ChatGPT,可能是2022年年底最时髦的一个词。人们在大街小巷、朋友圈、各大网站都在传播它,其火爆程度让人们感到震撼和惊奇。ChatGPT的火热在全球掀起了一股AI的浪潮,让稍显沉寂的AI行业重新走向了风口浪尖。ChatGPT的横空出世,让大众看到AI在文本生成、文本摘要、多轮对话甚至生成代码等方面的能力有了质的飞跃。
释义1.1 ChatGPT
ChatGPT(全称:Chat Generative Pre-trained Transformer),美国OpenAI研发的聊天机器人程序,于2022年11月30日发布。ChatGPT是人工智能技术驱动的自然语言处理工具,它能够通过理解和学习人类的语言来进行对话,还能根据聊天的上下文进行互动,真正像人类一样聊天交流,甚至能完成撰写邮件、视频脚本、文案、代码,翻译、写论文等任务。
——百度百科
什么是ChatGPT
ChatGPT使用了GPT(Generative Pre-trained Transformer,生成式预训练变换模型)技术,可以和用户进行自然对话,为用户提供各种信息。它是一种强大的自然语言处理模型,可以根据大量的文本数据进行预训练,并生成类似于人类使用的自然语言的文本。在ChatGPT中,这种技术被用于生成聊天机器人的回复,从而实现智能对话的功能。
ChatGPT的一大特点是它可以进行个性化的聊天,因为它会根据用户的输入和历史记录进行学习和调整。这意味着,随着用户使用时间和输入内容的增加,ChatGPT的回复将变得越来越准确和个性化。当用户向ChatGPT发送消息时,它会使用自然语言处理技术来理解消息的内容和意图。然后,ChatGPT将使用预训练模型生成对话回复,并将其返回给用户。
ChatGPT还可以使用上下文进行学习,例如,如果用户问了一个问题,在随后的对话中提供了更多的信息,ChatGPT将使用这些信息来生成更准确的回复。这种学习过程是持续的,因此ChatGPT可以不断地改进其对话回复的质量。
五大特点
作为当前最先进的大型语言模型之一,ChatGPT已经引起了人们的广泛关注和研究。它的出现革命性地提高了智能对话系统的精度、速度和语言生成能力,对智能对话技术的发展起到了巨大的推动作用,并且给人们带来了持续的震撼。
那么,ChatGPT的强大之处究竟在哪里呢?到底是什么带来了这种震撼?又是什么能让这种震撼持续?这让很多人充满了疑惑。总的来讲,这种震撼源于ChatGPT的五大特点,如图1.1所示,即多轮对话、多语言支持、可扩展性强、智能推荐和自我学习。
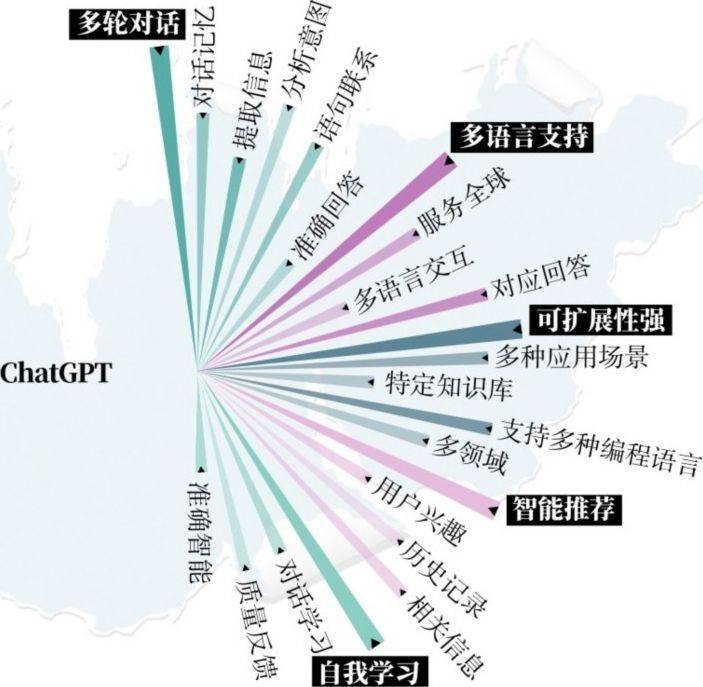
图1.1 ChatGPT的特点及涉及方向
(1)多轮对话。
ChatGPT能够处理复杂的对话场景,实现对话的延续和对上下文的理解,通过存储和更新对话历史记录来实现多轮对话。它可以根据先前的问题和回答来理解上下文,并生成更加准确的回答。同时,ChatGPT使用自然语言处理技术来解析和理解用户的输入,从而更好地理解用户的意图。
ChatGPT的多轮对话特点使其能够实现更加自然和流畅的对话体验,可用于多种场景,如智能客服、聊天机器人、语音助手等。
(2)多语言支持。
ChatGPT可以处理多语言的文本输入,支持多语言的文本生成和对话,并提供多语言的API(应用程序编程接口),能够应用于多语言环境中,处理不同语言之间的交互和文本生成需求。
ChatGPT使用多语言数据集进行训练,采用迁移学习技术,能够将在一种语言上的学习应用到其他语言上,从而加快在多语言环境下的部署。ChatGPT的多语言特点使其具有广泛的应用价值,能够应用于多种语言的程序中,为用户提供更好的多语言交互体验。
(3)可扩展性强。
ChatGPT支持多种编程语言、应用场景和模型定制。它可以应用于多种场景,如智能客服、机器翻译、自然语言生成等,处理各种语言和专业领域的输入和输出。ChatGPT通过对数据进行精细化标注、调整模型参数、增加训练数据等方式来提高模型的精度和泛化能力。它依赖于强大的计算机集群,可以根据需要调整计算资源,提高模型的训练和推理速度,从而支持高并发、大规模的应用场景。这些特点使得ChatGPT具有更广泛的应用价值,可以满足不同应用场景下的需求。
(4)智能推荐。
