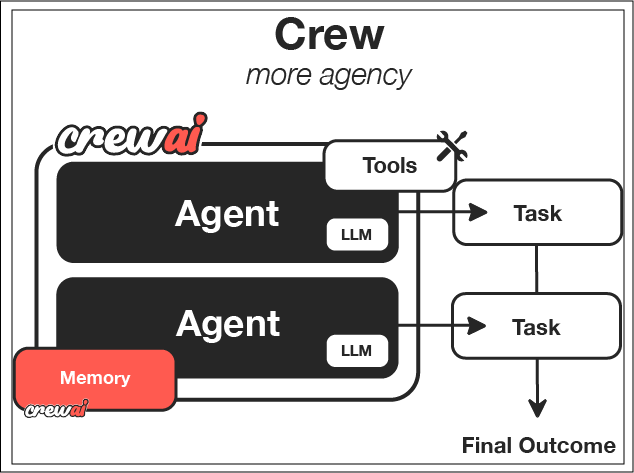
构建您的第一个Crew
本篇是逐步教程,创建一个协同工作的AI团队,共同解决复杂问题。
释放协作AI的力量
想象一下,拥有一支专业的AI代理团队无缝协作,共同解决复杂问题,每个代理都贡献其独特技能以实现共同目标。这就是CrewAI的力量——一个使您能够创建协作AI系统的框架,这些系统可以完成单个AI无法实现的复杂任务。
在本指南中,我们将逐步创建一个研究团队,帮助我们研究和分析一个主题,然后创建一份全面的报告。这个实际示例展示了AI代理如何协作完成复杂任务,但这只是CrewAI可能性的开始。
您将构建和学习的内容
在本指南结束时,您将:
- 创建一个专业的AI研究团队,具有明确的角色和责任
- 编排多个AI代理之间的协作
- 自动化复杂的工作流程,包括信息收集、分析和报告生成
- 构建基础技能,可应用于更雄心勃勃的项目
虽然我们在本指南中构建的是一个简单的研究团队,但相同的模式和技术可以应用于创建更复杂的团队,用于以下任务:
- 多阶段内容创作,拥有专业作家、编辑和事实核查员
- 复杂的客户服务系统,具有分层支持代理
- 自主业务分析师,收集数据、创建可视化并生成见解
- 产品开发团队,进行构思、设计和实施规划
让我们开始构建您的第一个团队!
先决条件
在开始之前,请确保您已:
第1步:创建新的CrewAI项目
首先,让我们使用CLI创建一个新的CrewAI项目。这个命令将设置一个包含所有必要文件的完整项目结构,使您可以专注于定义代理和任务,而不是设置样板代码。
crewai create crew research_crew
cd research_crew这将生成一个具有团队所需基本结构的项目。CLI自动创建:
- 包含必要文件的项目目录
- 代理和任务的配置文件
- 基本的团队实现
- 运行团队的主脚本
第2步:探索项目结构
让我们花点时间了解CLI创建的项目结构。CrewAI遵循Python项目的最佳实践,使您能够轻松维护和扩展代码,随着您的团队变得更加复杂。
research_crew/
├── .gitignore
├── pyproject.toml
├── README.md
├── .env
└── src/
└── research_crew/
├── __init__.py
├── main.py
├── crew.py
├── tools/
│ ├── custom_tool.py
│ └── __init__.py
└── config/
├── agents.yaml
└── tasks.yaml这个结构遵循Python项目的最佳实践,使您能够轻松组织代码。配置文件(YAML格式)与实现代码(Python格式)的分离使您可以轻松修改团队行为,而无需更改底层代码。
第3步:配置您的代理
现在到了有趣的部分——定义您的AI代理!在CrewAI中,代理是具有特定角色、目标和背景故事的专业实体,这些因素塑造了它们的行为。将它们视为戏剧中的角色,每个角色都有自己的个性和目的。
对于我们的研究团队,我们将创建两个代理:
- 一个研究员,擅长查找和组织信息
- 一个分析师,能够解释研究结果并创建富有洞察力的报告
让我们修改agents.yaml文件来定义这些专业代理。确保将llm设置为您正在使用的提供商。
# src/research_crew/config/agents.yaml
researcher:
role: >
{topic}的高级研究专家
goal: >
查找关于{topic}的全面准确信息,
重点关注最新发展和关键见解
backstory: >
您是一位经验丰富的研究专家,擅长
从各种来源查找相关信息。您擅长
以清晰和结构化的方式组织信息,使
复杂的话题对其他人来说易于理解。
llm: provider/model-id # 例如 openai/gpt-4o, google/gemini-2.0-flash, anthropic/claude...
