删除密钥。
从表面上看,这工作得很好,但有一个问题:这是我们架构中的一个单点故障。如果Redis主服务器宕机了怎么办?好吧,让我们添加一个副本!并在主服务器不可用时使用它。不幸的是,这是不可行的。这样我们就不能实现互斥的安全属性,因为Redis复制是异步的。
这个模型有一个竞争条件:
- 客户端A获得master中的锁。
- 在对密钥的写入传输到副本之前,主服务器崩溃。
- 副本被提升为master。
- 客户端B获得A已经持有的同一资源的锁。安全违反!
有时,在特殊情况下(例如在故障期间),多个客户机可以同时持有锁是完全没问题的。如果是这种情况,您可以使用基于复制的解决方案。否则,我们建议实现本文档中描述的解决方案。
单个实例的正确实现
在尝试克服上面描述的单实例设置的限制之前,让我们检查一下如何在这个简单的情况下正确地完成它,因为这在应用程序中实际上是一个可行的解决方案,因为锁定单个实例是我们将在这里描述的分布式算法中使用的基础。
要获得锁,要走的路如下:
SET resource_name my_random_value NX PX 30000该命令只会在密钥不存在的情况下设置该密钥(NX选项),过期时间为30000毫秒(PX选项)。该键被设置为值“my_random_value”。该值必须在所有客户端和所有锁请求中惟一。
基本上,使用随机值是为了以一种安全的方式释放锁,并使用脚本告诉Redis:只有当密钥存在且存储在密钥上的值恰好是我期望的值时才删除密钥。这是通过以下Lua脚本完成的:
if redis.call("get",KEYS[1]) == ARGV[1] then
返回redis.call(“▽”键[1])
其他的
返回0
结束为了避免删除由另一个客户端创建的锁,这很重要。例如,客户端可能获得锁,在超过锁有效时间(密钥到期时间)的情况下被阻止执行某些操作,然后删除已经被其他客户端获得的锁。仅使用DEL是不安全的,因为一个客户端可能会删除另一个客户端的锁。在上面的脚本中,每个锁都是用一个随机字符串“签名”的,因此只有当该锁仍然是试图删除它的客户端设置的锁时,该锁才会被删除。
这个随机字符串应该是什么?我们假设它是来自/dev/urandom的20个字节,但您可以找到更便宜的方法,使它足够独特,适合您的任务。例如,一个安全的选择是使用/dev/urandom为RC4播种,并从中生成一个伪随机流。一个更简单的解决方案是使用微秒精度的UNIX时间戳,将时间戳与客户机ID连接起来。它不是那么安全,但对于大多数环境来说可能足够了。
“锁有效时间”是我们用来作为钥匙使用的时间。它既是自动释放时间,也是客户端在另一个客户端能够再次获得锁之前执行所需操作的时间,而在技术上不违反互斥保证,互斥保证只局限于从获得锁的那一刻起的给定时间窗口。
现在我们有了一个获取和释放锁的好方法。有了这个系统,对由单个始终可用的实例组成的非分布式系统进行推理是安全的。让我们将这个概念扩展到分布式系统,在那里我们没有这样的保证。
Redlock算法
在算法的分布式版本中,我们假设我们有N个Redis master。这些节点是完全独立的,所以我们不使用复制或任何其他隐式协调系统。我们已经描述了如何在单个实例中安全地获取和释放锁。我们想当然地认为,算法将使用这种方法在单个实例中获取和释放锁。在我们的例子中,我们设置N=5,这是一个合理的值,所以我们需要在不同的计算机或虚拟机上运行5个Redis master,以确保它们以独立的方式出现故障。
为了获取锁,客户端执行以下操作:
- 它得到以毫秒为单位的当前时间。
- 它尝试按顺序在所有N个实例中获取锁,在所有实例中使用相同的密钥名和随机值。在步骤2中,当在每个实例中设置锁时,客户端使用一个比锁自动释放总时间小的超时来获取锁。例如,如果自动释放时间为10秒,则超时可能在~ 5-50毫秒范围内。这可以防止客户端在尝试与一个宕机的Redis节点通信时长时间处于阻塞状态:如果一个实例不可用,我们应该尽快尝试与下一个实例通信。
- 客户端通过从当前时间减去步骤1中获得的时间戳来计算获取锁所需的时间。当且仅当客户端能够在大多数实例(至少3个)中获得锁,并且获得锁的总时间小于锁的有效时间,则认为该锁已获得。
- 如果获得了锁,则认为锁的有效时间为初始有效时间减去经过的时间,如步骤3中计算的那样。
- 如果客户端由于某种原因无法获得锁(要么无法锁定N/2+1个实例,要么有效时间为负),它将尝试解锁所有实例(即使是它认为自己无法锁定的实例)。
算法是异步的吗?
该算法依赖于这样一个假设:虽然进程之间没有同步时钟,但每个进程中的本地时间以大致相同的速度更新,与锁的自动释放时间相比,有很小的误差幅度。这个假设非常类似于现实世界中的计算机:每台计算机都有一个本地时钟,我们通常可以依赖不同的计算机有一个很小的时钟漂移。
此时,我们需要更好地指定我们的互斥规则:只有当持有锁的客户端在锁有效时间内(如步骤3中所获得的),减去一些时间(为了补偿进程之间的时钟漂移,只有几毫秒)终止其工作时,才能保证互斥规则。
本文包含了更多关于需要绑定时钟漂移的类似系统的信息:租约:分布式文件缓存一致性的有效容错机制。
失败时重试
当客户端无法获取锁时,它应该在随机延迟后再尝试一次,以便尝试使多个试图同时获取同一资源的锁的客户端去同步化(这可能会导致没有人获胜的脑裂情况)。此外,客户端在大多数Redis实例中获取锁的速度越快,大脑分裂的窗口就越小(需要重试),所以理想情况下,客户端应该尝试使用多路复用同时向N个实例发送SET命令。
值得强调的是,对于无法获得大部分锁的客户端来说,尽快释放(部分)获得的锁是非常重要的,这样就不需要等待密钥到期才能再次获得锁(然而,如果发生网络分区,客户端不再能够与Redis实例通信,在等待密钥到期时,就需要支付可用性惩罚)。
释放锁
释放锁很简单,无论客户端是否相信它能够成功锁定给定实例,都可以执行释放锁。
安全参数
算法安全吗?让我们看看在不同的情况下会发生什么。
首先,让我们假设客户端能够在大多数实例中获得锁。所有实例都将包含一个具有相同生存时间的键。但是,密钥是在不同的时间设置的,因此密钥也将在不同的时间过期。但是,如果第一个密钥在时间T1(我们在联系第一个服务器之前进行采样的时间)时被设置为最坏,而最后一个密钥在时间T2(我们从最后一个服务器获得应答的时间)时被设置为最坏,那么我们可以确定该集中第一个过期的密钥将至少存在MIN_VALIDITY=TTL-(T2-T1)- clock_drift。所有其他密钥都将在稍后过期,因此我们可以确定至少在这一次,密钥将同时设置。
在大部分密钥设置的时间内,其他客户端将无法获得锁,因为如果已经存在N/2+1个密钥,则N/2+1 set NX操作将无法成功。因此,如果已获得锁,则不可能同时重新获得它(违反互斥属性)。
但是,我们还希望确保同时试图获得锁的多个客户机不能同时成功。
如果客户端锁定了大多数实例,所用的时间接近或大于锁的最大有效时间(我们基本上为SET使用的TTL),它将认为锁无效并解锁实例,因此我们只需要考虑客户端能够在小于有效时间的时间内锁定大多数实例的情况。在这种情况下,对于上面已经表达的参数,对于MIN_VALIDITY,任何客户端都不应该能够重新获得锁。因此,只有当锁定大多数实例的时间大于TTL时间时,多个客户端才能同时锁定N/2+1个实例(“time”是步骤2的结束),从而使锁定无效。
活性参数
系统的活跃性基于三个主要特性:
- 自动释放锁(因为密钥过期):最终密钥可以再次被锁定。
- 事实上,客户端通常会在未获得锁或获得锁并终止工作时配合删除锁,这使得我们可能不必等待密钥过期来重新获得锁。
