RESTful
REST 指的是一组架构约束条件和原则。满足这些约束条件和原则的应用程序或设计就
是 RESTful。Web 应用程序最重要的 REST 原则是,客户端和服务器之间的交互在请求之间是无状态的。从客户端到服务器的每个请求都必须包含理解请求所必需的信息。如果服务器在请求之间的任何时间点重启,客户端不会得到通知。此外,无状态请求可以由任何可用服务器回答,这十分适合云计算之类的环境。客户端可以缓存数据以改进性能。
在服务器端,应用程序状态和功能可以分为各种资源。资源是一个有趣的概念实体,它向客户端公开。资源的例子有:应用程序对象、数据库记录、算法等等。每个资源都使用 URI (Universal Resource Identifier) 得到一个唯一的地址。所有资源都共享统一的接口,以便在客户端和服务器之间传输状态。使用的是标准的 HTTP 方法,比如 GET、PUT、POST 和DELETE。
在 REST 样式的 Web 服务中,每个资源都有一个地址。资源本身都是方法调用的目
标,方法列表对所有资源都是一样的。这些方法都是标准方法,包括 HTTP GET、POST、PUT、DELETE,还可能包括 HEAD 和 OPTIONS。简单的理解就是,如果想要访问互联网上的资源,就必须向资源所在的服务器发出请求,请求体中必须包含资源的网络路径,以及对资源进行的操作(增删改查)。
数据格式
Elasticsearch 是面向文档型数据库,一条数据在这里就是一个文档。为了方便大家理解,我们将 Elasticsearch 里存储文档数据和关系型数据库 MySQL 存储数据的概念进行一个类比

ES 里的 Index 可以看做一个库,而 Types 相当于表,Documents 则相当于表的行。这里 Types 的概念已经被逐渐弱化,Elasticsearch 6.X 中,一个 index 下已经只能包含一个type,Elasticsearch 7.X 中, Type 的概念已经被删除了。
用 JSON 作为文档序列化的格式,比如一条用户信息:
{
"name" : "John",
"sex" : "Male",
"age" : 25,
"birthDate": "1990/05/01",
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}索引操作
1、创建索引
ES 软件的索引可以类比为 MySQL 中表的概念,创建一个索引,类似于创建一个表。查询完成后,Kibana 右侧会返回响应结果及请求状态
# 创建索引
PUT myindex
重复创建索引时,Kibana 右侧会返回响应结果,其中包含错误信息。
# 重复创建索引
PUT myindex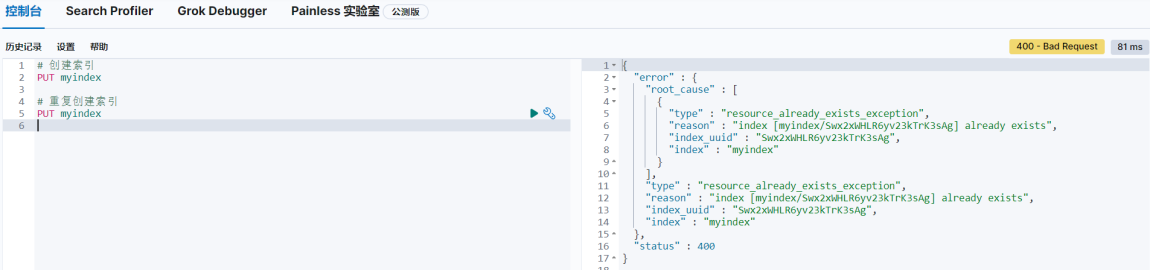
2、查询指定索引
根据索引名称查询指定索引,如果查询到,会返回索引的详细信息