analyst:
role: >
{topic}的数据分析师和报告撰写人
goal: >
分析研究结果并以全面、结构良好的方式创建报告,
以清晰且引人入胜的方式呈现见解
backstory: >
您是一位熟练的分析师,具有数据解释
和技术写作背景。您擅长识别模式
并从研究数据中提取有意义的见解,然后
通过精心制作的报告有效地传达这些见解。
llm: provider/model-id # 例如 openai/gpt-4o, google/gemini-2.0-flash, anthropic/claude...注意每个代理都有独特的角色、目标和背景故事。这些元素不仅仅是描述性的——它们积极地塑造代理如何处理其任务。通过精心设计这些元素,您可以创建具有互补的专业技能和视角的代理。
第4步:定义您的任务
定义了代理后,我们现在需要给它们具体的任务。CrewAI中的任务代表代理将执行的具体工作,具有详细的说明和预期输出。
对于我们的研究团队,我们将定义两个主要任务:
- 一个研究任务,用于收集全面信息
- 一个分析任务,用于创建富有洞察力的报告
让我们修改tasks.yaml文件:
# src/research_crew/config/tasks.yaml
research_task:
description: >
对{topic}进行彻底研究。重点关注:
1. 关键概念和定义
2. 历史发展和最近趋势
3. 主要挑战和机遇
4. 值得注意的应用或案例研究
5. 未来展望和潜在发展
确保以结构化的格式组织您的发现,具有清晰的部分。
expected_output: >
一份全面的研究文档,具有结构良好的部分,涵盖
{topic}的所有请求方面。在相关处包括具体事实、数据
和例子。
agent: researcher
analysis_task:
description: >
分析研究结果并创建关于{topic}的综合报告。
您的报告应该:
1. 以执行摘要开始
2. 包括研究中的所有关键信息
3. 提供对趋势和模式的深刻分析
4. 提供建议或未来考虑因素
5. 以专业、易读的格式编写,具有清晰的标题
expected_output: >
一份关于{topic}的精美专业报告,展示研究结果
并添加分析和见解。报告应该结构良好,
包括执行摘要、主要部分和结论。
agent: analyst
context:
- research_task
output_file: output/report.md注意分析任务中的context字段——这是一个强大的功能,允许分析师访问研究任务的输出。这创建了一个工作流程,其中信息在代理之间自然流动,就像在人类团队中一样。
第5步:配置您的团队
现在是通过配置我们的团队将所有内容整合在一起的时候了。团队是协调代理如何协作完成任务容器。
让我们修改crew.py文件:
# src/research_crew/crew.py
from crewai import Agent, Crew, Process, Task
from crewai.project import CrewBase, agent, crew, task
from crewai_tools import SerperDevTool
from crewai.agents.agent_builder.base_agent import BaseAgent
from typing import List
@CrewBase
class ResearchCrew():
"""用于全面主题分析和报告的研究团队"""
agents: List[BaseAgent]
tasks: List[Task]
@agent
def researcher(self) -> Agent:
return Agent(
config=self.agents_config['researcher'], # type: ignore[index]
verbose=True,
tools=[SerperDevTool()]
)
@agent
def analyst(self) -> Agent:
return Agent(
config=self.agents_config['analyst'], # type: ignore[index]
verbose=True
)
@task
def research_task(self) -> Task:
return Task(
config=self.tasks_config['research_task'] # type: ignore[index]
)
@task
def analysis_task(self) -> Task:
return Task(
config=self.tasks_config['analysis_task'], # type: ignore[index]
output_file='output/report.md'
)
@crew
def crew(self) -> Crew:
"""创建研究团队"""
return Crew(
agents=self.agents,
tasks=self.tasks,
process=Process.sequential,
verbose=True,
)在这段代码中,我们正在:
- 创建研究员代理并为其配备SerperDevTool以搜索网络
- 创建分析师代理
- 设置研究和分析任务
- 配置团队按顺序运行任务(分析师将等待研究员完成)
这就是魔力所在——仅用几行代码,我们就定义了一个协作AI系统,其中专业代理在协调的过程中协同工作。
第6步:设置您的主脚本
现在,让我们设置运行团队的主脚本。这是我们提供希望团队研究的具体主题的地方。
#!/usr/bin/env python
# src/research_crew/main.py
import os
from research_crew.crew import ResearchCrew
# 如果输出目录不存在则创建
os.makedirs('output', exist_ok=True)
def run():
"""
运行研究团队。
"""
inputs = {
'topic': '医疗保健中的人工智能'
}
# 创建并运行团队
result = ResearchCrew().crew().kickoff(inputs=inputs)
# 打印结果
print("\n\n=== 最终报告 ===\n\n")
print(result.raw)
print("\n\n报告已保存到output/report.md")
if __name__ == "__main__":
run()这个脚本准备环境,指定我们的研究主题,并启动团队的工作。CrewAI的力量在这段代码的简单性中显而易见——管理多个AI代理的所有复杂性都由框架处理。
第7步:设置环境变量
在项目根目录中创建一个.env文件,包含您的API密钥:
SERPER_API_KEY=your_serper_api_key
# 在这里也添加您提供商的API密钥。有关配置您选择的提供商的详细信息,请参阅LLM设置指南。您可以从Serper.dev获取Serper API密钥。
第8步:安装依赖项
使用CrewAI CLI安装所需的依赖项:
crewai install这个命令将:
- 从项目配置中读取依赖项
- 如果需要则创建虚拟环境
- 安装所有必需的包
第9步:运行您的团队
现在到了激动人心的时刻——是时候运行您的团队,亲眼见证AI协作!
crewai run当您运行此命令时,您将看到您的团队活跃起来。研究员将收集关于指定主题的信息,然后分析师将基于该研究创建一份全面的报告。您将实时看到代理的思考过程、行动和输出,它们协同工作完成任务。
第10步:审查输出
团队完成工作后,您将在output/report.md文件中找到最终报告。报告将包括:
- 执行摘要
- 关于主题的详细信息
- 分析和见解
- 建议或未来考虑因素
花点时间欣赏您所取得的成就——您已经创建了一个系统,其中多个AI代理协作完成复杂任务,每个代理贡献其专业技能,产生任何单个代理无法单独实现的更好结果。
探索其他CLI命令
CrewAI提供了其他几个有用的CLI命令用于处理团队:
# 查看所有可用命令
crewai --help
# 运行团队
crewai run
# 测试团队
crewai test
# 重置团队记忆
crewai reset-memories
# 从特定任务重放
crewai replay -t <task_id>可能的艺术:超越您的第一个团队
您在本指南中构建的只是开始。您学到的技能和模式可以应用于创建日益复杂的AI系统。以下是一些您可以扩展这个基础研究团队的方法:
扩展您的团队
您可以向团队添加更多专业代理:
- 一个事实核查员,用于验证研究结果
- 一个数据可视化专家,用于创建图表和图形
- 一个领域专家,具有特定领域的专业知识
- 一个评论家,用于识别分析中的弱点
添加工具和功能
您可以通过额外工具增强您的代理:
- 网络浏览工具,用于实时研究
- CSV/数据库工具,用于数据分析
- 代码执行工具,用于数据处理
- 外部服务的API连接
创建更复杂的工作流程
您可以实现更复杂的过程:
- 分层过程,其中经理代理将工作委派给工作代理
- 具有反馈循环的迭代过程,用于改进
- 并行过程,其中多个代理同时工作
- 基于中间结果调整的动态过程
应用于不同领域
相同的模式可以应用于创建以下领域的团队:
- 内容创作:作家、编辑、事实核查员和设计师协同工作
- 客户服务:分类代理、专家和质量控制协同工作
- 产品开发:研究员、设计师和规划师协作
- 数据分析:数据收集员、分析师和可视化专家协同工作
后续步骤
既然您已经构建了第一个团队,您可以:
- 尝试不同的代理配置和个性
- 尝试更复杂的任务结构和工作流程
- 实现自定义工具,为您的代理提供新功能
- 将您的团队应用于不同主题或问题领域
- 探索CrewAI流程以获得更高级的程序化编程工作流程