ChatGPT具有智能推荐的特点。这个模型可以自动处理和理解海量文本数据,通过学习寻找其规律和关系,以便提供有用的建议,再根据用户提供的信息来推荐更加准确和符合用户期望的内容。此外,通过不断学习和更新,ChatGPT还可以不断地提高其推荐的准确性和效率,并且可以自动适应不同的应用场景和用户需求。
(5)自我学习。
ChatGPT是基于OpenAI发布的GPT模型,该模型具有强大的学习能力。它可以理解和处理规模庞大的自然语言数据,并从中发现和总结文本中的规律和模式,从而学习自然语言的语法、语义规则,不断地提高自身性能。GPT的学习能力源于其内部的神经网络结构,它可以通过反向传播算法不断地调整和优化自身的参数和权重。另外,GPT模型还可以通过迁移学习和增量学习的方法,将之前学习的知识和模式迁移到新的任务或领域中,从而更快地适应新任务和新场景下传输给模型的数据。
总的来说,与传统聊天机器人相比,ChatGPT具有更多优势。它可以以一种更加自然的方式生成回复,让用户获得更真实的对话体验。这是因为ChatGPT是一种基于深度学习的大型语言模型,它可以处理大量的自然语言数据,从中学习语言的规律和模式,并生成类似人类自然语言的回复。这使得人机对话更加流畅和自然,同时也使用户更容易理解和接受回复。
缔造传奇:OpenAI
ChatGPT是由OpenAI创造的,并且深深地影响着世界,用“传奇”两个字来形容也不为过。那么OpenAI究竟是怎么样的存在呢?它为什么可以做出ChatGPT这么好的产品呢?它的运行逻辑和商业模式是什么呢?它会创造更多的奇迹吗?
OpenAI是一家AI研究公司,由埃隆·马斯克(Elon Musk)等人于2015年创办,其总部位于美国旧金山,并得到了亚马逊创始人杰夫·贝佐斯(Jeff Bezos)等知名投资者的支持。其目标是推动AI的发展,并让AI技术造福全人类。为此,OpenAI在AI领域进行了大量的研究工作,包括自然语言处理、计算机视觉、机器学习、深度学习等方向。
由于OpenAI的核心成员均是AI领域的顶尖科学家和研究者,其研究成果备受瞩目。OpenAI的技术成果包括了一些AI项目,如GPT、Gym[插图]以及OpenAI Five等。
其中,OpenAI最为著名的成果之一就是GPT系列模型,这是一种基于深度学习的语言模型,能够生成高质量的自然语言文本,被广泛应用于语言模型、文本生成、对话系统等领域。而名为OpenAI Gym的强化学习平台,则为研究和应用强化学习提供了一个开放的环境。
为了推动AI技术的发展,OpenAI还积极开展AI的伦理和社会影响研究。例如,OpenAI曾发表过《AI安全需要社会科学家》(AI Safety Needs Social Scientists)[插图]等多篇关于AI安全与社会问题的研究报告,以及《人工智能的恶意使用:预测、预防和缓解》(The Malicious Use of Artificial Intelligence: Forecasting, Prevention, and Mitigation)[插图]等多项伦理规范。
OpenAI的开放性和透明度是值得称赞的。OpenAI开放了大量的研究成果,推动了AI技术的普及和应用。此外,OpenAI还开发了一个名为CodeX[插图]的系统,它可以自动编写代码,帮助程序员提高工作效率。
OpenAI一直致力于推动AI技术的开放和合作。2016年,OpenAI与微软达成合作,微软向OpenAI提供了10亿美元的投资,帮助OpenAI开展更加复杂的AI研究。OpenAI还与众多知名高校和研究机构合作,包括斯坦福大学、麻省理工学院等。
此外,OpenAI提出了“可控AI”的概念,即AI技术应该是一种安全的、可控的、透明的、可解释的,以及能够为人类带来更多好处的前沿技术。OpenAI的立足点是构建可解释的智能系统,其重点领域包括深度学习、强化学习、计算机视觉、自然语言处理等。
自2015年成立以来,OpenAI在AI领域进行了广泛而深入的研究,取得了许多重要的成果。
•2015年,OpenAI成立,其创始人包括埃隆·马斯克、萨姆·阿尔特曼(Sam Altman)等知名人士,目标是推动AI的发展并让其造福全人类。