# 查询指定索引
GET myindex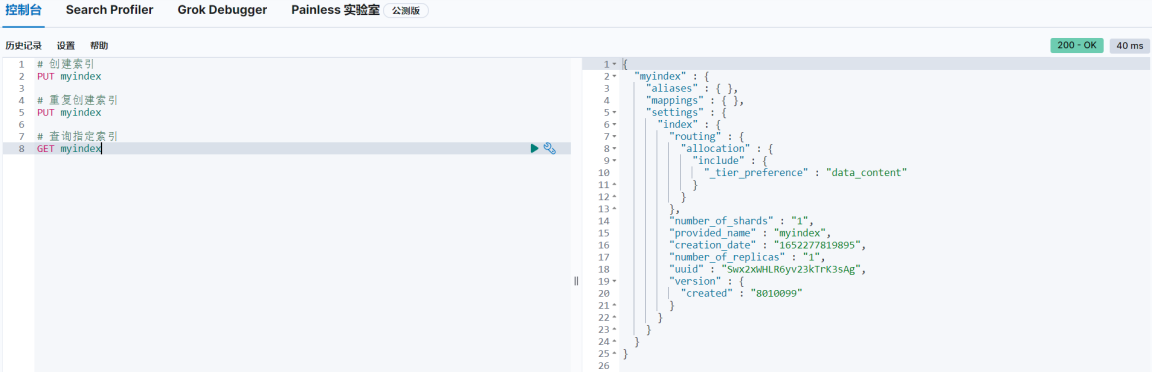
如果查询的索引未存在,会返回错误信息
# 查询未存在的索引
GET myindex1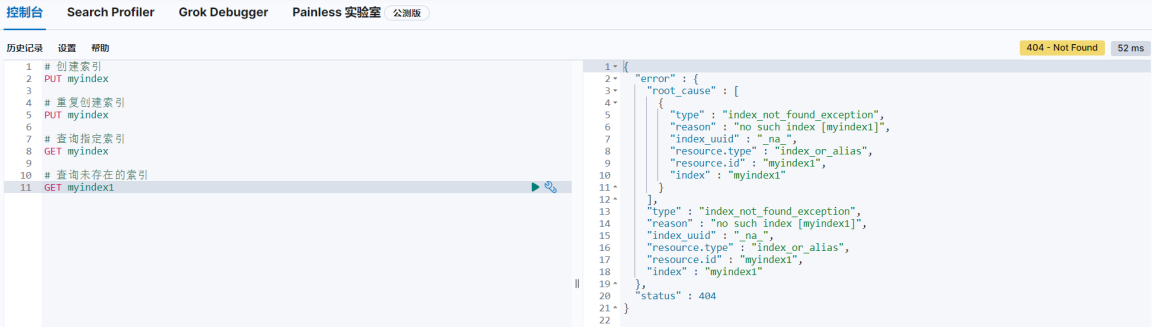
3、查询所有索引
为了方便,可以查询当前所有索引数据。这里请求路径中的 _cat 表示查看的意思,indices表示索引,所以整体含义就是查看当前 ES 服务器中的所有索引,就好像 MySQL 中的 show tables 的感觉。
# 查询当前所有索引
GET _cat/indices
这里的查询结果表示索引的状态信息,按顺序数据表示结果如下:
| 内容 | 含义 | 具体描述 |
|---|---|---|
| green | health | 当前服务器健康状态:green(集群完整)yellow(单点正常、集群不完整)red(单点不正常) |
| open | status | 索引打开、关闭状态 |
| myindex | index | 索引名 |
| Swx2xWHLR6yv23kTrK3sAg | uuid | 索引统一编号 |
| 1 | pri | 主分片数量 |
| 1 | rep | 副本数量 |
| 0 | docs.count | 可用文档数量 |
| 0 | docs.deleted | 文档删除状态(逻辑删除) |
| 450b | store.size | 主分片和副分片整体占空间大小 |
| 225b | pri.store.size | 主分片占空间大小 |
4、 删除索引
删除指定已存在的索引
# 删除指定索引
DELETE myindex
如果删除一个不存在的索引,那么会返回错误信息
# 删除不存在的索引
DELETE myindex1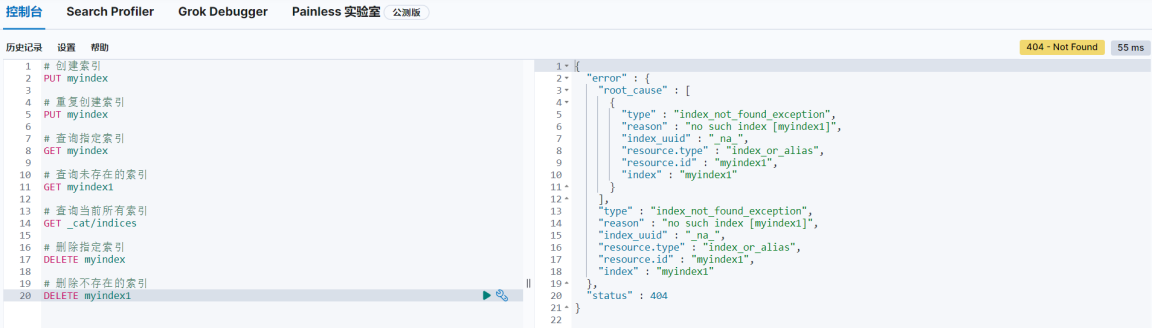
文档操作
文档是 ES 软件搜索数据的最小单位, 不依赖预先定义的模式,所以可以将文档类比为表的一行JSON类型的数据。我们知道关系型数据库中,要提前定义字段才能使用,在Elasticsearch中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段。
1、创建文档
索引已经创建好了,接下来我们来创建文档,并添加数据。这里的文档可以类比为关系型数据库中的表数据,添加的数据格式为 JSON 格式
POST myindex/_doc
{
"id": 1001,
"name": "zhangsan",
"age": 30,
"city": "beijing"
}使用POST创建文档成功

此处因为没有指定数据唯一性标识,所以无法使用 PUT 请求,只能使用 POST 请求,且对数据会生成随机的唯一性标识。否则会返回错误信息
使用PUT创建文档失败

如果在创建数据时,指定唯一性标识,那么请求范式 POST,PUT 都可以
# 创建指定唯一标识的文档,此处请求可以使用POST和PUT
POST myindex/_doc/1001