恭喜!您已成功构建了第一个CrewAI团队,可以研究和分析您提供的任何主题。这一基础经验为您配备了创建日益复杂的AI系统的技能,这些系统可以通过协作智能解决复杂的多阶段问题。
样例研究报告
输入主题:how to make a AI Agent by python
选择模型:claude-3-5-sonnet-20240620
输出结果:
2025年使用Python构建AI代理
1. 现代代理框架
到2025年,AI代理开发生态系统已经发生了巨大变化,几个框架因其能够简化复杂的代理创建过程而脱颖而出。
LangChain 2.0已经成为行业标准,特别是其代理执行器组件(Agent Executor),它能够以最少的编码需求协调复杂的代理工作流。该框架提供了一套全面的预构建组件,用于推理、规划和工具利用,使即使AI经验有限的开发者也能轻松使用。
AutoGPT在需要最少人工干预即可运行的完全自主代理方面持续受欢迎。其递归自我改进能力使代理能够随时间不断优化其解决问题的方法。
BabyAGI提供了一个专注于任务管理和优先级排序的轻量级替代方案,使其在资源效率至关重要的项目中成为理想选择。其简单的架构使其特别适合教育用途和快速原型开发。
AgentGPT提供了更加用户友好的方法,具有代理设计的可视化界面,吸引了非技术用户,同时仍然提供Python API以进行更深度的定制。
这些框架的主要优势在于其模块化架构,允许开发者根据特定用例混合和匹配组件。例如,您可以将LangChain的推理模块与AgentGPT的可视化工具相结合,创建针对特定领域的混合解决方案。
2. 基础模型集成
2025年的AI代理主要构建在强大的基础模型之上,这些模型为复杂推理和交互提供了必要的认知能力。集成过程通过专门的Python库已经显著简化。
通过OpenAI的Python SDK可以访问GPT-5,该SDK现在包括增强的流媒体能力和对模型参数的更精细控制。最新的API允许在执行过程中动态调整温度参数,使代理能够根据上下文需求在创造性和精确响应之间进行调节。
通过Anthropic的Python客户端可访问的Claude 3.5,在需要卓越指令遵循和伦理防护的应用程序中获得了广泛采用。其显著特点是能够在极长的对话中保持上下文,使其成为复杂的多会话代理交互的理想选择。
通过Meta的Python包或HuggingFace Transformers可用的Llama 4,提供了一个性能与专有模型相当的开源权重替代方案。其轻量级变体在计算资源有限的边缘部署场景中特别有价值。
通过Google的Vertex AI Python SDK可访问的Gemini Ultra,在多模态推理任务中表现出色。其Python集成包括用于处理复杂视觉-语言推理场景的专门模块。
有效代理开发的关键区别不仅在于模型选择本身,还在于开发者如何构建提示和链接交互。大多数成功的实现采用复杂的提示工程技术,例如:
- 建立明确代理身份的基于角色的提示
- 在提示中提供示例的少样本学习方法
- 鼓励逐步推理的思维链技术
- 将复杂问题分解为可管理部分的任务分解策略
Python的生态系统通过标准化接口促进与这些模型的无缝集成,使开发者能够轻松实验不同的基础模型作为其代理的底层"大脑"。
3. 工具使用和函数调用
现代AI代理的实用性很大程度上来自于它们与外部工具和系统交互的能力。到2025年,这一能力通过结构化函数调用机制得到了改进,允许模型直接使用适当参数调用Python函数。
LangChain的工具API已经成为工具集成的事实标准,提供了基于装饰器的方法来注册Python函数作为代理工具。该系统处理参数验证、错误管理和结果格式化,显著降低了工具创建的复杂性:
@tool
def search_database(query: str, limit: int = 10) -> List[Dict]:
"""在知识数据库中搜索相关信息。"""
# 此处为实现细节OpenAI的函数调用提供了类似的功能,专门为其模型进行了优化。其基于JSON架构的方法确保了严格的类型检查和验证,最小化了模型尝试使用工具时的幻觉风险:
tools = [
{
"type": "function",
"function": {
"name": "search_database",
"description": "在知识数据库中搜索相关信息",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string"},
"limit": {"type": "integer", "default": 10}
},
"required": ["query"]
}
}
}
]2025年最复杂的代理实现使用覆盖常见功能的工具库:
- 用于信息收集的网络搜索和浏览工具
- 用于结构化数据检索和存储的数据库连接器
- 用于第三方服务集成的API客户端
- 用于文档处理的文件系统工具
- 用于动态解决问题的代码执行环境
- 用于数据展示的可视化工具
