一、术语表
在开始使用MaxCompute产品前,您可以提前查阅MaxCompute所涉及的术语及其含义,为了解产品及快速上手提供帮助。本文为您介绍MaxCompute涉及的术语及其概念。
A
-
AccessKey
简称AK,包括AccessKey ID和AccessKey Secret,是访问阿里云API的密钥。在阿里云官网注册云账号后,可以在AccessKey管理页面生成该信息,用于标识用户,为访问MaxCompute、其他阿里云产品或连接第三方工具做签名验证。请妥善保管AccessKey Secret,必须保密,如果存在泄露风险,请及时禁用或更新AccessKey。 -
安全
MaxCompute提供多租户数据安全体系,主要包括用户认证、项目的用户与授权管理、跨项目的资源分享以及项目的数据保护。更多MaxCompute安全操作信息,请参见权限概述。
C
- Console
即MaxCompute客户端,是运行在Window或Linux下的工具,您可以在MaxCompute客户端通过运行命令的方式完成项目管理、DDL、DML等操作。MaxCompute客户端的操作指导,请参见使用客户端(odpscmd)连接。
D
-
Data Type
MaxCompute表中列的数据类型。MaxCompute支持的数据类型版本及各版本的数据类型列表,请参见数据类型版本说明。 -
DDL
Data Definition Language,数据定义语言。例如创建表、创建视图等操作。更多DDL语法信息,请参见DDL语句。 -
DML
Data Manipulation Language,数据操作语言。例如INSERT、UPDATE、DELETE操作。更多DML语法信息,请参见DML操作。
F
-
Function(函数)
MaxCompute提供函数功能,包括内建函数和UDF。更多函数信息,请参见函数。 -
fuxi(伏羲)
伏羲是飞天平台内核中负责资源管理和任务调度的模块,同时也为应用开发提供了一套编程基础框架。 -
MaxCompute的底层任务调度模块为fuxi的调度模块。
I
- Instance(实例)
即实际运行作业的一个具体实例,类同Hadoop中Job的概念。详情请参见任务实例。
M
- MapReduce
MapReduce是处理数据的一种编程模型,通常用于大规模数据集的并行运算。您可以使用MapReduce提供的接口(Java API)编写MapReduce程序,来处理MaxCompute中的数据。编程思想是将数据的处理方式分为Map(映射)和Reduce(规约)。
在正式执行Map前,需要将输入的数据进行分片。所谓分片,就是将输入数据切分为大小相等的数据块,每一块作为单个Map Worker的输入被处理,以便于多个Map Worker同时工作。每个Map Worker在读入各自的数据后,进行计算处理,最终通过Reduce函数整合中间结果,从而得到最终计算结果。详情请参见MapReduce。
N
- Networklink(网络连接)
当您使用外部表、UDF或湖仓一体功能时,MaxCompute默认未建立与外网或VPC网络间的网络连接,您需要开通网络连接以访问外网或VPC中的目标服务(例如HBase、RDS、Hadoop等)。更多开通网络连接信息,请参见网络开通流程。
P
-
Partition(分区)
分区Partition是指一张表下,根据分区字段(一个或多个字段的组合)对数据存储进行划分。如果表没有分区,数据是直接放在表所在的目录下。如果表有分区,每个分区对应表下的一个目录,数据是分别存储在不同的分区目录下。更多分区信息,请参见分区。 -
Project(项目)
项目是MaxCompute的基本组织单元,类似于传统数据库的Database或Schema的概念,是进行多用户隔离和访问控制的主要边界。更多项目信息,请参见项目。
Q
- Quota(配额)