- 事实上,当客户端需要重试锁时,它等待的时间比获取大多数锁所需的时间要长,以便在资源争用期间概率地使分裂大脑的情况不太可能发生。
但是,我们要在网络分区上支付等于TTL时间的可用性代价,因此如果存在连续的分区,我们可以无限期地支付这个代价。每当客户端获得锁并在能够移除锁之前进行分区时,都会发生这种情况。
基本上,如果有无限个连续的网络分区,系统可能在无限长的时间内不可用。
性能,崩溃恢复和fsync
许多使用Redis作为锁服务器的用户在获取和释放锁的延迟以及每秒可能执行的获取/释放操作数量方面都需要高性能。为了满足这一需求,与N个Redis服务器通信以减少延迟的策略肯定是多路复用(将套接字置于非阻塞模式,发送所有命令,并在以后读取所有命令,假设客户端和每个实例之间的RTT是相似的)。
然而,如果我们想要以崩溃恢复系统模型为目标,还有另一个关于持久性的考虑。
基本上,为了看到这里的问题,让我们假设我们配置Redis时完全没有持久性。客户端在5个实例中的3个获得锁。其中一个客户端能够获得锁的实例被重新启动,此时又有3个实例可以锁定同一个资源,另一个客户端可以再次锁定它,违反了锁的排他性安全属性。
如果我们启用AOF持久性,情况会有很大的改善。例如,我们可以通过发送SHUTDOWN命令并重新启动服务器来升级服务器。因为Redis的过期是在语义上实现的,所以当服务器关闭时,时间仍然会流逝,所以我们的所有需求都没问题。然而,一切都是好的,只要它是一个干净的关闭。停电怎么办?如果默认情况下,Redis配置为每秒在磁盘上进行fsync,那么在重新启动后,我们的密钥可能会丢失。理论上,如果我们想要在任何类型的实例重新启动时保证锁的安全性,我们需要在持久化设置中启用fsync=always。由于额外的同步开销,这会影响性能。
然而,事情比乍一看要好。基本上,只要实例在崩溃后重新启动,它就不再参与任何当前活动的锁,算法安全性就会保留。这意味着当实例重新启动时,当前活动的锁集都是由锁定实例获得的,而不是重新加入系统的实例。
为了保证这一点,我们只需要使一个实例在崩溃后不可用,至少比我们使用的最大TTL长一点。这是实例崩溃时存在的关于锁的所有键变为无效并自动释放所需的时间。
使用延迟重启基本上可以实现安全,即使没有任何类型的Redis持久性可用,但请注意,这可能会转化为可用性惩罚。例如,如果大多数实例崩溃,系统将在TTL内变得全局不可用(这里的全局意味着在这段时间内没有资源是可锁定的)。
使算法更可靠:扩展锁
如果客户端执行的工作由小步骤组成,则可以在默认情况下使用更小的锁有效期,并扩展算法实现锁扩展机制。基本上,客户端,如果在计算过程中,锁的有效期接近一个较低的值,可以通过发送一个Lua脚本到所有实例来延长密钥的生存时间(如果密钥存在并且它的值仍然是客户端在获得锁时分配的随机值)来延长锁。
如果客户端能够将锁扩展到大多数实例,并且在有效时间内(基本上使用的算法与获取锁时使用的算法非常相似),则应该只考虑重新获得的锁。
但是,这在技术上并不会改变算法,因此应该限制锁重新获取尝试的最大次数,否则将违反活动属性之一。
一致性免责声明
请仔细阅读本页末尾的“Redlock分析”部分。Martin Kleppman的文章和antirez的回答都非常相关。如果您关注一致性和正确性,请注意以下主题:
- 您应该实现隔离令牌。这对于需要大量时间的进程尤其重要,并且适用于任何分布式锁定系统。延长锁的生命周期也是一种选择,但不要假设只要获得锁的进程是活的,锁就会被保留。
- Redis没有使用单调时钟的TTL到期机制。这意味着一个时钟移位可能会导致一个锁被多个进程获取。尽管可以通过阻止管理员手动设置服务器时间和正确设置NTP来缓解这个问题,但在现实生活中仍然有可能发生这个问题并影响一致性。
想帮忙吗?
如果你从事分布式系统,能有你的意见/分析就太好了。另外,其他语言的引用实现也很好。
Redlock分析
Martin Kleppmann分析了Redlock。在这里可以找到与此分析相反的观点。
二级索引
在Redis中构建二级索引
Redis并不是一个确切的键值存储,因为值可以是复杂的数据结构。但是,它有一个外部键值外壳:在API级别,数据通过键名来寻址。公平地说,Redis本身只提供主键访问。然而,由于Redis是一个数据结构服务器,它的功能可以用于索引,以创建不同类型的二级索引,包括复合(多列)索引。
本文档解释了如何在Redis中使用以下数据结构创建索引:
- 按ID或其他数值字段创建二级索引的排序集。
- 具有字典范围的排序集,用于创建更高级的二级索引、复合索引和图遍历索引。
- 用于创建随机索引的集合。
- 用于创建简单可迭代索引和最后N项索引的列表。
使用Redis实现和维护索引是一个高级主题,因此大多数需要对数据执行复杂查询的用户应该了解关系存储是否更好地为他们服务。然而,通常情况下,特别是在缓存场景中,为了加速需要某种形式的索引才能执行的常见查询,显式地需要将索引数据存储到Redis中。
带排序集的简单数值索引
你可以用Redis创建的最简单的二级索引是通过使用排序集数据类型,这是一个数据结构,表示一组元素按浮点数排序,这是每个元素的得分。元素从最小到最高的分数排序。
由于分数是双精度浮点数,因此可以使用普通排序集构建的索引仅限于索引字段是给定范围内的数字的内容。
构建这类索引的两个命令是ZADD和ZRANGE,它们带有BYSCORE参数,分别用于在指定范围内添加项和检索项。
例如,通过向已排序的集合中添加元素,可以按年龄对一组人名进行索引。元素将是人的名字,分数将是年龄。
ZADD myindex 25 Manuel
ZADD myindex 18 Anna
ZADD myindex 35 Jon
ZADD myindex 67 Helen为了检索所有年龄在20到40岁之间的人,可以使用以下命令:
ZRANGE myindex 20 40 BYSCORE
1) "Manuel"
2) "Jon"通过使用ZRANGE的WITHSCORES选项,也可以获得与返回元素相关的分数。
可以使用ZCOUNT命令来检索给定范围内的元素数量,而不实际获取元素,这也很有用,特别是考虑到无论范围大小,操作都在对数时间内执行。
范围可以包含或排除,请参阅ZRANGE命令文档了解更多信息。
注意:使用带有BYSCORE和REV参数的ZRANGE,可以以相反的顺序查询范围,当数据按照给定的方向(升序或降序)索引时,这通常很有用,但我们希望以相反的方式检索信息。
使用对象id作为关联值
在上面的例子中,我们把名字和年龄联系起来。然而,一般来说,我们可能希望索引存储在其他地方的对象的某个字段。不直接使用排序的集值来存储与索引字段相关的数据,可以只存储对象的ID。
例如,我可能有Redis哈希表示用户。每个用户都由一个键表示,可以通过ID直接访问:
HMSET用户:1 id 1用户名antirez ctime 1444809424年龄38岁
HMSET用户:2 id 2用户名maria ctime 1444808132年龄42
HMSET用户:3 id 3用户名jballard ctime 1443246218年龄33如果我想创建一个索引来查询用户的年龄,我可以这样做:
ZADD user.age.index 38 1
ZADD user.age.index 42 2
ZADD user.age.index 33 3这一次,与排序集中的分数相关联的值是对象的ID。因此,一旦我用BYSCORE参数用ZRANGE查询索引,我还必须用HGETALL或类似的命令检索我需要的信息。最明显的优点是对象可以在不改变索引的情况下改变,只要我们不改变索引字段。