•2016年,OpenAI发布了Gym,这是一种用于强化学习的开源工具集,旨在帮助研究者设计和测试新的学习算法。
•2017年,OpenAI推出了一系列AI语言模型,其中最著名的是GPT-1。这些模型利用深度学习技术,可以生成高质量的自然语言文本,包括文章、对话、新闻等,是自然语言处理领域的重要突破。
•2018年,OpenAI宣布组建了一个新的研究团队,致力于开发AI系统以进行更加深入的推理,增强推断能力。OpenAI还发布了GPT-2,该模型比GPT-1更大、更复杂,能够生成更逼真的自然语言文本。
•2019年,OpenAI释放了一部分GPT-2的源代码,这使得研究人员和开发者能够更加深入地了解这个模型的工作原理和性能,促进了AI技术的开放和共享。
•2020年,OpenAI宣布推出了GPT-3,这是迄今为止最大的语言模型,包含了1750亿个参数,能够生成非常逼真的自然语言文本。此外,OpenAI还发布了一些新的工具和应用程序,包括CodeX、DALL-E(图像生成系统)等,这些工具利用了GPT-3的强大功能,拓展了AI应用的范围和领域。
•2021年,OpenAI宣布将以混合模式(hybrid model)运营,该模式结合了非营利性质和营利性质,可以更好地推动AI技术的应用和发展。同时,OpenAI还开放了GPT-3 API,任何人都可以使用这个强大的语言模型来开发新的应用和工具。
•2022年,OpenAI推出ChatGPT,ChatGPT一经问世便轰动全球,引发了广泛的行业和社会关注。
OpenAI的发展历程见证了AI技术的飞速发展,其研究成果也受到了国际社会的广泛关注。
业务模式
OpenAI持续努力,不断取得骄人成绩。本小节我们将介绍关于ChatGPT使用的GPT系列语言模型之外的其他产品,关于GPT模型的详细介绍可以看其他文章。
OpenAI的产品和服务都基于AI技术的创新应用,它开发了DALL-E及DALL-E2模型、Gym,开放了GPT-3 API,开发者可自由接入。它还提供多种AI技术服务,包括技术咨询、算法训练和部署、语音合成等。
DALL-E模型
DALL-E是由OpenAI研究团队开发的一款AI模型,旨在将文字描述转换为图像。它是OpenAI继GPT-2、GPT-3等知名模型之后的又一力作。
DALL-E(Dali+Pixar+WALL-E的缩写)的名称是从三个文化符号中获得的灵感,它们代表了绘画大师达利(Dali)、皮克斯动画工作室(Pixar)和电影《机器人总动员》中的机器人角色瓦力(WALL-E)。
释义1.2 DALL-E
DALL-E的工作原理是将一组描述性文字输入模型,然后通过训练模型生成与输入的文字描述相匹配的图像。
与GPT-3类似,DALL-E也是一种基于Transformer[插图]的神经网络模型,它可以将自然语言描述转换为高质量的图像。DALL-E使用了大规模的自动编码器来学习从文本到图像的映射。与其他图像生成模型不同的是,DALL-E可以生成非常奇特的图像,如“百合花状的大象”或“烤面包状的太阳镜”,这些图像与真实世界中的对象并不一致,但仍然非常逼真。
DALL-E模型的训练数据集由互联网上的图像和对应的文本描述组成,它使用了一个包含多层卷积神经网络和Transformer解码器的结构来生成图像。该模型使用了大量的参数和计算资源,能够处理非常复杂的图像生成任务,但也需要消耗大量的时间和计算资源进行训练。该模型在许多领域中都有潜在应用,如图像编辑、电影特效、虚拟现实等。然而,由于该模型还处于实验阶段,因此它的实际应用还需要进一步研究和开发。
尽管DALL-E的创新性和实用性都很高,但是它也存在一些问题。例如,它可能会生成一些不合理的图像,这是因为它的训练数据集中可能存在一些偏差。此外,DALL-E的训练过程非常复杂,它使用了大量数据集和深度学习技术,并且需要消耗大量的时间和计算资源,这也限制了它的应用范围。
Gym
释义1.3 Gym
Gym是由OpenAI推出的一个用于开发和比较强化学习算法的工具包。它提供了一组标准化的环境,可以让研究者和开发者进行强化学习算法的测试和评估。
Gym提供了一些经典的强化学习环境,如CartPole(倒立摆)和Mountain Car(山地车),以及如Atari(雅达利)游戏和Robot Control(机器人控制)等基于真实的强化学习环境。