配额是MaxCompute的计算资源池,提供作业运行所需计算资源。更多配额信息,请参见配额。
R
-
Role(角色)
角色是MaxCompute安全功能中的概念,可以理解为拥有相同权限的用户的集合。多个用户可以同时存在于一个角色下,一个用户也可以隶属于多个角色。给角色授权后,该角色下的所有用户拥有相同的权限。更多角色管理信息,请参见角色规划。 -
Resource(资源)
资源是MaxCompute中特有的概念。当您使用MaxCompute的自定义函数(UDF)或MapReduce功能时,需要依赖资源来完成。更多资源信息,请参见资源。
S
-
SDK
Software Development Kit,软件开发工具包。一般都是一些被软件工程师用于为特定的软件包、软件实例、软件框架、硬件平台、操作系统、文档包等建立应用软件的开发工具的集合。MaxCompute支持Java SDK和Python SDK。 -
授权
项目管理员或者项目Owner可以授予其他角色对MaxCompute中的对象(例如表、任务、资源等)进行某种操作的权限,包括读、写、查看等。更多授权信息,请参见用户规划与管理。 -
沙箱(Sandboxie)
沙箱是一种按照安全策略限制程序行为的执行环境。沙箱机制是一种安全机制,将Java代码限定在特定的运行范围中,并且严格限制代码对本地系统资源访问,通过这样的措施来保证对代码的有效隔离,防止对本地系统造成破坏。MaxCompute MapReduce及UDF程序在分布式环境中运行时受到Java沙箱的限制。
T
-
Table(表)
表是MaxCompute的数据存储单元。更多表信息,请参见表。 -
Tunnel
MaxCompute的数据通道,提供高并发的离线数据上传下载服务。您可以使用Tunnel服务向MaxCompute批量上传数据或者向本地进行批量数据下载。相关命令请参见Tunnel命令或批量数据通道SDK。
U
- UDF
User Defined Function,用户自定义函数。
广义的UDF代表了自定义标量函数、自定义聚合函数及自定义表值函数三种类型。MaxCompute支持通过Java、Python编程接口开发自定义函数,详情请参见MaxCompute UDF。
狭义的UDF指用户自定义标量函数(User Defined Scalar Function),它的输入与输出是一对一的关系,即读入一行数据,写出一条输出值。
-
UDAF
User Defined Aggregation Function,自定义聚合函数。它的输入与输出是多对一的关系, 即将多条输入记录聚合成一条输出值。可以与SQL中的GROUP BY语句联用。详情请参见UDAF。 -
UDTF
User Defined Table Valued Function,自定义表值函数。它是唯一能返回多个字段的自定义函数。详情请参见UDTF。 -
User(用户)
用户是MaxCompute安全功能中的概念,MaxCompute支持您通过阿里云账号、RAM用户或RAM角色访问MaxCompute。非MaxCompute项目所有者(Project Owner)的用户必须被加入MaxCompute项目中,且被授予相应的权限,才能操作MaxCompute项目中的数据、作业、资源及函数。更多用户管理信息,请参见用户规划与管理。
V
- View(视图)
视图是在表之上建立的虚拟表,它的结构和内容都来自表。一个视图可以对应一个表或多个表。如果您想保留查询结果,但不想创建表占用存储,可以通过视图实现。更多视图信息,请参见视图操作。
二、核心概念
2.1 核心概念的层次结构
MaxCompute具有层次结构,您可以通过了解其结构,为后期项目规划、安全管理等提供思路。本文为您介绍MaxCompute中核心概念的层次结构及简要含义。
MaxCompute核心概念的层次结构如下。