在接下来的示例中,我们几乎总是使用id作为与索引相关的值,因为这通常是更合理的设计,只有少数例外。
更新简单的排序集合索引
我们通常会索引随时间变化的事物。在上面的例子中,用户的年龄每年都在变化。在这种情况下,使用出生日期作为索引而不是年龄本身是有意义的,但在其他情况下,我们只是想让某些字段不时发生变化,而索引反映这种变化。
ZADD命令使得更新简单索引成为一个非常简单的操作,因为重新添加一个具有不同分数和相同值的元素将简单地更新分数并将元素移动到正确的位置,因此如果用户antirez已经39岁了,为了更新表示用户的散列中的数据,以及在索引中,我们需要执行以下两个命令:
HSET user:1 age 39
ZADD user.age.index 39 1操作可以包装在MULTI/EXEC事务中,以确保两个字段都被更新或没有。
将多维数据转化为线性数据
使用排序集创建的索引只能索引单个数值。因此,您可能认为不可能使用这种索引来索引具有多个维度的东西,但实际上这并不总是正确的。如果你能有效地用线性方式表示多维的东西,通常可以使用一个简单的排序集进行索引。
例如,Redis地理索引API使用一种称为地理散列的技术,使用一个排序集来按纬度和经度索引地方。排序集的分数表示经度和纬度的交替位,因此我们将排序集的线性分数映射到地球表面的许多小正方形上。通过8+1样式中心加上邻域搜索,可以通过半径检索元素。
分数限制
排序集合元素分数是双精度浮点数。这意味着它们可以表示具有不同错误的不同十进制或整数值,因为它们在内部使用指数表示。然而,对于索引目的来说,有趣的是,分数总是能够表示-9007199254740992和9007199254740992之间的任何错误数,即-/+ 2^53。
当表示更大的数字时,需要一种能够以任意精度对数字进行索引的不同形式的索引,称为词典索引。
辞典编纂的索引
Redis排序集有一个有趣的属性。当以相同的分数添加元素时,它们将按字典顺序排序,将字符串作为二进制数据与memcmp()函数进行比较。
对于不了解C语言和memcmp函数的人来说,它的意思是,具有相同分数的元素将逐个字节比较其字节的原始值进行排序。如果第一个字节相同,则检查第二个字节,以此类推。如果两个字符串的公共前缀相同,则较长的字符串被认为是两者中较大的一个,因此"foobar"大于"foo"。
有一些命令,如ZRANGE和ZLEXCOUNT,能够以字典方式查询和计数范围,假设它们用于排序集,其中所有元素都具有相同的分数。
Redis的这个特性基本上等同于b-树数据结构,b-树数据结构通常用于实现传统数据库的索引。正如你可以猜到的,正因为如此,可以使用这个Redis数据结构来实现非常漂亮的索引。
在深入使用字典索引之前,让我们检查一下排序集在这种特殊操作模式下的行为。因为我们需要添加具有相同分数的元素,所以我们总是使用特殊的分数0。
ZADD myindex 0 baaa
ZADD myindex 0 abbb
ZADD myindex 0 aaaa
ZADD myindex 0 bbbb从已排序的集合中获取所有元素立即显示它们是按字典顺序排列的。
ZRANGE myindex 0 -1
1) "aaaa"
2) "abbb"
3) "baaa"
4) "bbbb"现在我们可以使用ZRANGE和BYLEX参数来执行范围查询。
ZRANGE myindex [a (b BYLEX
1) "aaaa"
2) "abbb"注意,在范围查询中,我们在min和max元素前面加上了特殊字符[和(来标识范围。这些前缀是强制的,它们指定范围的元素是包含的还是排除的。那么范围[a (b表示给出a包含b排除之间的所有元素,也就是所有以a开头的元素。
还有两个更特殊的字符表示无限负字符串和无限正字符串,它们是-和+。
ZRANGE myindex [b + BYLEX
1) "baaa"
2) "bbbb"基本上就是这样。让我们看看如何使用这些特性来构建索引。
第一个例子:完成
索引的一个有趣的应用是补全。完成是当您开始在搜索引擎中输入查询时发生的事情:用户界面将预测您可能键入的内容,提供以相同字符开头的常见查询。
一种简单的完成方法是将我们从用户那里得到的每个查询都添加到索引中。例如,如果用户搜索banana,我们会这样做:
ZADD myindex 0 banana对于遇到的每个搜索查询都是如此。然后,当我们想要完成用户输入时,使用ZRANGE和BYLEX参数执行范围查询。假设用户在搜索表单中输入“bit”,我们希望提供以“bit”开头的可能的搜索关键字。我们向Redis发送这样的命令:
ZRANGE myindex "[bit" "[bit\xff" BYLEX基本上,我们创建一个范围使用用户正在输入的字符串作为开始,相同的字符串加上一个末尾字节设置为255,在示例中是\xff,作为范围的结束。通过这种方式,我们获得了用户输入的字符串的所有开头的字符串。
注意,我们不希望返回太多项,因此可以使用LIMIT选项以减少结果的数量。
在混合中加入频率
上面的方法有点幼稚,因为所有的用户搜索都是这样的。在实际系统中,我们希望根据字符串的频率来完成它们:与很少输入的字符串相比,非常流行的搜索将以更高的概率被提出。
为了实现一些依赖于频率的东西,同时自动适应未来的输入,通过清除不再流行的搜索,我们可以使用一个非常简单的流算法。
首先,我们修改索引,以便不仅存储搜索词,还存储与该词相关的频率。所以不只是加香蕉,而是加香蕉:1,其中1是频率。
ZADD myindex 0 banana:1我们还需要逻辑来增加索引,如果搜索词已经存在于索引中,那么我们实际要做的是这样的:
ZRANGE myindex "[banana:" + BYLEX LIMIT 0 1
1) "banana:1"这将返回banana的单个条目(如果它存在)。然后我们可以增加相关的频率,并发送以下两个命令:
ZREM myindex 0 banana:1
ZADD myindex 0 banana:2请注意,因为可能存在并发更新,所以以上三个命令应该通过Lua脚本发送,这样Lua脚本将自动获得旧的计数并重新添加带有递增分数的项目。
结果是,每次用户搜索banana时,我们都会更新我们的条目。
还有更多:我们的目标是让物品经常被搜索。所以我们需要某种形式的净化。当我们为了完成用户输入而实际查询索引时,我们可能会看到类似这样的东西:
ZRANGE myindex "[banana:" + BYLEX LIMIT 0 10
1) "banana:123"
2) "banaooo:1"
3) "banned user:49"
4) "banning:89"例如,显然没有人搜索“banaooo”,但是查询只执行了一次,所以我们最终将它呈现给用户。
这就是我们能做的。从返回的项目中,我们随机选择一个项目,将其分数减1,并将其与新的分数重新添加。但是,如果分数达到0,我们就简单地从列表中删除该项。你可以使用更先进的系统,但我们的想法是,从长远来看,索引将包含热门搜索,如果热门搜索将随着时间的推移而变化,它将自动适应。
对该算法的改进是根据它们的权重在列表中选择条目:分数越高,选择条目的可能性就越小,从而降低它的分数,或将它们驱逐出去。
规范化字符串的大小写和重音
在补全示例中,我们总是使用小写字符串。然而,现实远比这复杂得多:语言有大写的名字、口音等等。
处理这个问题的一个简单方法是将用户搜索的字符串规范化。无论用户搜索“香蕉”,“香蕉”或“巴娜娜”,我们可能总是把它变成“香蕉”。