Gym提供了一个简单易用的Python API,使得开发者可以很容易地编写自己的强化学习算法,并将其应用于提供的环境中。此外,它还提供了一些强化学习算法的实现,如Q学习和DQN等,供开发者使用和比较。
Gym的主要目标是为强化学习算法的研究和开发提供一个标准化的测试平台。通过Gym,开发者和研究者可以使用相同的环境和工具来测试和比较自己的算法,从而使研究结果更加客观。
尽管Gym是一个非常有用的平台,但是它也存在一些局限性。例如,它只适用于强化学习算法的开发和研究,而不适用于其他类型的机器学习算法。此外,由于Gym的环境是固定的,因此它并不能覆盖所有的强化学习场景。
OpenAI API
OpenAI提供了一系列的API和工具,使开发者能够更快地将想法转换为可使用的应用程序和服务以帮助他们节约时间和开发成本。
OpenAI API支持多种应用场景,其中包括自然语言处理、计算机视觉、强化学习、增强学习和深度学习等。开发者可以使用OpenAI API来开发更加智能的应用程序,如语音识别、机器翻译、对话机器人、智能推荐等系统。此外,OpenAI API还提供了许多自定义应用程序,如智能家居、智能工厂、智能汽车等,帮助开发者快速实现自己的想法。
OpenAI开放了很多API,如OpenAI Gym API、OpenAI GPT-3 API、OpenAI Spinning Up API和OpenAI Baselines API。
•OpenAI Gym API是一个强化学习框架,它提供一系列经典的强化学习算法,这些算法可以帮助机器学习程序做出更好的决策。OpenAI Gym API支持多种强化学习算法,如Q学习、SARSA、A3C、DDPG、PPO等。
•OpenAI GPT-3 API是一款机器学习API,它能够帮助开发者实现自然语言处理的自动化,其中包括语义理解、自动摘要、文本生成和其他语言任务。OpenAI GPT-3 API为开发者提供了一系列的API,如GPT-3训练器、GPT-3训练语料库等。
•OpenAI Spinning Up API是一个面向强化学习算法开发者的API,它提供了一系列工具和文档,帮助用户快速搭建、训练和评估强化学习模型。Spinning Up API基于Python语言(一种计算机编程语言),它提供了基于PyTorch的深度学习算法实现,包括多种强化学习算法,如Actor-Critic(一种强化学习算法)、DQN、PPO等。同时,它还提供了多种强化学习环境,如Atari游戏、Robotics(OpenAI提供的一个开源项目)、MuJoCo物理模拟器等,用户可以通过这些环境测试自己的强化学习模型。此外,Spinning Up API还提供高效的数据处理和并行化工具,可以加速模型训练和提高评估速度。最后,它还提供了详细的文档和教程,帮助用户快速学习强化学习算法。
•OpenAI Baselines API是OpenAI发布的一个强化学习算法库,它提供了多种标准、高效的强化学习算法。OpenAI Baselines基于Python语言和Tensor Flow(符号数学系统)深度学习框架,旨在为强化学习的研究者和开发者提供一个简单易用的工具集,帮助他们快速开发和测试强化学习算法。它所提供的强化学习算法都经过了严格的测试,并进行了优化,可以在Gym等标准化的环境中进行评估和比较。此外,OpenAI Baselines还提供了许多辅助工具,如数据搜集、可视化、参数优化等工具,这些工具可以帮助开发者更好地理解和优化自己的强化学习算法。同时,OpenAI Baselines还支持分布式训练,可以在多个CPU(中央处理器)或GPU(图形处理器)上并行训练强化学习模型,从而大大提高模型训练的速度。
层层的突破
2022年11月底,OpenAI发布了ChatGPT,它是一个基于GPT-3.5体系架构的大型语言模型,相较于其他语言类AI应用拥有更加强大的文本处理能力。
ChatGPT具有大量的预训练参数,能够涵盖广泛的知识领域,并可以通过自我学习和不断优化拓展自身的知识深度和广度。因此,它在多个领域都能发挥作用。并且它可以通过定制和模型微调参数,满足不同用户、不同场景的需求,比传统的语言模型具有更高的灵活性和可定制性。