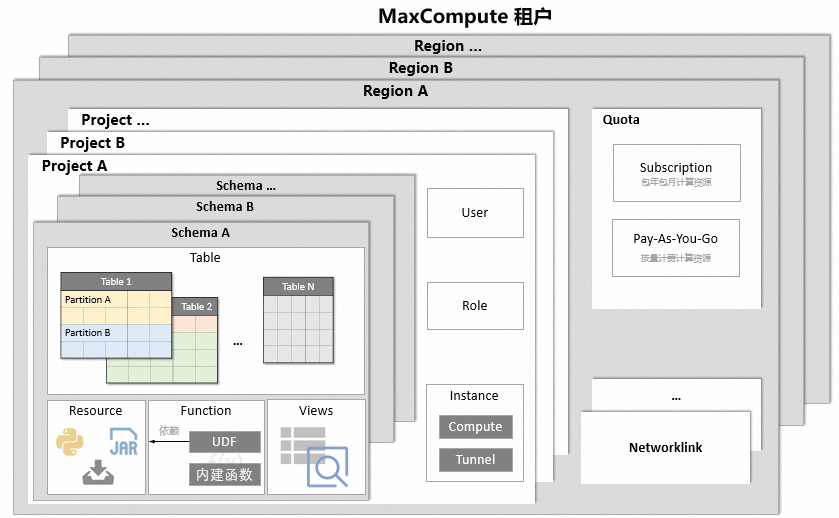
| 核心概念 | 说明 |
|---|---|
| Project(项目) | 项目是MaxCompute的基本组织单元,类似于传统数据库的Database或Schema的概念,是进行多用户隔离和访问控制的主要边界。更多项目信息,请参见项目 |
| Table(表) | 表是MaxCompute的数据存储单元。更多表信息,请参见表。 |
| Partition(分区) | 分区Partition是指一张表下,根据分区字段(一个或多个字段的组合)对数据存储进行划分。如果表没有分区,数据是直接放在表所在的目录下。如果表有分区,每个分区对应表下的一个目录,数据是分别存储在不同的分区目录下。更多分区信息,请参见分区。 |
| View(视图) | 视图是在表之上建立的虚拟表,它的结构和内容都来自表。一个视图可以对应一个表或多个表。如果您想保留查询结果,但不想创建表占用存储,可以通过视图实现。更多视图信息,请参见视图操作。 |
| User(用户) | 用户是MaxCompute安全功能中的概念,MaxCompute支持您通过阿里云账号、RAM用户或RAM角色访问MaxCompute。非MaxCompute项目所有者(Project Owner)的用户必须被加入MaxCompute项目中,且被授予相应的权限,才能操作MaxCompute项目中的数据、作业、资源及函数。更多用户管理信息,请参见用户规划与管理。 |
| Role(角色) | 角色是MaxCompute安全功能中的概念,可以理解为拥有相同权限的用户的集合。多个用户可以同时存在于一个角色下,一个用户也可以隶属于多个角色。给角色授权后,该角色下的所有用户拥有相同的权限。更多角色管理信息,请参见角色规划。 |
| Resource(资源) | 资源是MaxCompute中特有的概念。当您使用MaxCompute的自定义函数(UDF)或MapReduce功能时,需要依赖资源来完成。更多资源信息,请参见资源。 |
| Function(函数) | MaxCompute提供函数功能,包括内建函数和UDF。更多函数信息,请参见函数。 |
| Instance(实例) | 即实际运行作业的一个具体实例,类同Hadoop中Job的概念。详情请参见任务实例。 |
| Quota(配额) | 配额是MaxCompute的计算资源池,提供作业运行所需计算资源。更多配额信息,请参见配额。 |
| Networklink(网络连接) | 当您使用外部表、UDF或湖仓一体功能时,MaxCompute默认未建立与外网或VPC网络间的网络连接,您需要开通网络连接以访问外网或VPC中的目标服务(例如HBase、RDS、Hadoop等)。更多开通网络连接信息,请参见网络开通流程。 |
| Schema | MaxCompute支持Schema,在Project之下对Table、Resource、Function进行归类。更多Schema信息,请参见Schema操作。 |
通常MaxCompute的各层级概念的组织模式如下:
租户代表组织,以企业为例,一个企业可以在不同地域开通MaxCompute按量付费服务或预先购买包年包月计算资源(Quota)。
企业内的各个部门在开通服务的地域内创建和管理自己的项目(Project),用于存储该部门的数据。项目内可以存储多种类型对象,例如表(Table)、资源(Resource)、函数(Function)和实例(Instance)等。如果您有需要,也可以通过创建Schema,在项目之下进一步对上述对象进行归类,详情请参见Schema操作。各部门可以在项目内通过用户与角色的管控,对项目内的各类数据进行权限控制。
项目产生的存储费用以项目粒度出账。如果您使用按量付费计算资源,则查询费用计入运行查询的项目。如果您使用包年包月计算资源,则不再另收查询费用。