然而,有时我们可能希望向用户提供原始的项目类型,即使我们将字符串规范化以进行索引。为了做到这一点,我们要做的是改变索引的格式,这样我们就不只是存储term:frequency,而是存储normalized:frequency:original,如下例所示:
ZADD myindex 0 banana:273:Banana基本上,我们添加了另一个字段,我们将提取并仅用于可视化。范围将始终使用规范化字符串来计算。这是一个常见的技巧,有多种应用。
在索引中添加辅助信息
当直接使用排序集时,每个对象都有两个不同的属性:分数(用作索引)和相关值。当使用字典索引时,分数总是设置为0,基本上根本不使用。我们只剩下一个字符串,也就是元素本身。
就像我们在前面的补全示例中所做的一样,我们仍然能够使用分隔符存储相关数据。例如,我们使用冒号来添加频率和原始单词来完成。
一般来说,我们可以向索引键添加任何类型的关联值。为了使用字典索引实现简单的键值存储,我们只需将条目存储为key:value:
ZADD myindex 0 mykey:myvalue并且搜索这个key,使用:
ZRANGE myindex [mykey: + BYLEX LIMIT 0 1
1) "mykey:myvalue"然后提取冒号后面的部分以检索值。然而,在这种情况下要解决的问题是碰撞。冒号字符可能是键本身的一部分,因此必须选择它,以免与我们添加的键冲突。
由于Redis中的字典范围是二进制安全的,您可以使用任何字节或任何字节序列。但是,如果您接收到不可信的用户输入,最好使用某种形式的转义,以保证分隔符永远不会碰巧是键的一部分。
例如,如果您使用两个空字节作为分隔符“\0\0”,您可能希望始终将空字节转义为字符串中的两个字节序列。
数值填充
只有当手头的问题是索引字符串时,字典索引才看起来不错。实际上,使用这种索引对任意精度数进行索引是非常简单的。
在ASCII字符集中,数字按照从0到9的顺序出现,因此如果我们将数字的前导为零,结果是将它们作为字符串进行比较,将根据它们的数值对它们进行排序。
ZADD myindex 0 00324823481:foo
ZADD myindex 0 12838349234:bar
ZADD myindex 0 00000000111:zap
ZRANGE myindex 0 -1
1) "00000000111:zap"
2) "00324823481:foo"
3) "12838349234:bar"我们有效地使用数值字段创建了一个索引,该字段可以任意大。这也适用于任何精度的浮点数,确保我们用前导零填充数字部分,小数部分用后面的零填充,如下所示的数字列表:
01000000000000.11000000000000
01000000000000.02200000000000
00000002121241.34893482930000
00999999999999.00000000000000使用二进制形式的数字
用十进制存储数字会占用太多内存。另一种方法是直接以二进制形式存储数字,例如128位整数。但是,要实现这一点,您需要以大端序格式存储数字,以便最高有效字节存储在最低有效字节之前。这样,当Redis将字符串与memcmp()进行比较时,它将有效地根据值对数字进行排序。
请记住,以二进制格式存储的数据对调试来说不太容易观察,更难解析和导出。所以这绝对是一种权衡。
复合索引的
到目前为止,我们已经探索了索引单个字段的方法。然而,我们都知道SQL存储能够使用多个字段创建索引。例如,我可以根据房间号和价格在一个非常大的商店中索引产品。
我需要运行查询,以检索给定房间中具有给定价格范围的所有产品。我能做的是用以下方式索引每个产品:
ZADD myindex 0 0056:0028.44:90
ZADD myindex 0 0034:0011.00:832这里的字段是`room\:price\:product_id。为了简单起见,我在示例中只使用了四位数字填充。辅助数据(产品ID)不需要任何填充。
有了这样的指数,把56号房间里所有的商品的价格都定在10美元到30美元之间就很容易了。我们可以运行下面的命令:
ZRANGE myindex [0056:0010.00 [0056:0030.00 BYLEX以上称为组合索引。它的有效性取决于字段的顺序和我想要运行的查询。例如,上述指数不能有效地用于获得具有特定价格范围的所有产品,而不考虑房间号。然而,我可以使用主键来运行查询,而不考虑价格,比如给我44号房间的所有产品。
复合索引功能非常强大,在传统存储中用于优化复杂的查询。在Redis中,它们既可以用于实现存储在传统数据存储中的东西的非常快速的Redis内存索引,也可以用于直接索引Redis数据。
更新字典索引
在字典索引中,索引的值可能非常复杂,并且很难或很慢地从我们存储的关于对象的内容中重新构建。因此,一种以使用更多内存为代价简化索引处理的方法是,在表示索引的排序集旁边加上一个将对象ID映射到当前索引值的哈希。
举个例子,当我们建立索引时,我们也会加到哈希中:
MULTI
ZADD myindex 0 0056:0028.44:90
HSET index.content 90 0056:0028.44:90
EXEC这并不总是必需的,但是简化了更新索引的操作。为了删除我们为对象ID 90索引的旧信息,不管对象的当前字段值如何,我们只需要根据对象ID检索哈希值,并在排序集视图中ZREM它。
使用六边形存储表示和查询图
关于复合索引的一件很酷的事情是,为了表示图形,它们很方便,使用一种称为Hexastore的数据结构。
六元存储提供了对象之间关系的表示,由主语、谓语和对象组成。对象之间的简单关系可以是:
antirez is-friend-of matteocollina为了表示这种关系,我可以在我的字典索引中存储以下元素:
ZADD myindex 0 spo:antirez:is-friend-of:matteocollina注意,我在项目前加上了字符串spo。它的意思是这个词表示一个主语、谓语、宾语的关系。
In可以为相同的关系添加5个以上的条目,但顺序不同:
ZADD myindex 0 sop:antirez:matteocollina:is-friend-of
ZADD myindex 0 ops:matteocollina:is-friend-of:antirez
ZADD myindex 0 osp:matteocollina:antirez:is-friend-of
ZADD myindex 0 pso:is-friend-of:antirez:matteocollina
ZADD myindex 0 pos:is-friend-of:matteocollina:antirez现在事情开始变得有趣了,我可以用许多不同的方式查询这个图形。比如,antirez 都是谁的朋友?
ZRANGE myindex "[spo:antirez:is-friend-of:" "[spo:antirez:is-friend-of:\xff" BYLEX
1) "spo:antirez:is-friend-of:matteocollina"
2) "spo:antirez:is-friend-of:wonderwoman"
3) "spo:antirez:is-friend-of:spiderman"或者说,antirez和matteocollina之间的关系是什么?第一个是主语,第二个是宾语?
