内容纲要
Flink官网
Flink项目理念
Apache Flink 是为分布式、高性能、随时可用以及准确的流处理应用程序打造的开源流处理框架。Flink 用同一种技术实现了两种功能。
Flink不仅能提供同时支持高吞吐和 exactly-once 语义的实时计算,还能提供批量数据处理。
Flink 的优势
- 它拥有诸多重要的流式计算功能。

Flink起源
Flink 起源于 Stratosphere 项目,Stratosphere 是在2010~2014 年由 3 所地处柏林的大学和欧洲的一些其他的大学共同进行的研究项目。当时,这个项目已经吸引了一个较大的社区,一部分原因是它出现在了若干公共开发者研讨会上,比如在柏林举办的BerlinBuzzwords,以及在科隆举办的 NoSQL Matters,等等。强大的社区基础是这个项目适合在 Apache 软件基金会中孵化的一个原因。
2014 年 4 月,Stratosphere 的代码被复制并捐献给了 Apache 软件基金会,参与这个孵化项目的初始成员均是 Stratosphere 系统的核心开发人员。不久之后,创始团队中的许多成员离开大学并创办了一个公司来实现 Flink 的商业化,他们为这个公司取名为 data Artisans。在孵化期间,为了避免与另一个不相关的项目重名,项目的名称也发生了改变。Flink 这个名字被挑选出来,以彰显这种流处理器的独特性:在德语中,flink 一词表示快速和灵巧。
项目采用一只松鼠的彩色图案作为 logo,这不仅因为松鼠具有快速和灵巧的特点,还因为柏林的松鼠有一种迷人的红棕色。

Flink的核心特性
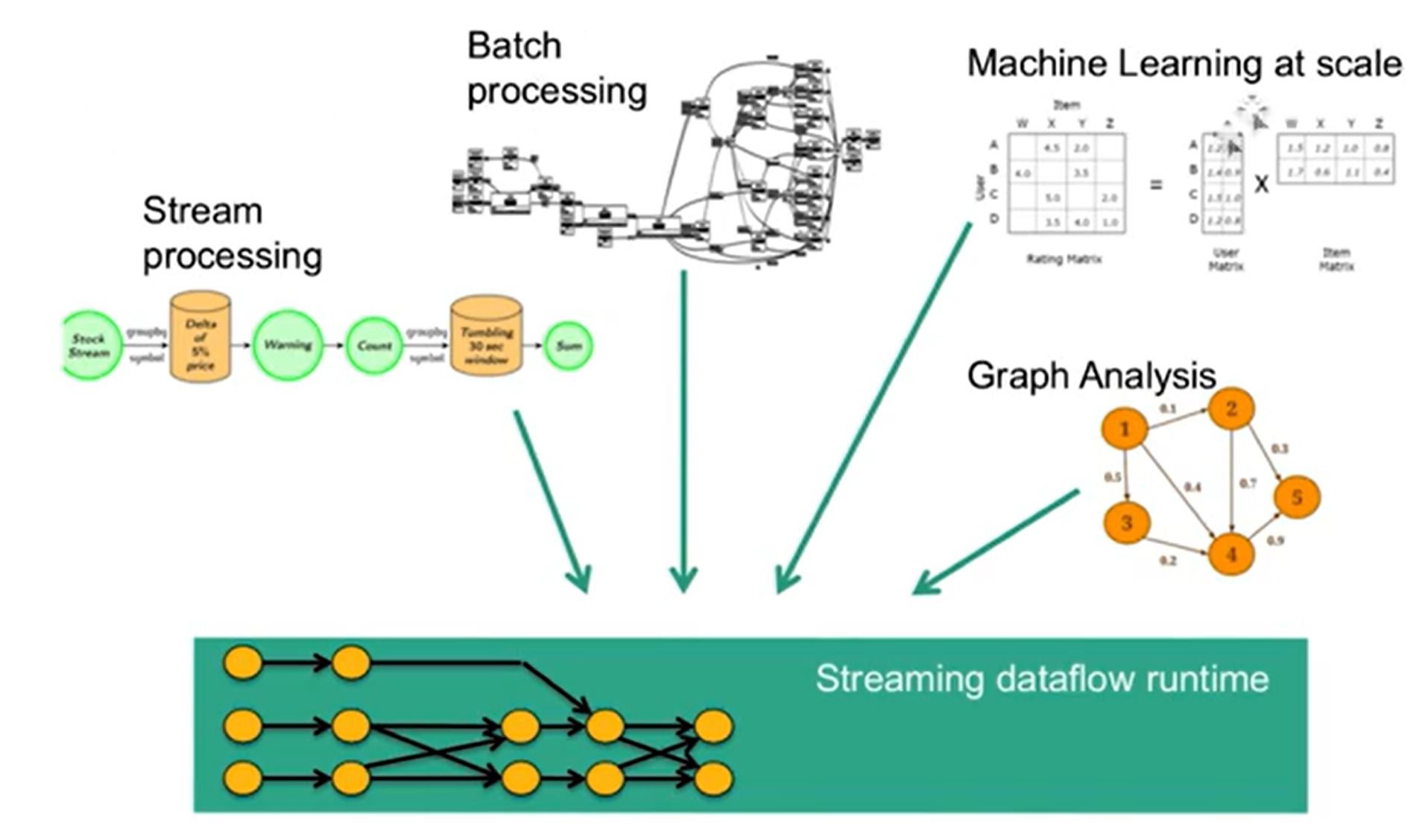
- 统一数据处理组件栈,处理不同类型的数据需求(Batch, Stream, Machine Learning, Graph)
- 支持事件事件(Event Time),接入时间(Ingestion Time),处理时间(Processing Time)等时间概念。