ChatGPT的语言表达能力更接近人类,它可以生成更加流畅自然的文本,包括文章、对话、摘要、翻译等多种形式。此外,ChatGPT有极强的文本交互能力,可以与用户进行多轮对话,能够准确理解和回答用户的问题。它还可以依据用户提供的信息,结合上下文来回答问题。同时,它能够通过语言实现逻辑推理,但其在数理推理方面的能力较弱。相较于其他的语言模型,ChatGPT已经能够实现更加智能化的人机交互。
作为一个语言类AI,ChatGPT的文本处理能力非常强大,它可以根据用户需求进行非交互式写作,在诸如翻译等辅助性写作方面的表现也十分优秀。本节将用多个实际例子来说明ChatGPT在不同场景中的表现。
文本创作主要包含结构化写作和非结构化写作。其中,结构化写作是指按照一定的格式、规则或标准,进行有较强逻辑性的写作。结构化写作要求文章条理清晰,易于阅读和理解。常见的结构化写作包括标准化的政策性文件及规范性文件,如:公文、法律文件及公司的行政法规等;需要向读者传递信息的新闻稿件及咨询报告等;需要对现有知识及成果进行综合归纳和系统阐述的教科书、科普类写作等;以及需要对比较复杂的工作做出规划及部署的计划性公文、策划案等。此外,在工作场景中的邮件及工作总结等也属于结构化写作。
非结构化写作则是一种没有明确大纲或组织框架的写作方式。它以文字为载体来表达作者的个人意识,以一种更艺术的形式来传递思想、营造氛围,以写意的方法激发读者的想象力。它强调的是创造性和自由表达,作者可以自由地发挥想象力。极具艺术创造性的散文、诗歌、小说及富有创意的广告文案等都属于非结构化写作。
逻辑性强的结构化写作
结构化写作需要确定写作的目的以及预期的读者群体,以决定文本内容的组织方式、语言风格和所需资料的详细程度。结构化写作强调使用简单、清晰的语言表达观点和想法,以确保文本易于阅读和理解,并且要确保文本的逻辑性和连贯性。ChatGPT在结构化写作上的表现非常亮眼,它能在很短的时间内生成逻辑连贯的结构化段落或文章。
撰写新闻稿件
图1.2是使用ChatGPT生成的新闻稿件。在对ChatGPT发出“请写一篇关于ChatGPT的新闻播报”的命令后,它快速生成了一篇标准的新闻稿。整篇稿件的逻辑性较强,包含了引言、背景,表达了较为中立的观点并做了总结。
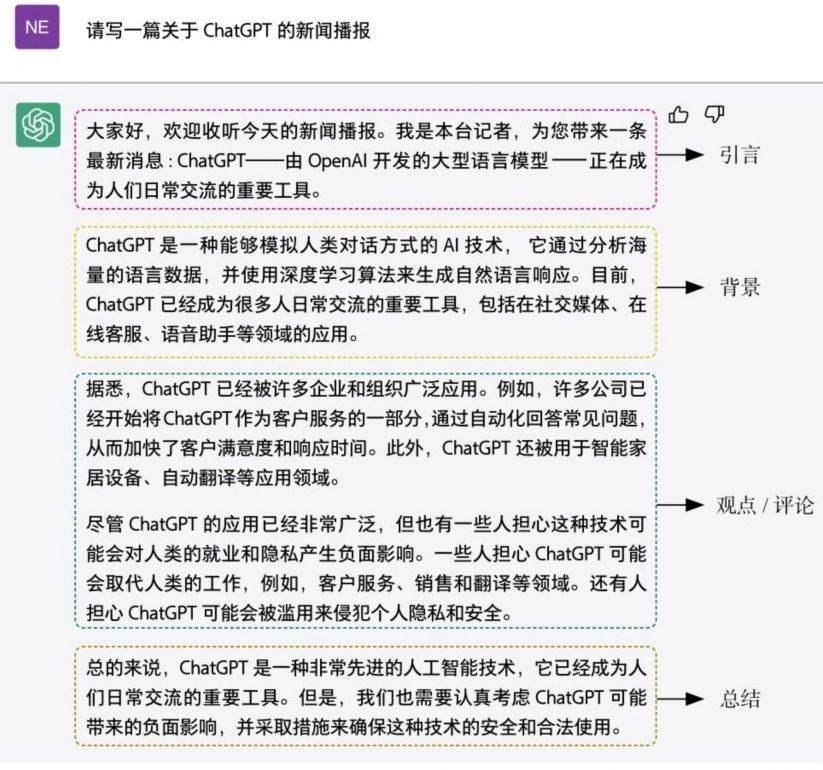
图1.2 ChatGPT示例:撰写新闻稿件
撰写产品推广方案
图1.3展示了使用ChatGPT撰写产品推广方案的示例。ChatGPT可以迅速从市场需求入手,抓住目标客户,强调产品卖点,引导客户消费,最终生成粉底液的推广文案。该文案结构清晰,但语言不太符合当下社交媒体的文案风格。

图1.3 ChatGPT示例:撰写产品推广方案
撰写工作邮件
虽然ChatGPT是一个自动化工具,但它并不能完全替代人类的写作。在撰写有特定目的和目标受众的文本时,ChatGPT需要用户提供更具体的需求命令,才能生成更精确的文本内容。
图1.4展示了ChatGPT在工作场景中撰写英文工作邮件的示例。工作邮件需要遵循较为规范的书写格式,且要注意语气和措辞。只要准确告知邮件需要包含的内容,ChatGPT就可以快速生成标准格式的商务邮件。

图1.4 ChatGPT示例:撰写工作邮件
艺术性强的非结构化写作
非结构化写作可能会导致文本的逻辑性较差,特别是意识流写作,会使读者难以直观地理解文本意思,因为它不具备明确的逻辑顺序和清晰的结构。它是一种较为自由和开放的写作方式,强调创造性、艺术性及表达自由性。ChatGPT同样可以进行逻辑性较弱但富有创造性的非结构化写作,如小说、诗歌、散文等。
小说梗概
图1.5是ChatGPT写的一个武侠小说的梗概,故事围绕着一个叫李飞雪的少侠展开。虽然ChatGPT生成的小说梗概拥有完整的故事线,但情节略为老套,可以看出是依据较热门的武侠小说模式来撰写的。但是,ChatGPT能够理解“武侠小说”的含义,并仿照中国武侠小说的故事发展模式创造出小说梗概。对语言类AI来说,这在非结构化写作上已经有了质的飞跃。

图1.5 ChatGPT示例:撰写小说梗概
创作诗歌