ZRANGE myindex "[sop:antirez:matteocollina:" "[sop:antirez:matteocollina:\xff" BYLEX
1) "sop:antirez:matteocollina:is-friend-of"
2) "sop:antirez:matteocollina:was-at-conference-with"
3) "sop:antirez:matteocollina:talked-with"通过组合不同的查询,我可以提出奇特的问题。我那些喜欢啤酒、住在巴塞罗那、喝马特奥科利纳酒的朋友都是谁?为了获得这些信息,我从一个spo查询开始查找我的所有朋友。然后,对于我得到的每个结果,我执行一个spo查询来检查他们是否喜欢啤酒,删除那些我找不到这种关系的人。我再次按城市进行过滤。最后,我执行一个ops查询,在我获得的列表中找到matteocollina认为谁是朋友。
为了更好地理解这些理念,请务必查看Matteo Collina关于Levelgraph的幻灯片。
多维指数
更复杂的索引类型是允许同时查询特定范围的两个或多个变量的索引。例如,我可能有一个表示年龄和工资的数据集,我想检索年龄在50到55岁之间、工资在70000到85000之间的所有人。
这个查询可以使用多列索引来执行,但这需要我们选择第一个变量,然后扫描第二个变量,这意味着我们可能要做很多超出所需的工作。可以使用不同的数据结构执行涉及多个变量的此类查询。例如,有时会使用多维树,如k-d树或r-树。在这里,我们将描述一种将数据索引到多维的不同方法,使用一种表示技巧,允许我们以一种非常有效的方式使用Redis字典编排范围来执行查询。
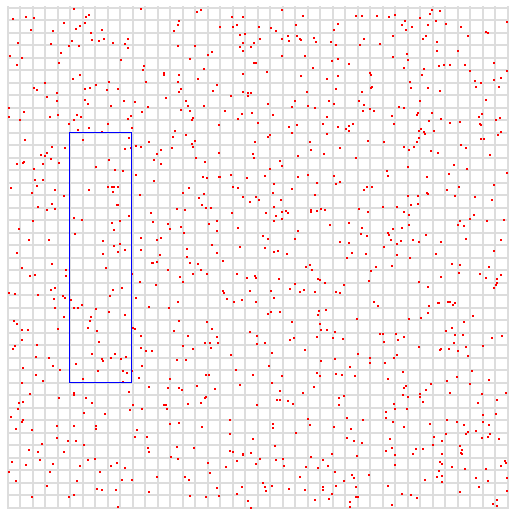
假设在空间中有一些点,它们代表数据样本,其中x和y是坐标。两个变量的最大值都是400。
在下一个图中,蓝框表示我们的查询。我们要的是x在50到100之间,y在100到300之间的所有点。
为了表示能够快速执行这类查询的数据,我们首先用0填充数字。例如,假设我们想把点(10,25 (x,y))加到下标中。假设这个例子中的最大范围是400,我们可以只填充三个数字,所以我们得到:
x = 010
y = 025现在我们要做的是将数字交叉,在x中取最左边的数字,在y中取最左边的数字,以此类推,以创建一个单一的数字:
001205这是我们的索引,但是为了更容易地重建原始表示,如果我们愿意(以空间为代价),我们也可以将原始值作为额外的列添加:
001205:10:25现在,让我们来分析一下这种表示,以及为什么它在范围查询的上下文中很有用。以蓝框的中心为例,即x=75和y=200处。我们可以对这个数字进行编码,就像我们之前做的那样,通过交叉数字,得到:
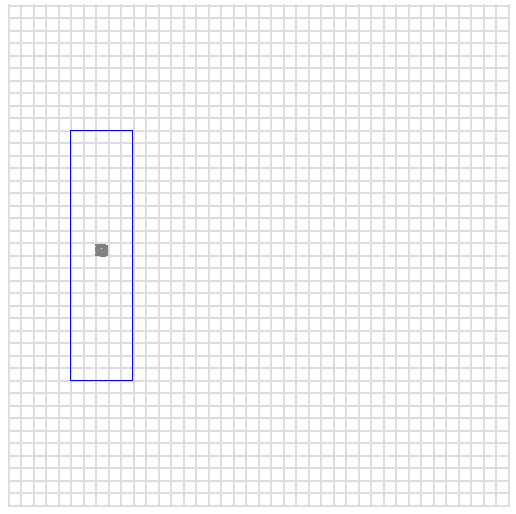
027050如果我们把最后两位数字分别换成00和99会发生什么?我们得到一个字典连续的范围:
027000 to 027099这个映射到的是一个表示所有值的正方形其中x变量在70到79之间,y变量在200到209之间。为了确定这个特定的区域,我们可以在这个区间内写下随机点。
因此,上面的字典查询允许我们轻松地查询图片中特定正方形中的点。然而,对于我们正在搜索的方框来说,正方形可能太小,因此需要太多的查询。所以我们可以做同样的事情,但不是用00和99替换最后两位数字,我们可以对最后四位数字进行替换,获得以下范围:
020000 029999这一次,范围表示x在0到99之间,y在200到299之间的所有点。在这个区间内随机画点可以得到更大的面积。
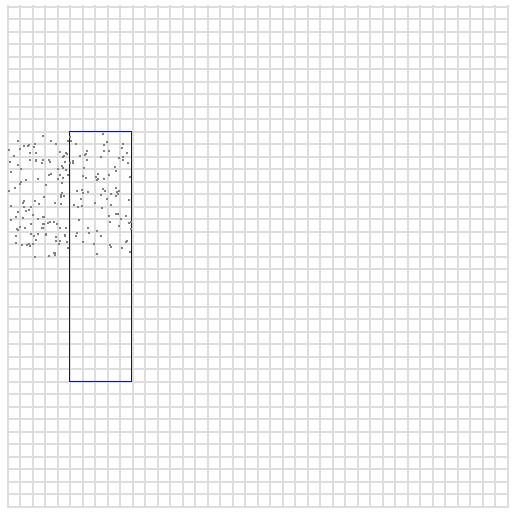
现在我们的区域对于我们的查询来说太大了,我们的搜索框仍然没有完全包含在内。我们需要更大的粒度,但我们可以通过用二进制形式表示数字来轻松获得它。这一次,当我们替换数字时,我们得到的不是十倍大的正方形,而是两倍大的正方形。
我们的数字以二进制形式表示,假设每个变量只需要9位(为了表示值不超过400的数字)将是:
x = 75 -> 001001011
y = 200 -> 011001000因此,通过交叉数字,我们在索引中的表示将是:
000111000011001010:75:200让我们看看当我们代入最后的2,4,6,8…以交错表示的0 0 AD 1的比特:
2位:x在74到75之间,y在200到201之间(范围=2)
4位:x在72到75之间,y在200到203之间(范围=4)
6位:x在72到79之间,y在200到207之间(范围=8)
8位:x在64到79之间,y在192到207之间(范围=16)等等。现在我们有了更好的粒度!如你所见,从索引中替换N位会得到边为2^(N/2)的搜索框。
所以我们要做的是检查搜索框较小的维度,并检查最接近2的这个数的次幂。我们的搜索框是50,100到100,300,所以它的宽为50,高为200。我们取两个中较小的那个,50,然后检查离2最近的几次幂,也就是64。64是2^6,所以我们将使用从交错表示中替换最新12位的索引(因此我们最终只替换每个变量的6位)。
然而,单个方格可能无法覆盖所有搜索,因此我们可能需要更多方格。我们要做的是从搜索框的左下角开始,即50,100,通过将每个数字的后6位替换为0来找到第一个范围。然后我们对右上角做同样的操作。
使用两个简单的嵌套for循环,我们只增加有效位,我们可以找到这两者之间的所有平方。对于每个正方形,我们将两个数字转换为我们的交错表示,并使用转换后的表示作为我们的开始,并使用相同的表示,但最近12位打开作为结束范围。
对于找到的每个正方形,我们执行查询并获取其中的元素,删除搜索框之外的元素。
将其转换为代码很简单。下面是一个Ruby的例子:
def spacequery(x0,y0,x1,y1,exp)
bits=exp*2
x_start = x0/(2**exp)
x_end = x1/(2**exp)
y_start = y0/(2**exp)
y_end = y1/(2**exp)
(x_start..x_end).each{|x|
(y_start..y_end).each{|y|
x_range_start = x*(2**exp)
x_range_end = x_range_start | ((2**exp)-1)
y_range_start = y*(2**exp)
y_range_end = y_range_start | ((2**exp)-1)
puts "#{x},#{y} x from #{x_range_start} to #{x_range_end}, y from #{y_range_start} to #{y_range_end}"
