前言
随着 8.0 的发布,Elastic 很高兴能够将 PyTorch 机器学习模型上传到 Elasticsearch 中,以在 Elastic Stack 中提供现代自然语言处理 (NLP)。现在,Elasticsearch 用户能够集成用于构建 NLP 模型的最流行的格式之一,并将这些模型作为 NLP 数据管道的一部分通过我们的Inference processor 整合到 Elasticsearch 中。
什么是自然语言处理?
NLP 是指我们可以使用软件来操作和理解口语或书面文本或自然语言的方式。 2018 年,Google 开源了一种用于 NLP 预训练的新技术,称为来自 Transformers 的双向编码器呈现,或 BERT。 BERT 通过在没有任何人工参与的情况下对互联网大小的数据集(例如,想想所有的维基百科和数字书籍)进行训练来利用 “transfer learning”。
Transfer learning 允许对 BERT 模型进行预训练以进行通用语言理解。一旦模型只经过一次预训练,它就可以被重用并针对更具体的任务进行微调,以了解语言的使用方式。
为了支持类 BERT 模型(使用与 BERT 相同的标记器的模型),Elasticsearch 将首先通过 PyTorch 模型支持支持大多数最常见的 NLP 任务。 PyTorch 是最受欢迎的现代机器学习库之一,拥有大量活跃用户,它是一个支持深度神经网络的库,例如 BERT 使用的Transformer 架构。
以下是一些示例 NLP 任务:
◼ 情绪分析:用于识别正面与负面陈述的二元分类。
◼ 命名实体识别 (NER):从非结构化文本构建结构,尝试提取名称、位置或组织等细节。
◼ 文本分类:零样本分类允许你根据你选择的类对文本进行分类,而无需进行预训练。
◼ 文本嵌入:用于 k 近邻 (kNN) 搜索。
Elasticsearch 中的自然语言处理
在将 NLP 模型集成到 Elastic 平台时,我们希望为上传和管理模型提供出色的用户体验。使用用于上传 PyTorch 模型的 Eland 客户端和用于管理 Elasticsearch 集群上模型的Kibana 的 ML 模型管理用户界面,用户可以尝试不同的模型并很好地了解它们在数据上的表现。我们还希望使其可跨集群中的多个可用节点进行扩展,并提供良好的推理吞吐量性能。
为了使这一切成为可能,我们需要一个机器学习库来执行推理。在 Elasticsearch 中添加对 PyTorch 的支持需要使用原生库libtorch,它支持 PyTorch,并且仅支持已导出或保存为TorchScript 表示的 PyTorch 模型。这是 libtorch 需要的模型的表示,它将允许Elasticsearch 避免运行 Python 解释器。
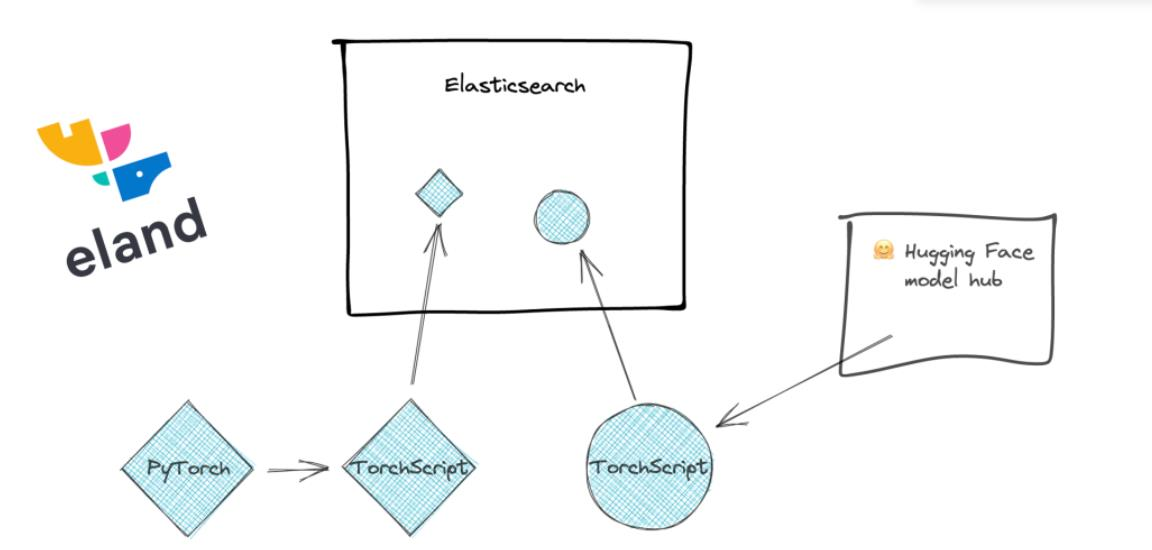
通过与在 PyTorch 模型中构建 NLP 模型的最流行的格式之一集成,Elasticsearch 可以提供一个平台,该平台可处理大量 NLP 任务和用例。许多优秀的库可用于训练 NLP 模型,因此我们暂时将其留给其他工具。无论你是使用 PyTorch NLP、Hugging Face Transformers 还是 Facebook 的 fairseq 等库来训练模型,你都可以将模型导入 Elasticsearch 并对这些模型进行推理。 Elasticsearch 推理最初将仅在摄取时进行,未来还可以扩展以在查询时引入推理。
NLP 在 Elasticsearch 7.x 和 8.x 中的区别
Elasticsearch 一直是进行 NLP 的好地方,但从历史上看,它需要在 Elasticsearch 之外进行一些处理,或者编写一些非常复杂的插件。 借助 8.0,用户现在可以在 Elasticsearch 中更直接地执行命名实体识别、情感分析、文本分类等操作——无需额外的组件或编码。 不仅在 Elasticsearch 中本地计算和创建向量在水平可扩展性方面是“胜利”(通过在服务器集群中分布计算)——这一变化还为Elasticsearch 用户节省了大量时间和精力。
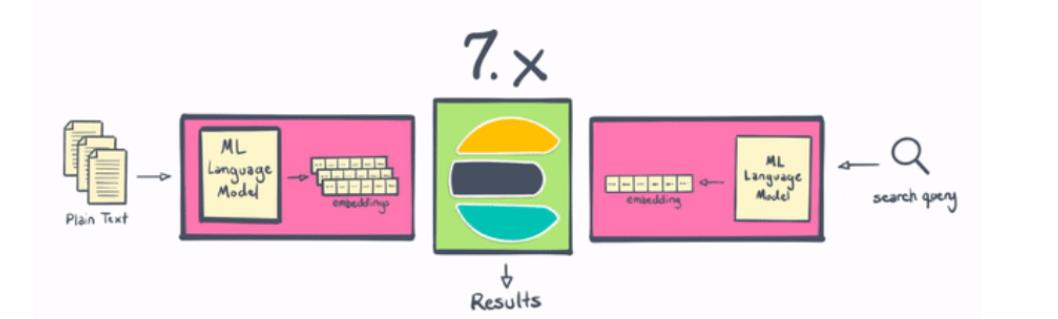
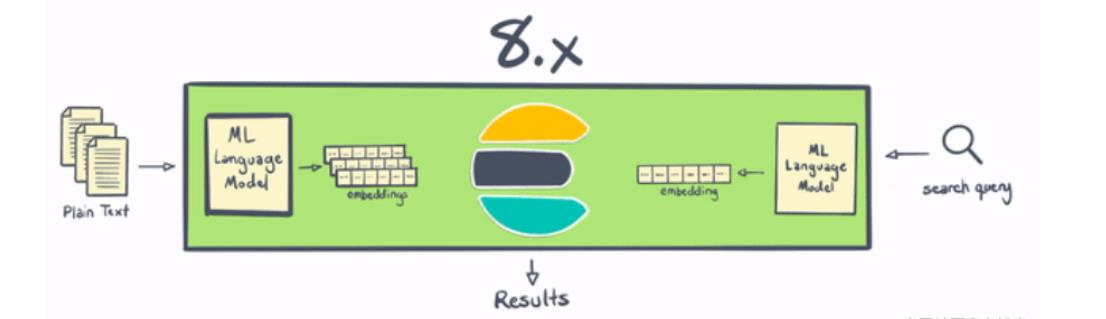
借助 Elastic 8.0,用户可以直接在 Elasticsearch 中使用 PyTorch 机器学习模型(例如 BERT),并在 Elasticsearch 中使用这些模型进行推理。通过使用户能够直接在 Elasticsearch 中执行推理,将现代 NLP 的强大功能集成到搜索应用程序和体验、本质上更高效(得益于 Elasticsearch 的分布式计算能力)和 NLP 本身比以往任何时候都更容易 变得更快,因为你不需要将数据移出到单独的进程或系统中。
NLP 演示
这里我们使用 https://github.com/spinscale/elasticsearch-ingest-opennlp/releases/tag/8.1.1.1 来进行演示。我们必须安装和自己的 Elasticsearch 一致的版本。
目前这个 NLP 支持检测 Date, Person, Location, POS (part of speech) 及其它。
1、安装 opennlp
将下载下来的插件上传到所有 ES 服务器节点的 plugins 路径中。