相较于更注重故事情节和角色刻画的小说,诗歌的语言更为抽象化,它是一种更注重意象表达的文学形式。诗歌强调表现诗人的内心情感和思想,而对没有人类情感的AI来说,诗歌创作更多的是模仿诗歌的写作结构和语言风格,在意象和情感的表达上缺乏艺术性。图1.6是ChatGPT创作的一首赞美春天的现代诗。在生成诗歌文本时,ChatGPT遵循了现代诗的写作结构,但在意象的表达上较为简单直白。
相较于现代诗,中国的古诗词更讲究“只可意会,不可言传”的意境美,具有高度凝练的语言艺术魅力。图1.7是ChatGPT创作的一首七言绝句。它能够理解“七言绝句”的含义,并依照每首八句,每句七字的标准格式生成文本。
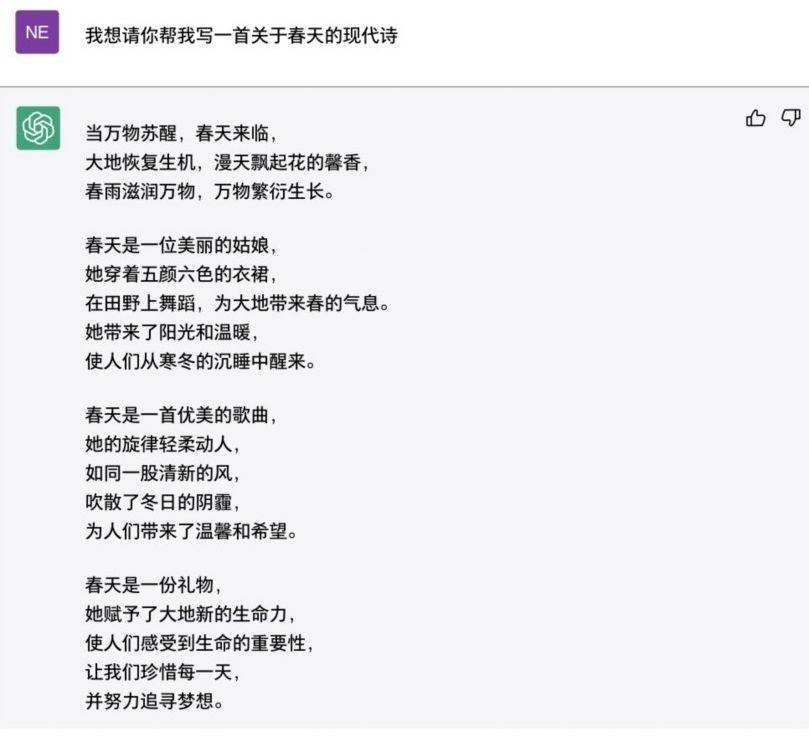
图1.6 ChatGPT示例:撰写现代诗

图1.7 ChatGPT示例:创作七言绝句
高效率的辅助性写作
除了对逻辑性要求较高的结构化写作及需要富有创造性的非结构化写作,ChatGPT在辅助性写作上的能力更为突出,如它在多语言翻译、修正语法错误、改进文章措辞及归纳总结文章含义等方面表现优秀,可以辅助用户高效地完成文本创作。
翻译
在ChatGPT出现以前,语言类AI在中英文翻译上的应用已日渐成熟。谷歌翻译(来自美国)和DeepL翻译(来自德国)都是AI翻译领域中比较有代表性的应用。图1.8节选了维基百科中关于AI的英文介绍,对比了谷歌翻译及ChatGPT翻译的结果。
图1.8中节选维基百科中关于AI介绍的原文如下:
AI applications include advanced web search engines(e.g., Google Search), recommendation systems(used by YouTube, Amazon, and Netflix ), understanding human speech(such as Siri and Alexa ), self-driving cars(e.g., Waymo ), generative or creative tools(ChatGPT and AI art ), automated decision-making, and competing at the highest level in strategic game systems(such as chess and Go ).
Artificial intelligence was founded as an academic discipline in 1956, and in the years since it has experienced several waves of optimism, followed by disappointment and the loss of funding(known as an "AI winter" ), followed by new approaches, success, and renewed funding. AI research has tried and discarded many different approaches,including simulating the brain, modeling human problem solving, formal logic, large databases of knowledge, and imitating animal behavior. In the first decades of the 21st century, highly mathematical and statistical machine learning has dominated the field, and this technique has proved highly successful, helping to solve many challenging problems throughout industry and academia.

图1.8 谷歌翻译与ChatGPT翻译对比