{
"id": 1001,
"name": "zhangsan",
"age": 30,
"city": "beijing"
}
2、查询文档
根据唯一性标识可以查询对应的文档
# 查询指定标识的文档
GET myindex/_doc/1001?pretty=true
3、修改文档
修改文档本质上和新增文档是一样的,如果存在就修改,如果不存在就新增
# 修改文档
POST myindex/_doc/1001
{
"id": 1001,
"name": "zhangsan",
"age": 40,
"city": "beijing"
}
4、删除文档
删除一个文档不会立即从磁盘上移除,它只是被标记成已删除(逻辑删除)。
# 删除文档
DELETE myindex/_doc/1001
5、查询所有文档
GET myindex/_search_
数据搜索
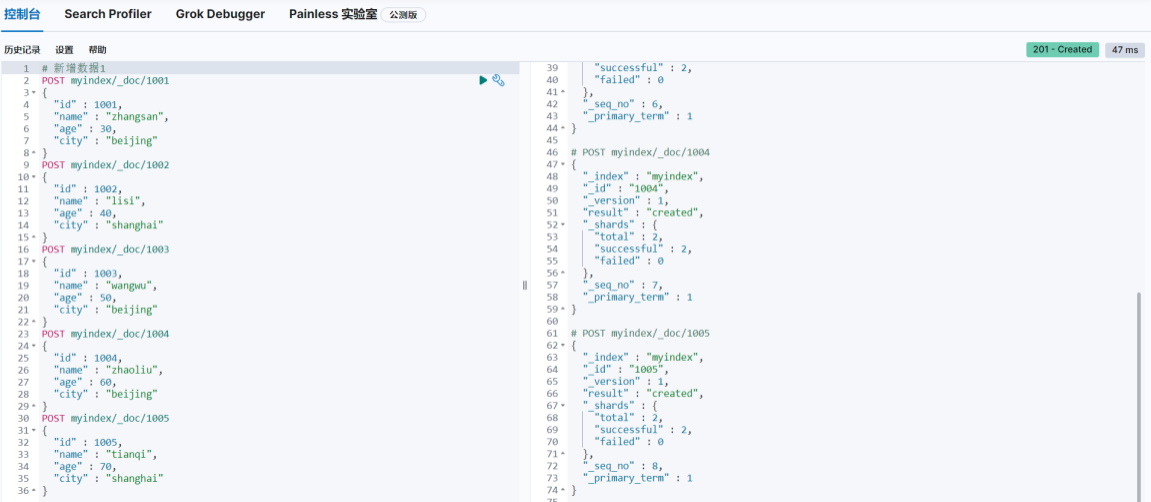
为了方便演示,事先准备多条数据
# 新增数据1
POST myindex/_doc/1001
{
"id": 1001,
"name": "zhangsan",
"age": 30,
"city": "beijing"
}
POST myindex/_doc/1002
{
"id": 1002,
"name": "lisi",
"age": 40,
"city": "shanghai"
}
POST myindex/_doc/1003
{
"id": 1003,
"name": "wangwu",
"age": 50,
"city": "beijing"
}
POST myindex/_doc/1004
{
"id": 1004,
"name": "zhaoliu",
"age": 60,
"city": "beijing"
}
POST myindex/_doc/1005
{
"id": 1005,
"name": "tianqi",
"age": 70,
"city": "beijing"
}
1、查询所有文档
# 查询指定索引的所有文档
GET myindex/_search
2、匹配查询文档
这里的查询表示文档数据中 JSON 对象数据中的 name 属性是 zhangsan。
# 匹配查询文档
GET myindex/_search
{
"query": {
"match": {
"name": "zhangsan"
}
}
}
3、匹配查询字段
默认情况下,Elasticsearch 在搜索的结果中,会把文档中保存在 _source 的所有字段都返回。
如果我们只想获取其中的部分字段,我们可以添加_source 的过滤
# 匹配查询字段,只显示指定数据字段
GET myindex/_search
{
"_source": ["name", "age"],
"query": {
"terms": {
"name": ["zhangsan"]