2、下载 NER 模型
我们需要从 sourceforge 下载最新的 NER 模型
bin/ingest-opennlp/download-models执行时,可能会提示脚本路径不对等问题。直接修改脚本文件改正即可

执行后,会出现如下内容

3、配置 opennlp
修改配置文件:config/elasticsearch.yml
ingest.opennlp.model.file.persons: en-ner-persons.bin
ingest.opennlp.model.file.dates: en-ner-dates.bin
ingest.opennlp.model.file.locations: en-ner-locations.bin重新启动 Elasticsearch
4、运用 opennlp
创建一个支持 NLP 的 pipeline
PUT _ingest/pipeline/opennlp-pipeline
{
"description": "A pipeline to do named entity extraction",
"processors": [
{
"opennlp" : {
"field" : "message"
}
}
]
}增加数据
PUT my-nlp-index
PUT my-nlp-index/_doc/1?pipeline=opennlp-pipeline
{
"message": "Shay Banon announced the release of Elasticsearch 6.0 in November 2017"
}
PUT my-nlp-index/_doc/2?pipeline=opennlp-pipeline
{
"message" : "Kobe Bryant was one of the best basketball players of all times. Not even Michael Jordan has ever scored 81 points in one game. Munich is really an awesome city, but New York is as well. Yesterday has been the hottest day of the year."
}查看数据
GET my-nlp-index/_doc/1
GET my-nlp-index/_doc/2从结果我们可以看出来,它正确地识别了 dates,persons 及 locations。