谷歌翻译与ChatGPT在翻译简单句子时没有太大的差异,但在长句、难句的翻译上,ChatGPT翻译得更通顺,语言表达更自然。如图1.8所示,对于多个并列句的翻译,谷歌翻译的措辞略微重复且对英文被动语态的翻译不够准确。
“……随后是失望和资金流失(被称为‘AI冬天’),随后是新方法、成功和重新资助……”相比于谷歌翻译,ChatGPT翻译的语言就流畅许多,“……多年来经历了几次乐观、失望和资金损失(被称为‘AI冬天’),然后是新的方法、成功和重新获得资金……”在同一个句子中,避免了重复措辞,并且对英文被动语态的翻译较为准确。
润色
润色指的是对文本、文章或其他写作内容进行修改、编辑的改进过程。它包括查错,修改语法错误、句子结构,增加或删减内容,以及改变整体写作风格和提高流畅度等方面的工作。润色可以提高文本的质量,使文本更具可读性,让读者能够更容易理解文本所传达的信息。
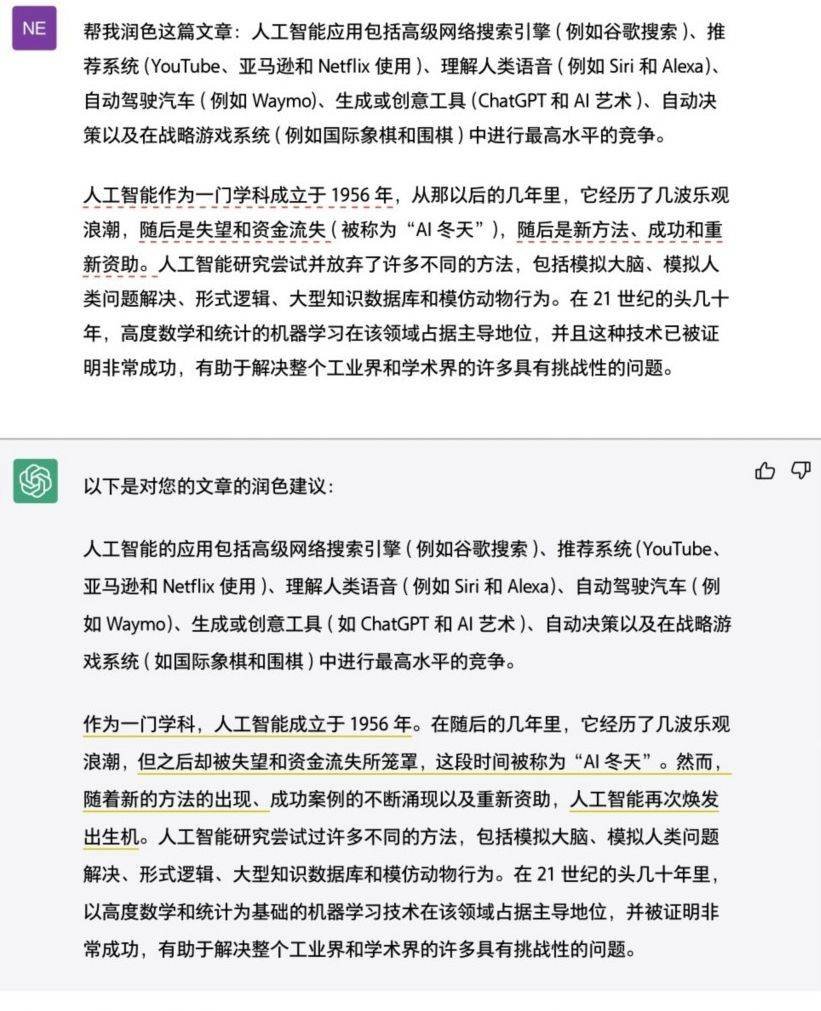
图1.9为使用ChatGPT修改谷歌翻译结果的示例展示。Chat-GPT纠正了并列句重复措辞的问题,润色后行文更加流畅。

图1.9 ChatGPT示例:润色修改文章
图1.10中展示的是使用ChatGPT修改中文病句的示例。示例中的中文语句涵盖了常见的语病,如句子成分残缺、词语搭配不当、重复措辞、滥用副词及语义前后矛盾等。可以看出,ChatGPT可以修改大部分的中文语病。但在图1.10中,第一句话成分残缺的问题没有修正,在ChatGPT修改后的句子中,依然缺少主语。

图1.10 ChatGPT示例:修改中文病句
图1.11展示的是使用ChatGPT修改英文病句的示例。相较于对中文的润色,ChatGPT在英文文本修改上表现出更加出色的能力。示例中的6句英文涵盖了过度使用副词、过多的介词短语、语义不明、错误用词、指代不明及逗号使用错误的问题。可以看出,ChatGPT可以修改上述语病,且行文流畅自然。
总的来说,ChatGPT可以高效地帮助用户修改文章,且其处理英文文本的性能更强。

图1.11 ChatGPT示例:修改英文病句
段落总结
除了能够对文章进行修改,ChatGPT还可以辅助用户对文章的大意进行总结。在图1.12的例子中,输入一段1300多字介绍故宫历史的文本,然后,命令ChatGPT用300字总结文章的大意。可以看出,ChatGPT能够使用逻辑清晰且流畅自然的语言总结出文章的内容。
在图1.12的例子中,输入介绍故宫历史的文本。
故宫,又称紫禁城,是明清两朝二十四位皇帝的皇宫。故宫始建于明成祖永乐四年(1406年),永乐十八年(1420年)落成。位于北京中轴线中心的故宫,占地面积106.09万平方米,建筑面积约23.33万平方米,是世界上现存规模最大的宫殿建筑群。故宫是第一批全国重点文物保护单位、第一批国家5A级旅游景区,1987年被选入《世界文化遗产》名录。故宫现为故宫博物院,藏品主要以明、清两代皇宫和宫廷收藏为基础,是国家一级博物馆。
明初定都于应天府(今南京)。建文元年(1399年),燕王朱棣自北平(今北京)起兵,发动靖难之役。永乐元年(1403年),朱棣颁诏改北平为北京。从永乐元年至三年,明成祖朱棣多次下令从各地迁入人口至北京。永乐四年(1406年)闰七月,朱棣颁诏“以明年建北京宫殿”,永乐五年开始营建紫禁城。宫殿和宫墙由潭柘寺的无名和尚设计,泰宁侯陈珪、工部侍郎吴中、刑部侍郎张思恭主持工程营建。以北方工匠为主体的大量营建工匠,包括部分南方工匠,如著名的石工陆祥、瓦工杨青等,在永乐五年五月到达北京。建造紫禁城和改造北京是同时进行的,以原来的元大都城为基础改建。紫禁城工程开始后不久,受到长陵建设及永乐八年、十一年两次北伐蒙古战役影响,营建速度放慢,至永乐十六年六月方才开始重新开工。
永乐十八年(1420年)十一月,朱棣发布诏书,宣告北京宫殿竣工。次年正月初一日,朱棣在奉天殿(今太和殿)接受朝贺,由此开启了紫禁城自明至清的使用历史。同年五月遭雷击,发生大火,前三殿被焚毁。正统五年(1440年),重建前三殿及乾清宫。天顺三年(1459年),营建西苑。嘉靖三十六年(1557年),紫禁城大火,前三殿、奉天门、文武楼、午门全部被焚毁,至嘉靖四十年(1561年)才重建完工。万历二十五年(1597年),紫禁城大火,焚毁前三殿、后三宫。复建工程直至天启七年(1627年)方完工。