这些工具通常组织在注册表中,代理可以根据任务要求动态发现和利用。Python的内省能力在这里特别有价值,允许代理检查函数签名和文档以了解工具功能。
错误处理也变得更加复杂,代理能够在工具未能按预期执行时实现重试逻辑、参数细化和回退策略。
4. 检索增强生成(RAG)
RAG系统已经成为有效AI代理的基石,提供了克服大型语言模型固有的幻觉问题所必需的事实基础。到2025年,RAG实现在复杂性和效率方面都有了显著发展。
向量数据库构成了现代RAG系统的骨干,通过Python集成提供了几种选择:
- Pinecone提供基于云的向量搜索,支持Python SDK,适用于大容量应用
- Weaviate提供了功能更丰富的方法,具有混合搜索能力和基于模式的数据组织
- Chroma提供了可以完全在Python应用程序中运行的嵌入式解决方案
- FAISS在需要处理大型向量集合的性能关键应用中仍然很受欢迎
分块策略已经超越了简单的文本分割,发展到上下文感知的方法:
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 具有重叠的现代上下文感知分块
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len,
separators=["\n\n", "\n", " ", ""]
)混合检索器已经成为标准,结合多种检索方法以提高准确性:
from langchain.retrievers import BM25Retriever, EnsembleRetriever
from langchain.vectorstores import Chroma
# 基于向量的语义搜索
vector_retriever = Chroma(embedding_function=embeddings).as_retriever()
# 基于关键字的搜索
keyword_retriever = BM25Retriever.from_documents(documents)
# 组合混合方法
hybrid_retriever = EnsembleRetriever(
retrievers=[vector_retriever, keyword_retriever],
weights=[0.7, 0.3]
)2025年的先进RAG系统还实现了:
- 重新表述用户查询以优化检索的查询转换技术
- 首先识别相关文档集群,然后在其中搜索的分层检索
- 结合文档属性(如时效性、源可靠性和主题分类)的元数据过滤
- 使用计算更密集的技术进一步优化初始检索结果的重排序系统
- 从单个用户查询生成多个搜索变体以提高召回率的多查询方法
最复杂的代理实现使用自适应RAG,根据任务上下文和先前查询性能动态调整检索参数,持续优化信息检索过程。
5. 多模态能力
2025年的AI代理通常处理和生成多种模态的内容,创造了更自然和更通用的交互可能性。Python丰富的库生态系统使得多模态集成相对简单。
OpenCV对于图像处理任务仍然是必不可少的,现在具有AI加速操作和与神经处理管道的无缝集成:
import cv2
# 具有AI加速图像分析的现代OpenCV
image = cv2.imread('input_image.jpg')
processed = cv2.dnn.processUsingModel(image, 'vision_model.onnx')PyTorch Vision为视觉分析任务提供了预训练模型,从目标检测到场景理解,具有简化的代理集成接口:
from torchvision.models import resnet50, ResNet50_Weights
# 使用标准化预处理加载视觉模型
weights = ResNet50_Weights.DEFAULT
model = resnet50(weights=weights)
preprocess = weights.transforms()LangChain的多模态扩展为结合文本和视觉处理提供了标准化接口:
from langchain_multimodal import MultiModalChain
# 创建处理文本和图像的代理
agent = MultiModalChain(
llm=text_foundation_model,
vision_model=visual_foundation_model,
tools=[image_analyzer, text_processor]
)现代多模态代理通常实现:
- 用于图像分析和描述的视觉语言处理
- 用于处理结构化表单和表格的文档理解能力
- 用于语音处理的音频转录和分析
- 用于时序视觉内容分析的视频理解
- 包括文本、图像和数据可视化的多模态输出生成
2025年的关键进步是统一处理管道,允许无缝处理多种模态而无需特定于模式的代码分支。Python框架现在提供抽象层,跨模态标准化输入和输出,简化代理开发。
例如,客户服务代理可能同时处理产品的照片、客户对问题的文本描述以及存储在数据库中的他们的账户历史——所有这些都通过一个一致的接口处理,该接口处理不同数据类型的复杂性。