# Turn it into interleaved form for ZRANGE query.
# We assume we need 9 bits for each integer, so the final
# interleaved representation will be 18 bits.
xbin = x_range_start.to_s(2).rjust(9,'0')
ybin = y_range_start.to_s(2).rjust(9,'0')
s = xbin.split("").zip(ybin.split("")).flatten.compact.join("")
# Now that we have the start of the range, calculate the end
# by replacing the specified number of bits from 0 to 1.
e = s[0..-(bits+1)]+("1"*bits)
puts "ZRANGE myindex [#{s} [#{e} BYLEX"
}
}
end
spacequery(50,100,100,300,6)这是一个非常有用的索引策略,将来可能会在Redis中以原生方式实现。目前,好的方面是,这种复杂性可以很容易地封装在一个库中,用于执行索引和查询。Redimension就是这样一个库的例子,它是一个概念证明的Ruby库,使用这里描述的技术在Redis中索引n维数据。
带有负数或浮点数的多维索引
表示负值最简单的方法是使用无符号整数并使用偏移量表示它们,以便在索引时,在转换索引表示中的数字之前,将较小的负整数的绝对值相加。
对于浮点数,最简单的方法可能是将它们转换为整数,方法是将整数乘以10的幂,该幂与您想保留的点后面的位数成正比。
非范围索引
到目前为止,我们检查了按范围或单项查询有用的索引。然而,其他Redis数据结构,如集或列表,可以用来构建其他类型的索引。它们非常常用,但也许我们并不总是意识到它们实际上是一种索引形式。
例如,我可以将对象id索引到Set数据类型中,以便通过SRANDMEMBER使用get random elements操作来检索一组随机对象。当我所需要的只是测试给定的项是否存在或是否具有单个布尔属性时,也可以使用集来检查是否存在。
类似地,可以使用列表将项目索引到固定的顺序。我可以将我所有的项目添加到Redis列表中,并使用RPOPLPUSH旋转列表,使用相同的键名作为源和目标。当我想要以相同的顺序反复地处理一组给定的项时,这是非常有用的。设想一个需要定期刷新本地副本的RSS提要系统。
Redis经常使用的另一个流行索引是一个有上限的列表,其中的项目用LPUSH添加,用LTRIM修剪,以便创建一个仅包含最新遇到的N个项目的视图,以它们被看到的相同顺序。
索引不一致
保持索引更新可能具有挑战性,在几个月或几年的过程中,由于软件错误、网络分区或其他事件,可能会增加不一致。
可以使用不同的策略。如果索引数据在Redis外部,读修复可以是一个解决方案,其中数据在被请求时以惰性方式固定。当我们索引存储在Redis本身的数据时,可以使用SCAN命令家族来从头开始增量地验证、更新或重建索引。
Redis模式示例
通过构建一个Twitter克隆来学习几个Redis模式
本文描述了一个非常简单的Twitter克隆程序的设计和实现,该克隆程序使用PHP编写,并将Redis作为唯一的数据库。编程社区传统上认为键值存储是一种特殊用途的数据库,不能用来代替web应用程序开发中的关系数据库。本文将尝试说明,在键值层之上的Redis数据结构是实现多种应用程序的有效数据模型。
注:本文的原始版本写于2009年,当时Redis发布。当时还不清楚Redis数据模型是否适合编写整个应用程序。5年过去了,现在有很多应用程序使用Redis作为它们的主要存储,所以今天这篇文章的目标是成为Redis新手的教程。您将学习如何使用Redis设计一个简单的数据布局,以及如何应用不同的数据结构。
我们的Twitter克隆版本,叫做Retwis,结构简单,性能非常好,而且不费什么力气就能分布在任意数量的web和Redis服务器上。查看Retwis源代码。
我使用PHP作为示例,因为每个人都可以阅读它。使用Ruby、Python、Erlang等也可以获得相同(或更好)的结果。存在一些克隆版本(但并非所有克隆版本都使用与本教程当前版本相同的数据布局,因此为了更好地理解本文,请坚持使用官方的PHP实现)。
- Retwis-RB是由Daniel Lucraft编写的Retwis到Ruby和Sinatra的移植。
- Retwis-J是Retwis到Java的一个移植版本,使用了由Costin Leau编写的Spring数据框架。它的源代码可以在GitHub上找到,springsource.org上有全面的文档。
什么是键值存储?
key-value存储的本质是在键中存储一些数据(称为值)的能力。只有当我们知道存储该值的特定键时,以后才能检索该值。没有直接的方法可以通过值搜索键。在某种意义上,它就像一个非常大的哈希/字典,但它是持久的,即当应用程序结束时,数据不会消失。因此,例如,我可以使用SET命令将值栏存储在键foo中:
SET foo barRedis永久存储数据,所以如果我后来问“键foo中存储的值是什么?”Redis将回复bar:
GET foo => bar键值存储提供的其他常见操作包括DEL(删除给定的键及其相关值)、SET-if-not-exists(在Redis上称为SETNX)(仅在键不存在时才为键赋值)和INCR(原子地增加存储在给定键中的数字):
SET foo 10
INCR foo => 11
INCR foo => 12
INCR foo => 13原子操作
INCR有一些特别之处。你可能想知道为什么Redis提供这样的操作,如果我们可以自己做一些代码?毕竟,就是这么简单:
x = GET foo
x = x + 1
SET foo x问题是,只要一次只有一个客户端使用foo键,这种递增方式就可以工作。看看如果两个客户端同时访问这个密钥会发生什么:
x = GET foo (yields 10)
y = GET foo (yields 10)
x = x + 1 (x is now 11)
y = y + 1 (y is now 11)
SET foo x (foo is now 11)
SET foo y (foo is now 11)有点不对劲!我们将值增加了两次,但不是从10增加到12,而是键值为11。这是因为使用GET / increment / SET完成的增量不是原子操作。取而代之的是Redis, Memcached,…,是原子实现,服务器将在完成增量所需的时间内负责保护密钥,以防止同时访问。
Redis与其他键值存储的不同之处在于,它提供了类似于INCR的其他操作,可用于对复杂问题进行建模。这就是为什么你可以使用Redis来编写整个web应用程序,而不需要使用SQL数据库这样的数据库,也不会变得疯狂。
键值存储之外:列表
在本节中,我们将看到哪些Redis功能是我们构建Twitter克隆版所需要的。首先要知道的是Redis的值可以不仅仅是字符串。Redis支持列表、集、哈希、排序集、位图和HyperLogLog类型作为值,并且有原子操作来操作它们,因此即使多次访问同一个键也很安全。让我们从列表开始:
LPUSH mylist a (now mylist holds 'a')
LPUSH mylist b (now mylist holds 'b','a')
LPUSH mylist c (now mylist holds 'c','b','a')LPUSH的意思是左推,即在mylist中存储的列表的左侧(或头部)添加一个元素。如果键mylist不存在,它会在PUSH操作之前自动创建一个空列表。可以想象,还有一个RPUSH操作将元素添加到列表的右侧(在尾部)。这对我们的Twitter克隆非常有用。例如,用户更新可以添加到存储在username:updates中的列表中。
当然,还有从list中获取数据的操作。例如,LRANGE返回列表中的一个范围,或者整个列表。
LRANGE mylist 0 1 => c,bLRANGE使用从零开始的索引——即第一个元素是0,第二个元素是1,依此类推。命令参数为LRANGE key first-index last-index。last-index参数可以为负,具有特殊含义:-1是列表的最后一个元素,-2是倒数第二个元素,依此类推。因此,要获得整个列表,请使用:
LRANGE mylist 0 -1 => c,b,a其他重要的操作是返回列表中元素的数量的LLEN,和LTRIM,它类似于LRANGE,但不是返回指定的范围,而是修剪列表,因此它类似于从mylist获取范围,将这个范围设置为新值,但原子地这样做。
Set数据类型
目前我们在本教程中没有使用Set类型,但由于我们使用的是排序集,这是一种更强大的集合版本,所以最好先介绍集合(它本身是一种非常有用的数据结构),然后再介绍排序集。
除了列表之外,还有更多的数据类型。Redis也支持set,它是未排序的元素集合。可以添加、删除和测试成员是否存在,并在不同的set之间执行交集。当然,获取Set中的元素是可能的。举几个例子会更清楚。请记住,SADD是添加到集合操作,SREM是从集合中移除操作,SISMEMBER是测试if成员操作,而SINTER是执行交集操作。其他操作包括SCARD,用于获取Set的基数(元素的数量),以及members,用于返回Set的所有成员。
SADD myset a
SADD myset b
SADD myset foo
SADD myset bar
SCARD myset => 4
SMEMBERS myset => bar,a,foo,b注意,由于set是未排序的元素集合,所以members返回的元素顺序与我们添加它们的顺序不同。当你想按顺序存储时,最好使用列表。更多针对set的操作:
SADD mynewset b
SADD mynewset foo
SADD mynewset hello
SINTER myset mynewset => foo,bSINTER可以返回集合之间的交集,但不限于两个集合。您可以要求4、5或10000集的交集。最后让我们来看看SISMEMBER是如何工作的:
SISMEMBER myset foo => 1
SISMEMBER myset notamember => 0排序集数据类型
排序集类似于集合:元素的集合。然而,在排序集中,每个元素都与一个浮点值相关联,称为元素分数。由于分数的存在,Sorted Set中的元素是有序的,因为我们总是可以通过分数比较两个元素(如果分数恰好相同,则将两个元素作为字符串进行比较)。
就像排序集中的集合一样,它不可能添加重复的元素,每个元素都是唯一的。但是,可以更新元素的分数。
Sorted Set命令以z为前缀,使用示例如下:
ZADD zset 10 a
ZADD zset 5 b
ZADD zset 12.55 c
ZRANGE zset 0 -1 => b,a,c在上面的例子中,我们用ZADD添加了一些元素,然后用ZRANGE检索这些元素。正如您所看到的,元素是按照分数顺序返回的。为了检查一个给定的元素是否存在,如果它存在,我们使用ZSCORE命令:
ZSCORE zset a => 10
ZSCORE zset non_existing_element => NULL排序集是一种非常强大的数据结构,您可以按分数范围、字典顺序、倒序等方式查询元素。要了解更多,请查看官方Redis命令文档中的排序集部分。
哈希数据类型
这是我们在程序中使用的最后一种数据结构,非常容易让人叹气,因为几乎所有编程语言中都有等效的数据结构:哈希值。Redis哈希基本上类似于Ruby或Python哈希,是与值相关的字段的集合:
HMSET myuser name Salvatore surname Sanfilippo country Italy
HGET myuser surname => SanfilippoHMSET可以用来设置散列中的字段,稍后可以用HGET检索这些字段。可以使用HEXISTS检查字段是否存在,或者使用HINCRBY增加哈希字段,等等。
哈希是表示对象的理想数据结构。例如,我们使用哈希来表示我们的Twitter克隆中的用户和更新。
好的,我们刚刚暴露了Redis主数据结构的基础知识,我们准备开始编码!