崇祯十七年(1644年),李自成军攻陷北京,明朝灭亡。未几,明朝山海关总兵吴三桂引清兵入关,击败李自成。李自成向陕西撤退前焚毁紫禁城,仅武英殿、建极殿、英华殿、南薰殿、四周角楼和皇极门未焚。同年清顺治帝至北京,以皇极门为常朝场所,以未被焚毁的建极殿为位育宫,作为顺治帝寝宫,摄政王多尔衮在武英殿办公。顺治元年(1644年)至顺治十四年,重建了午门、天安门、外朝前三殿,将位育宫改名为保和殿(顺治二年),又整修内廷、东路和西路的建筑。康熙六年(1667年)重建端门。康熙二十二年(1683年),开始重建紫禁城其余被毁的部分建筑。1735年乾隆帝即位,此后的六十年间对紫禁城进行了大规模增建和改建。嘉庆十八年(1813年),林清率天理教教众攻打紫禁城。光绪十四年(1886年)太和门护军值班房发生火灾,由于救火设施不完善,大火烧了两天,贞度门、太和门、昭德门被焚。此次损坏直到光绪二十年才修复完毕。
1912年清帝溥仪退位,但仍居于宫内。1924年冯玉祥与胡景翼、孙岳在北京发动北京政变,推翻了曹锟反动政权,12月5日,黄郛主持召开摄政内阁会议,修改《清室优待条件》内容,根据第五条规定,废除皇帝尊号,请废帝溥仪出宫。政府代表李煜瀛、京师警卫司令鹿锺麟、警察总监张璧,于6日接管皇宫,封存文物。后经摄政内阁核准,经一年之整理,故宫博物院于1925年10月10日正式成立。
2012年,故宫单日最高客流量突破18万人次,2019年全年客流量突破1900万人次,可以说是世界上接待游客最繁忙的博物馆。2013年5月18日起,故宫博物院范围内严禁明火,全体员工、在院合作单位和游客,不管在室内和室外,不分开放区与工作区,一律禁止吸烟、禁用明火。

图1.12 ChatGPT示例:段落总结
注:图中ChatGPT将故宫博物院的成立和现状总结成“民国时期修葺历史”并不准确。
生成表格
除了生成和处理文本,ChatGPT还具备输出表格的能力。图1.13展示的是用户命令ChatGPT生成“2011—2020年中国的GDP数据表”的示例。ChatGPT不仅具备生成表格样式答案的能力,也具备自动检索数据的能力。回答中的GDP数据并不是用户告知ChatGPT的,而是它在得到用户指令后,自己搜寻,并以表格的形式展示出来的。
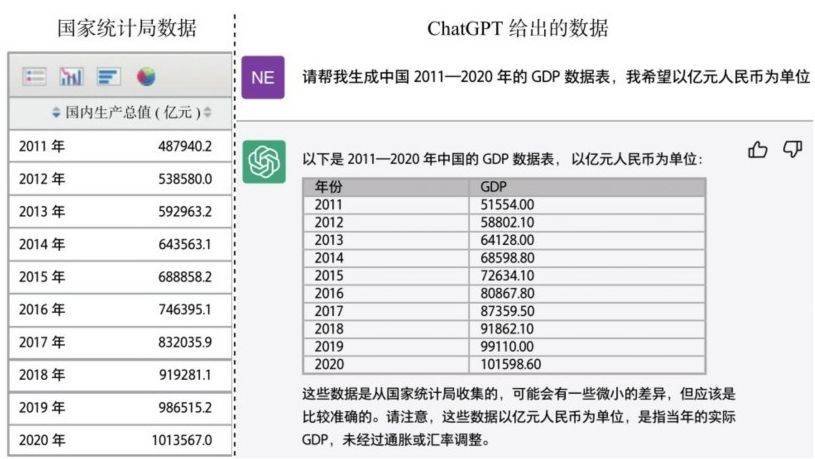
图1.13 ChatGPT示例:生成表格
从图1.13可以看出,ChatGPT给出的结果与中国国家统计局发布的官方数据是有出入的。由此可见,ChatGPT的回答并不总是准确的。因此,当进行诸如写论文、做数据分析等对准确性要求较高的工作时,用户需要进一步考证ChatGPT结果的准确性。
技术性强的代码生成
ChatGPT不仅可以很好地完成各种基础的语言类任务,也可能取代部分程序员的工作。换句话说,ChatGPT可以根据用户输入的文字请求,编写相应的代码。ChatGPT的代码生成能力可能会引发互联网行业的变革。在未来,或许初级程序员的岗位将会被AI取代。
如图1.14所示,用户要求ChatGPT用Python语言编写一个弹球游戏的代码。从ChatGPT生成的代码质量来看,它不像一个资深的“码农”,因为代码质量有很大的提高空间,但它足以承担各种重复性的代码编写任务。
图1.14 ChatGPT示例:弹球游戏代码
ChatGPT生成代码的能力离不开互联网中海量代码数据的支撑。如果ChatGPT真的取代了程序员去完成各种代码编写任务,也会带来一个问题:在未来,ChatGPT学习所用的代码数据是由ChatGPT自己生成的,这合理吗?如果没有合适的评定数据的方法,那么在取代程序员后,ChatGPT将面临没有任何数据可用于学习的困境。不仅是代码,文本数据也是如此。因此,在ChatGPT取代人类工作之前,如何持久地获取有效数据是首先要思考的问题。
总而言之,ChatGPT不论是在文本任务还是代码任务上都表现出极强的能力,大有取代人类的趋势。如果没有正确引导的话,ChatGPT的出现可能导致各行业更加剧烈的“内卷”。或许ChatGPT的出现是出于让人们进一步提高生产力的目的,但它也需要正确的引导,从而真正成为帮助人们提高效率的工具,而不是成为“内卷”的背后推手。