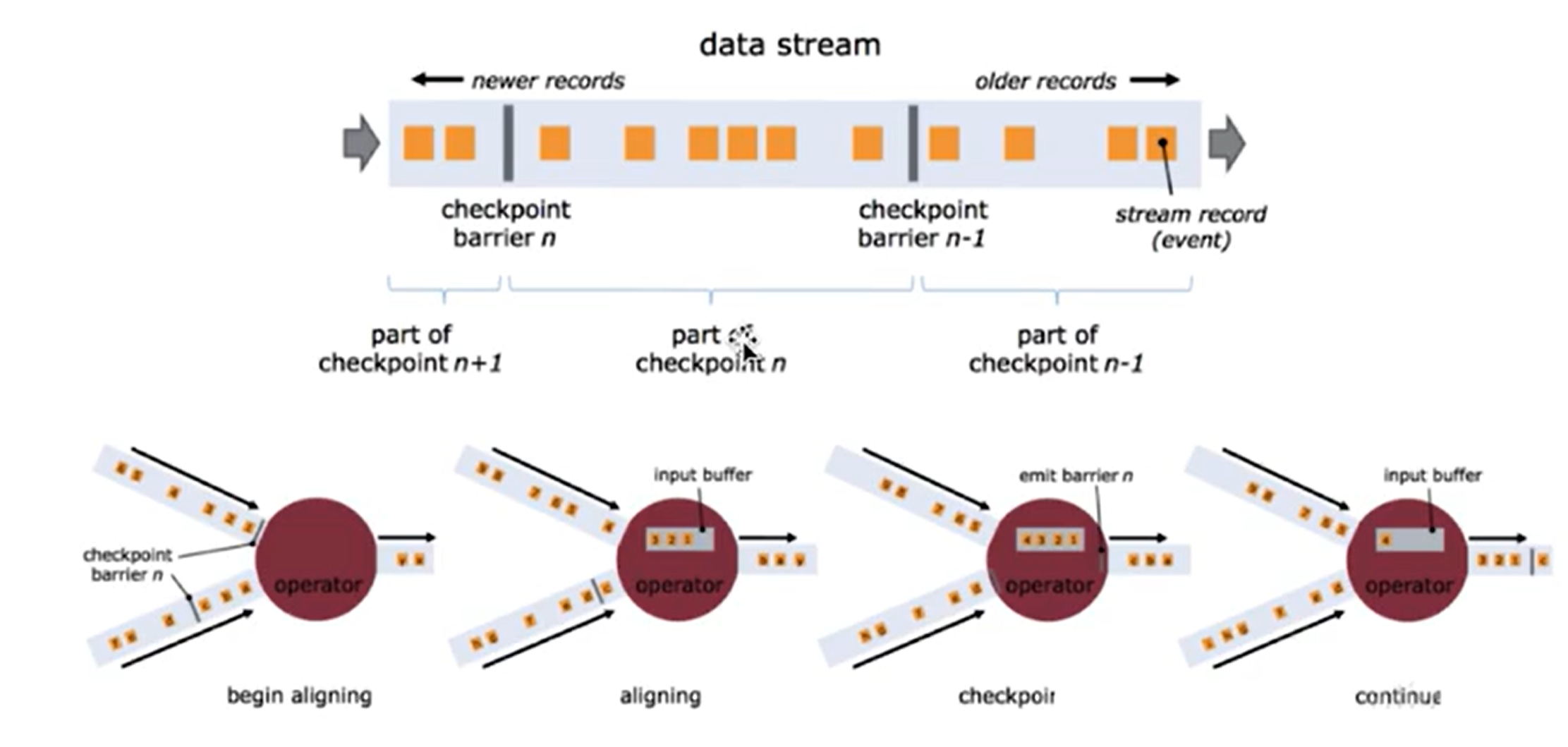
- 基于轻量级分布式快照(Snapshot)实现的容错
- 支持有状态计算
- SUpport for every large state
- querable state 支持
- 灵活的state-backkend(HDFS,内存,RocksDB)

- 支持高度灵活的窗口(Window)操作

参考资料
- 《Flink基础教程》 埃伦·弗里德曼