先决条件
如果您还没有下载Retwis源代码,请立即下载。它包含一些PHP文件和Predis的副本,Predis是我们在本例中使用的PHP客户端库。
你可能需要的另一件事是一个工作的Redis服务器。只需获取源代码,使用make构建,使用。/redis-server运行,就可以开始了。在您的计算机上玩Retwis或运行Retwis完全不需要配置。
数据布局
在使用关系数据库时,必须设计数据库模式,以便我们知道数据库将包含的表、索引等。我们在Redis中没有表格,那么我们需要设计什么呢?我们需要确定需要哪些键来表示对象,以及这些键需要保存什么样的值。
让我们从用户开始。当然,我们需要用用户名、用户标识、密码、关注给定用户的用户集、给定用户关注的用户集等等来表示用户。第一个问题是,我们应该如何识别用户?像在关系DB中一样,一个好的解决方案是用不同的数字标识不同的用户,这样我们就可以将唯一的ID与每个用户关联起来。对该用户的所有其他引用都将通过id完成。通过使用原子INCR操作,创建唯一id非常简单。当我们创建一个新用户时,我们可以这样做,假设这个用户叫“antirez”:
INCR next_user_id => 1000
HMSET user:1000 username antirez password p1pp0注意:您应该在实际应用程序中使用散列密码,为了简单起见,我们将密码以明文形式存储。
我们使用next_user_id键,以便始终为每个新用户获得唯一的ID。然后,我们使用这个唯一ID来命名持有用户数据哈希的键。这是键值存储的常见设计模式!记住这一点。除了已经定义的字段之外,我们还需要更多的东西来完整地定义一个User。例如,有时能够从用户名中获得用户ID是很有用的,因此每次添加用户时,我们也填充用户键,这是一个散列,以用户名为字段,其ID为值。
HSET users antirez 1000乍一看这可能很奇怪,但请记住,我们只能直接访问数据,没有二级索引。不可能告诉Redis返回包含特定值的键。这也是我们的优势。这种新范式迫使我们组织数据,以便所有内容都可以通过主键访问,用关系DB术语来说。
追随者,关注和更新
我们的系统还有另一个核心需求。一个用户可能有关注他的用户,我们称之为他们的追随者。一个用户可能会关注其他用户,我们称之为关注。我们有一个完美的数据结构。这是……集。Sets元素的唯一性,以及我们可以在常数时间内测试其存在的事实,是两个有趣的特性。但是,如果还记得某个用户开始关注另一个用户的时间呢?在我们简单的Twitter克隆版本的增强版本中,这可能是有用的,所以我们不使用简单的Set,而是使用Sorted Set,使用以下用户或追随者用户的用户ID作为元素,并使用创建用户之间关系的unix时间作为我们的分数。
让我们定义键值:
followers:1000 => Sorted Set of uids of all the followers users
following:1000 => Sorted Set of uids of all the following users我们可以添加新的追随者:
ZADD followers:1000 1401267618 1234 => Add user 1234 with time 1401267618我们需要的另一个重要的东西是一个地方,我们可以添加更新显示在用户的主页。稍后我们需要按时间顺序访问这些数据,从最近的更新到最古老的更新,因此最理想的数据结构是List。基本上每一个新的更新都会被lpush到用户更新键中,多亏了LRANGE,我们可以实现分页等等。注意,我们交替使用更新和帖子这两个词,因为更新在某种程度上实际上是“小帖子”。
posts:1000 => a List of post ids - every new post is LPUSHed here.这个列表基本上就是User时间轴。我们将推送她/他自己的帖子id,以及以下用户创建的所有帖子id。基本上,我们将实现一个写扇出。
身份验证
除了身份验证,我们差不多有了用户的所有信息。我们将以一种简单但健壮的方式处理身份验证:我们不想使用PHP会话,因为我们的系统必须准备好轻松地分布在不同的web服务器之间,所以我们将在Redis数据库中保存整个状态。我们所需要的只是一个随机的无法猜到的字符串,用来设置为经过身份验证的用户的cookie,以及一个包含持有该字符串的客户端用户ID的密钥。
我们需要两件事来让这个东西以稳健的方式工作。首先:当前的认证秘密(随机的不可猜测的字符串)应该是User对象的一部分,所以当创建用户时,我们也在其哈希中设置了一个认证字段:
HSET user:1000 auth fea5e81ac8ca77622bed1c2132a021f9此外,我们需要一种将身份验证秘密映射到用户id的方法,因此我们还使用一个auths密钥,它具有将身份验证秘密映射到用户id的Hash类型的值。
HSET auths fea5e81ac8ca77622bed1c2132a021f9 1000为了验证用户身份,我们将执行以下简单的步骤(参见Retwis源代码中的login.php文件):
- 通过登录表单获取用户名和密码。
- 检查用户散列中是否实际存在username字段。
- 如果它存在,我们就有用户id(即1000)。
- 检查user:1000密码是否匹配,如果不匹配,返回错误消息。
- 好的验证!将“fea5e81ac8ca77622bed1c2132a021f9”(user:1000 auth字段的值)设置为“auth”cookie。
这是实际的代码:
include("retwis.php");
# Form sanity checks
if (!gt("username") || !gt("password"))
goback("You need to enter both username and password to login.");
# The form is ok, check if the username is available
$username = gt("username");
$password = gt("password");
$r = redisLink();
$userid = $r->hget("users",$username);
if (!$userid)
goback("Wrong username or password");
$realpassword = $r->hget("user:$userid","password");
if ($realpassword != $password)
goback("Wrong username or password");
# Username / password OK, set the cookie and redirect to index.php
$authsecret = $r->hget("user:$userid","auth");
setcookie("auth",$authsecret,time()+3600*24*365);
header("Location: index.php");每次用户登录时都会发生这种情况,但是我们还需要一个isLoggedIn函数来检查给定用户是否已经通过身份验证。下面是isLoggedIn函数执行的逻辑步骤:
- 从用户那里获取“auth”cookie。当然,如果没有cookie,用户就不会登录。我们将cookie的值称为
。 - 检查auths Hash中是否存在
字段,以及值(用户ID)是多少(在示例中为1000)。 - 为了使系统更加健壮,还需要验证user:1000 auth字段是否匹配。
- 用户通过了身份验证,我们在$ user全局变量中加载了一些信息。
代码比描述简单,可能是:
function isLoggedIn() {
global $User, $_COOKIE;
if (isset($User)) return true;
if (isset($_COOKIE['auth'])) {
$r = redisLink();
$authcookie = $_COOKIE['auth'];
if ($userid = $r->hget("auths",$authcookie)) {
if ($r->hget("user:$userid","auth") != $authcookie) return false;
loadUserInfo($userid);
return true;
}
}
return false;
}
function loadUserInfo($userid) {
global $User;
$r = redisLink();
$User['id'] = $userid;
$User['username'] = $r->hget("user:$userid","username");
return true;