6. 内存管理
复杂的内存系统已经成为实现AI代理连贯长期交互和学习能力的关键。2025年的特点是分层内存架构,通过Python强大的数据管理工具实现。
现代代理内存通常由几个专门系统组成:
- 实现为内存中Python数据结构的短期工作内存,用于即时上下文
- 用于存储对话历史和交互经验的情景记忆
- 用于积累事实知识和学习信息的语义记忆
- 用于跟踪学习到的任务模式和成功方法的程序记忆
带有像SQLAlchemy这样的Python ORM的PostgreSQL已经成为持久内存存储的流行选择,因为它结合了关系结构和JSON处理能力:
from sqlalchemy import Column, String, JSON
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class AgentMemory(Base):
__tablename__ = 'agent_memories'
id = Column(String, primary_key=True)
type = Column(String) # episodic, semantic, procedural
content = Column(JSON)
embedding = Column(ARRAY(Float))
metadata = Column(JSON)
created_at = Column(DateTime)
last_accessed = Column(DateTime)向量数据库也用于基于相似性的内存检索,允许代理基于概念关系而不仅仅是显式键访问相关记忆:
from langchain.vectorstores import Pinecone
from langchain.embeddings import OpenAIEmbeddings
# 创建向量化内存存储
embeddings = OpenAIEmbeddings()
memory = Pinecone(
embedding_function=embeddings,
index_name="agent_episodic_memory",
text_key="content"
)
# 检索与当前上下文相似的记忆
relevant_memories = memory.similarity_search(current_context, k=5)最复杂的内存实现包括:
- 定期总结和整合信息的内存整合过程
- 基于相关性和近期性优先保留内存的遗忘机制
- 分析过去交互以提取模式和见解的反思能力
- 将情感维度与记忆关联以实现更人性化的记忆唤起的情感标记
- 用于协作学习环境的跨代理内存共享
这些内存系统使代理能够在扩展交互中保持上下文,从过去经验中学习,并通过积累知识逐步建立领域专业知识。
7. 自主规划和推理
2025年的AI代理采用复杂的推理和规划技术,使它们能够以类似人类的解决问题能力处理复杂任务。这些系统将高层目标分解为可管理的步骤,并根据新出现的调整计划。
思维树(ToT)实现允许代理同时探索多个推理路径:
def tree_of_thoughts(problem, evaluation_fn, max_depth=3, beam_width=5):
initial_thoughts = generate_diverse_thoughts(problem, n=beam_width)
frontier = [(thought, [thought], 0) for thought in initial_thoughts]
best_solution = None
best_score = float('-inf')
while frontier:
current_thought, path, depth = frontier.pop(0)
if depth == max_depth:
score = evaluation_fn(path)
if score > best_score:
best_score = score
best_solution = path
continue
next_thoughts = generate_next_thoughts(current_thought, problem, path)
next_thoughts = select_top_k(next_thoughts, evaluation_fn, k=beam_width)
for thought in next_thoughts:
frontier.append((thought, path + [thought], depth + 1))
return best_solutionReAct(推理+行动)模式在一个集成循环中结合推理和工具使用:
while not task_complete:
# 推理:分析当前状态并确定下一步
reasoning = agent.reason(current_state)