}
}
}
聚合搜索
聚合允许使用者对 es 文档进行统计分析,类似与关系型数据库中的 group by,当然还有很多其他的聚合,例如取最大值、平均值等等。
1、平均值
# 计算年龄平均值
# 30 + 30 + 40 + 50 + 60 + 70 - 280 /6 - 46.6666....
POST myindex/_search
{
"aggs": {
"avg_age": {
"avg": {
"field": "age"
}
}
}
}
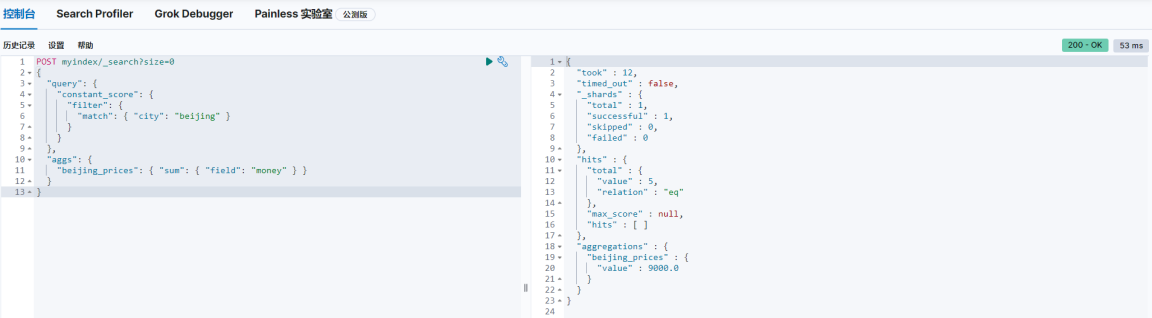
2、求和
POST myindex/_search?size=0
{
"query": {
"constant_score": {
"filter": {
"match": {"city": "beijing"}
}
}
},
"aggs": {
"beijing_prices": {"sum": {"field": "money"}}
}
}
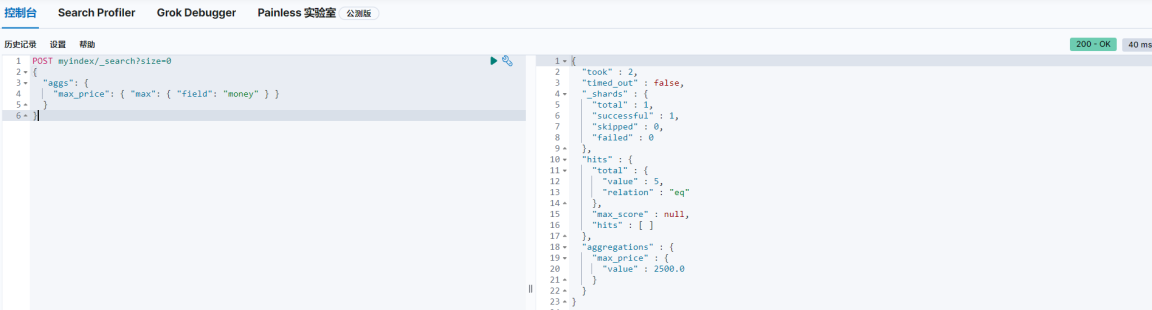
3、最大值
POST myindex/_search?size=0
{
"aggs": {
"max_price": {"max": {"field": "money"}}
}
}
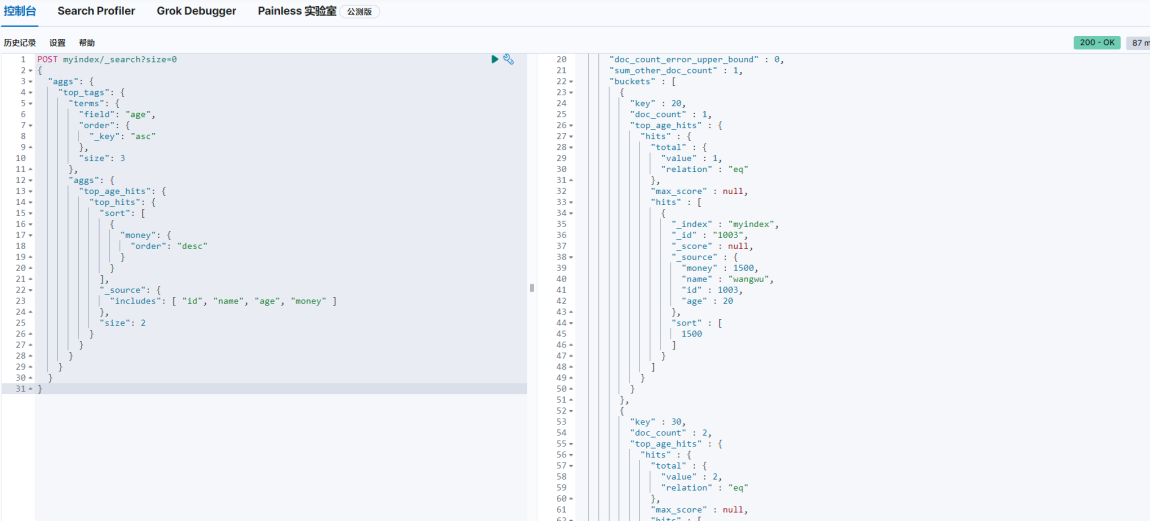
4、TopN
POST myindex/_search?size=0
{
"aggs": {
"top_tags": {
"terms": {
"field": "age",
"order": {
"_key": "asc"
},
"size": 3
},
"aggs": {
"top_age_hits": {
"top_hits": {
"sort": [
{
"money": {
"order": "desc"
}
}
],
"_source": {