}对于我们的应用程序来说,将loadUserInfo作为一个单独的函数是多余的,但在复杂的应用程序中,这是一个很好的方法。所有身份验证中唯一缺少的是注销。注销时做什么?这很简单,我们只需更改user:1000 auth字段中的随机字符串,从auth散列中删除旧的身份验证秘密,并添加新的秘密。
重要的是:注销过程解释了为什么我们不只是在auths Hash中查找身份验证秘密后对用户进行身份验证,而是根据user:1000 auth字段进行双重检查。真正的身份验证字符串是后者,而auths Hash只是一个身份验证字段,甚至可能是不稳定的,或者,如果程序中有错误或脚本中断,我们甚至可能以auths键中指向相同用户ID的多个条目结束。注销代码如下(logout.php):
include("retwis.php");
if (!isLoggedIn()) {
header("Location: index.php");
exit;
}
$r = redisLink();
$newauthsecret = getrand();
$userid = $User['id'];
$oldauthsecret = $r->hget("user:$userid","auth");
$r->hset("user:$userid","auth",$newauthsecret);
$r->hset("auths",$newauthsecret,$userid);
$r->hdel("auths",$oldauthsecret);
header("Location: index.php");这正是我们所描述的,应该很容易理解。
Updates
更新,也称为帖子,甚至更简单。为了在数据库中创建一个新的帖子,我们这样做:
INCR next_post_id => 10343
HMSET post:10343 user_id $owner_id time $time body "I'm having fun with Retwis"正如你所看到的,每一篇文章都是由一个带有三个字段的散列表示的。拥有帖子的用户ID、发布帖子的时间,以及最后的帖子正文,即实际的状态消息。
在我们创建了一个帖子并获得了帖子ID之后,我们需要在每个关注该帖子作者的用户的时间轴中LPUSH ID,当然也需要在作者本身的帖子列表中LPUSH ID(实际上每个人都在关注自己)。下面是post.php文件,它展示了如何执行此操作:
include("retwis.php");
if (!isLoggedIn() || !gt("status")) {
header("Location:index.php");
exit;
}
$r = redisLink();
$postid = $r->incr("next_post_id");
$status = str_replace("\n"," ",gt("status"));
$r->hmset("post:$postid","user_id",$User['id'],"time",time(),"body",$status);
$followers = $r->zrange("followers:".$User['id'],0,-1);
$followers[] = $User['id']; /* Add the post to our own posts too */
foreach($followers as $fid) {
$r->lpush("posts:$fid",$postid);
}
# Push the post on the timeline, and trim the timeline to the
# newest 1000 elements.
$r->lpush("timeline",$postid);
$r->ltrim("timeline",0,1000);
header("Location: index.php");函数的核心是foreach循环。我们使用ZRANGE获取当前用户的所有关注者,然后循环将LPUSH在每个关注者时间轴列表中推送帖子。
请注意,我们还维护了所有帖子的全局时间轴,以便在Retwis主页上轻松显示每个人的更新。这只需要对时间轴列表执行一个LPUSH。让我们面对它,你不开始认为它是有点奇怪,必须按时间顺序添加使用SQL order BY ?我想是的。
在上面的代码中有一件有趣的事情需要注意:在全局时间轴中执行LPUSH操作后,我们使用了一个名为LTRIM的新命令。这是为了将列表修剪为只有1000个元素。全局时间轴实际上只用于在主页上显示一些帖子,没有必要拥有所有帖子的完整历史。
基本上LTRIM + LPUSH是一种在Redis中创建一个有上限的集合的方法。
方法的更新
现在,我们应该很清楚如何使用LRANGE来获取帖子的范围,并在屏幕上呈现这些帖子。代码很简单:
function showPost($id) {
$r = redisLink();
$post = $r->hgetall("post:$id");
if (empty($post)) return false;
$userid = $post['user_id'];
$username = $r->hget("user:$userid","username");
$elapsed = strElapsed($post['time']);
$userlink = "<a class=\"username\" href=\"profile.php?u=".urlencode($username)."\">".utf8entities($username)."</a>";
echo('<div class="post">'.$userlink.' '.utf8entities($post['body'])."<br>");
echo('<i>posted '.$elapsed.' ago via web</i></div>');
return true;
}
function showUserPosts($userid,$start,$count) {
$r = redisLink();
$key = ($userid == -1) ? "timeline" : "posts:$userid";
$posts = $r->lrange($key,$start,$start+$count);
$c = 0;
foreach($posts as $p) {
if (showPost($p)) $c++;
if ($c == $count) break;
}
return count($posts) == $count+1;
}showPost将简单地转换并以HTML格式打印一个Post,而showUserPosts将获得一系列Post,然后将它们传递给showPosts。
注意:如果帖子列表开始变得非常大,并且我们想要访问列表中间的元素,LRANGE不是非常有效,因为Redis列表是由链表支持的。如果一个系统是为数百万项的深度分页而设计的,那么最好使用排序集。
Following users
这并不难,但我们还没有检查我们如何创建关注/追随者关系。如果用户ID 1000 (antirez)想关注用户ID 5000 (pippo),我们需要创建一个关注者关系和一个追随者关系。我们只需要ZADD调用:
ZADD following:1000 5000
ZADD followers:5000 1000注意相同的模式一遍又一遍。理论上,对于关系数据库,关注者和关注者列表将包含在一个表中,表中包含诸如following_id和follower_id这样的字段。您可以使用SQL查询提取每个用户的关注者或关注者。对于键值DB,事情有点不同,因为我们需要同时设置1000在5000之后,5000在1000之后的关系。这是要付出的代价,但另一方面,访问数据更简单,速度也更快。把这些作为独立的集合可以让我们做一些有趣的事情。例如,使用ZINTERSTORE,我们可以有两个不同用户的关注交集,所以我们可以添加一个功能到我们的Twitter克隆,使它能够很快地告诉你,当你访问别人的个人资料,“你和Alice有34个共同的追随者”,诸如此类的事情。
您可以在follow.php文件中找到设置或删除关注者/追随者关系的代码。
横向可伸缩
亲爱的读者,如果你读到这里,你已经是一个英雄了。谢谢你!在讨论水平扩展之前,有必要检查单个服务器上的性能。Retwis非常快,没有任何类型的缓存。在一个非常慢且负载很重的服务器上,有100个并行客户机发出100000个请求的Apache基准测试显示平均页面浏览量需要5毫秒。这意味着你可以用一个Linux机器每天为数百万用户提供服务,而这个机器慢得像猴子一样……想象一下使用最新硬件的结果。
然而,你不能永远使用一个服务器,你如何扩展键值存储?
Retwis不执行任何多键操作,所以使其可伸缩很简单:你可以使用客户端分片,或者像Twemproxy这样的分片代理,或者即将到来的Redis集群。
要了解更多关于这些主题的信息,请阅读我们关于分片的文档。但是,这里要强调的一点是,在键-值存储中,如果仔细设计,数据集会被分割到许多独立的小键中。与使用语义上更复杂的数据库系统相比,将这些键分布到多个节点更直接、更可预测。