# 行动:基于推理执行行动
action = agent.decide_action(reasoning)
# 观察:从环境中收集反馈
observation = execute_action(action)
# 用新信息更新状态
current_state = update_state(current_state, observation)
# 反思:评估进度并在需要时调整方法
reflection = agent.reflect(current_state, reasoning, action, observation)
if reflection.suggests_plan_change:
adjust_approach(reflection)专门框架使这些模式更容易访问:
- AgentFlow提供将函数转换为代理推理步骤的Python装饰器
- TaskTree实现具有依赖跟踪的分层任务分解
- ReflectiveExecutor为标准代理工作流添加自我评估能力
最先进的规划系统实现了:
- 基于复杂性将目标分解为子任务的动态任务分解
- 确定计算或时间需求的资源估算
- 同时探索多个方法的并行推理线程
- 从无生产力的推理路径恢复的回溯能力
- 优化规划过程本身的元推理
这些规划和推理系统使代理能够处理使用简单预定义工作流不可能解决的开放性问题。结构化推理模式与Python实现灵活性的结合,创造了能够适应新情况同时保持连贯目标导向行为的代理。
8. 评估和反馈循环
强大的评估系统对于开发可靠的AI代理和确保其持续改进至关重要。到2025年,Python生态系统提供了复杂的评估和反馈集成工具。
RavenSuite提供跨多个维度的全面代理评估:
from ravensuite import AgentEvaluator
evaluator = AgentEvaluator(
dimensions=[
"task_completion", # 任务完成度
"factual_accuracy", # 事实准确性
"reasoning_quality", # 推理质量
"tool_usage_efficiency", # 工具使用效率
"safety_alignment" # 安全对齐
]
)
evaluation_results = evaluator.evaluate(
agent=my_agent,
test_suite="standard_benchmark",
num_runs=100
)
# 识别改进机会
improvement_areas = evaluation_results.get_weak_points(threshold=0.7)AgentBench专注于常见代理任务的标准化基准测试:
from agentbench import Benchmark, TaskSuite
# 创建定制基准测试套件
benchmark = Benchmark(
task_suites=[
TaskSuite.INFORMATION_RETRIEVAL, # 信息检索
TaskSuite.PLANNING, # 规划
TaskSuite.TOOL_USE, # 工具使用
TaskSuite.REASONING # 推理
],
metrics=["success_rate", "efficiency", "accuracy"] # 成功率、效率、准确性
)
# 运行基准测试并分析结果
results = benchmark.run(agent=my_agent)
performance_profile = results.generate_report()来自人类反馈的强化学习(RLHF)管道通过Python框架变得更加可访问:
from rlhf_framework import FeedbackCollector, PreferenceModel, AgentOptimizer
# 收集人类反馈
feedback_collector = FeedbackCollector(
interface_type="web",
feedback_dimensions=["helpfulness", "accuracy", "safety"] # 有用性、准确性、安全性
)
# 从反馈数据训练偏好模型
preference_model = PreferenceModel.train(
feedback_data=feedback_collector.collected_data,
model_type="ranking"
)
# 基于偏好模型优化代理行为
optimizer = AgentOptimizer(preference_model=preference_model)
improved_agent = optimizer.optimize(
original_agent=my_agent,
optimization_steps=1000
)综合评估系统通常包括:
- 自动化测试套件