"includes": ["id", "name", "age", "money"]
},
"size": 2
}
}
}
}
}
}
索引模板
前面虽然对索引进行一些配置信息设置,但是都是在单个索引上进行设置。在实际开发中,我们可能需要创建不止一个索引,但是每个索引或多或少都有一些共性。
比如我们在设计关系型数据库时,一般都会为每个表结构设计一些常用的字段,比如:创建时间,更新时间,备注信息等。
elasticsearch 在创建索引的时候,就引入了模板的概念,你可以先设置一些通用的模板,在创建索引的时候,elasticsearch 会先根据你创建的模板对索引进行设置。
elasticsearch 中提供了很多的默认设置模板,这就是为什么我们在新建文档的时候,可以为你自动设置一些信息,做一些字段转换等。
索引可使用预定义的模板进行创建,这个模板称作 Index templates。模板设置包括 settings和 mappings
1、创建模板
# 模板名称小写
PUT _template/mytemplate
{
"index_patterns" : [
"my*"
],
"settings" : {
"index" : {
"number_of_shards" : "1"
}
},
"mappings" : {
"properties" : {
"now": {
"type" : "date",
"format" : "yyyy/MM/dd"
}
}
}
}
2、查看模板
GET /_template/mytemplate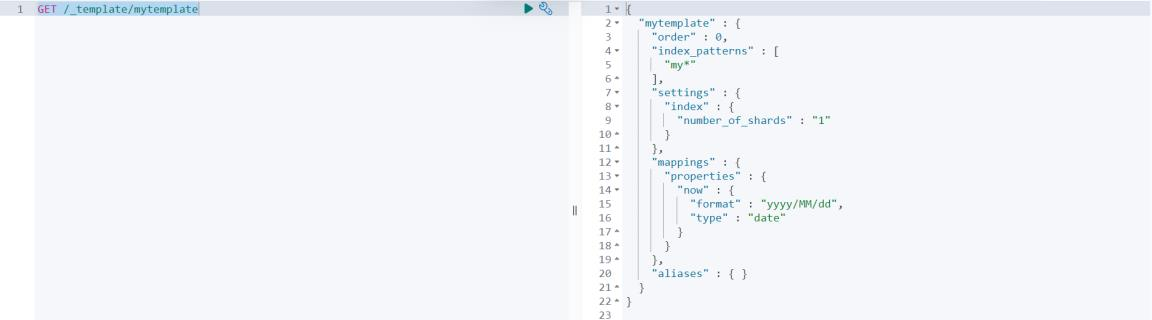
3、验证模板是否存在
HEAD /_template/mytemplate
4、创建索引
PUT testindex
PUT mytest
GET mytest
5、删除模板
DELETE /_template/mytemplate