组织模式示例如下图所示:
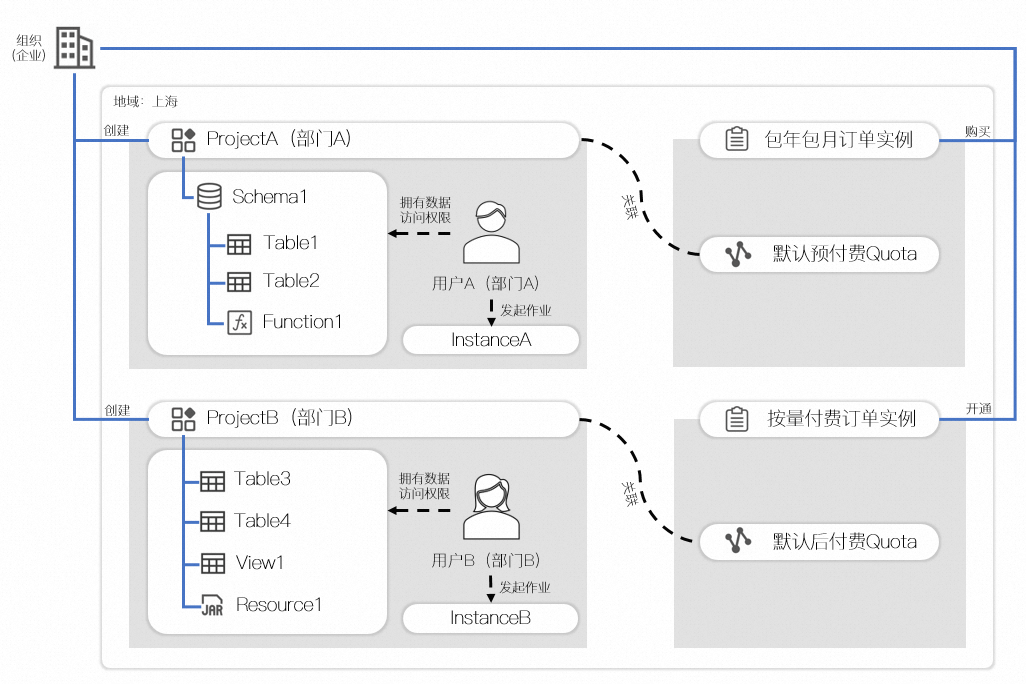
在此示例中,某企业在上海地域开通了按量付费服务(默认后付费Quota),并且购买了包年包月规格计算资源(默认预付费Quota)。
-
部门A创建了项目A,项目A包含一个Schema1,Schema内存储了表1、表2、以及函数1,关联了默认预付费Quota,部门A的用户A被授予了项目A数据的访问权限,并且可以发起作业,所有作业默认使用的计算资源为默认预付费Quota。
-
部门B创建了项目B,项目B没有开启按Schema存储,所以项目下直接存储了表3、表4、视图1和资源1,关联了默认后付费Quota,部门B的用户B被授予了项目B数据的访问权限,并且可以发起作业,所有作业默认使用的计算资源为默认后付费Quota。
2.2 项目
项目(Project)是MaxCompute的基本组织单元,它类似于传统数据库的Database或Schema的概念,是进行多用户隔离和访问控制的主要边界。项目中包含多个对象,例如表(Table)、资源(Resource)、函数(Function)和实例(Instance)等,您可以在一个项目中创建表、上传数据、开发作业,并根据需要分配不同的计算资源。
MaxCompute为您提供方便的项目操作与管理。
-
开通MaxCompute服务后,需要通过项目使用MaxCompute,如何创建MaxCompute项目,详情请参见创建MaxCompute项目。
-
创建MaxCompute项目后,您需要进入项目才可以执行后续开发、分析、运维等一系列操作。详情请参见项目空间操作。
-
MaxCompute提供项目数据保护机制,为数据安全提供保障。详情请参见安全操作。
-
MaxCompute提供跨项目的资源访问。
-
一个用户可以同时拥有多个项目的权限。通过安全授权,可以在一个项目中访问另一个项目中的对象,详情请参见基于Package跨项目访问资源。
说明
若您通过DataWorks创建MaxCompute,需要先创建DataWorks工作空间,详情请参见DataWorks简单模式与标准模式工作空间。DataWorks工作空间名称和MaxCompute项目名称会存在不一致的情况,请您后续进行数据开发时注意明确项目名称。
MaxCompute支持一种特殊类型的项目,即外部项目(External Project)。
-
外部项目无法被独立创建和使用,需要配合数据湖集成,用以实现访问和管理Hadoop集群Hive数据库中的表数据,或数据湖构建DLF中的表数据。详情参见MaxCompute湖仓一体。
-
外部项目本身没有执行作业的权限,需要关联到MaxCompute项目,通过
<external_project_name>.<table_name>的方式访问外部项目中的表数据。详情请参见使用SQL管理外部项目。 -
外部项目本身不产生计费,查询所用的计算资源归属为关联的MaxCompute内部项目。
相关文档
若您需要对项目空间内的资源使用情况进行限制和管理,防止单个用户或项目消耗过多资源而影响整个系统的稳定性,可通过合理设置配额(Quota)实现。详情请参见配额。
2.3 配额
配额(Quota)是MaxCompute的计算资源池,为MaxCompute SQL、MapReduce、Spark、Mars、PAI等计算作业提供所需计算资源(CPU及内存)。您可以根据实际业务合理设置配额组,确保资源的合理分配和利用,防止某一部分任务占用过多资源而影响其他任务的正常执行。
MaxCompute计算资源单位为CU,1 CU包含1 CPU及4 GB内存。您可购买的Quota分为包年包月计算资源和按量计费计算资源两种,分别对应包年包月规格类型和按量计费规格类型,更多规格信息,请参见规格类型。
如果您购买的Quota为包年包月计算资源,可进一步通过MaxCompute管家进行如下更细粒度的管理:
您可以通过如下方式关联MaxCompute项目及配额组,项目关联配额组后,MaxCompute项目中提交的计算作业将默认使用所关联的配额组进行计算:
- 在创建MaxCompute项目时,您可以通过配额组参数选择需要关联的配额组。
- 对于存量项目,您可以通过MaxCompute控制台的项目管理修改项目关联的配额组,详情请参见配置项目。
说明
建议您根据项目业务情况为不同的MaxCompute项目关联不同的配额组。
相关文档
- Quota的调度策略请参见Quota调度策略说明。
- 更多关于Quota管理的信息请参见Quota管理(新版)。
2.4 表
表是MaxCompute的数据存储单元。它在逻辑上是由行和列组成的二维结构,每行代表一条记录,每列表示相同数据类型的一个字段。MaxCompute的表类似于传统关系型数据库中的表,可以存储结构化数据,并且使用SQL进行查询和分析。
MaxCompute中不同类型计算任务的操作对象(输入、输出)都是表。您可以创建表、删除表以及向表中导入数据。
说明
DataWorks的数据开发模块可以对MaxCompute表进行新建、收藏、修改数据生命周期管理、修改表结构和数据表/资源/函数权限管理审批等操作。
MaxCompute的表格有两种类型:内部表和外部表(MaxCompute 2.0版本开始支持外部表)。
-
对于内部表,所有的数据都被存储在MaxCompute中,表中列的数据类型可以是MaxCompute支持的任意一种数据类型版本说明。
-
对于外部表,MaxCompute并不真正持有数据,表格的数据可以存放在OSS或OTS中 。MaxCompute仅会记录表格的Meta信息,您可以通过MaxCompute的外部表机制处理OSS或OTS上的非结构化数据,例如视频、音频、基因、气象、地理信息等。
相关文档
外部表相关信息请参见外部表概述,您可以根据该文档对外部表执行创建、读取及写入等操作。
2.5 分区
分区表是指拥有分区空间的表,即将表数据按照某个列或多个列进行划分,从而将表中的数据分散存储在不同的物理位置上。合理设计和使用分区,可以提高查询性能、简化数据管理,并支持更灵活的数据访问和操作。
概述
分区可以理解为分类,通过分类把不同类型的数据放到不同的目录下。分类的标准就是分区字段,可以是一个,也可以是多个。
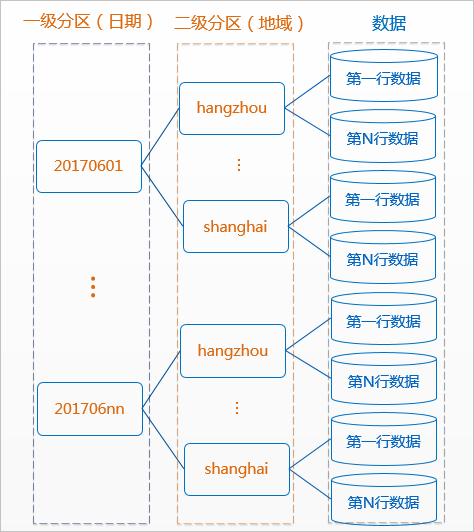
MaxCompute将分区列的每个值作为一个分区(目录),您可以指定多级分区,即将表的多个字段作为表的分区,分区之间类似多级目录的关系。
分区表的意义在于优化查询。查询表时通过WHERE子句查询指定所需查询的分区,避免全表扫描,提高处理效率,降低计算费用。使用数据时,如果指定需要访问的分区名称,则只会读取相应的分区。
部分对分区操作的SQL的运行效率较低,会给您带来较高的费用,例如插入或覆写动态分区数据(DYNAMIC PARTITION)。
对于部分操作MaxCompute的命令,处理分区表和非分区表时语法有差别,详情请参见表操作和INSERT操作。
使用限制
- 单表分区层级最多为6级。
- 单表分区数最大值为60000个。
- 单次查询允许查询最多的分区个数为10000个。
- STRING分区类型的分区值不支持使用中文。
使用说明
分区数据不宜过小,如果创建很多过小分区,会导致计算查询性能下降。建议单分区数据不要小于一万行。
分区列的数据类型
MaxCompute 2.0数据类型版本支持的分区字段为TINYINT、SMALLINT、INT、BIGINT、VARCHAR、STRING。
MaxCompute 1.0数据类型版本支持的分区字段仅有STRING。虽然可以指定分区列的类型为BIGINT,但是除了表的字段显示为BIGINT类型,任何其他情况(例如,字段的计算和比较)下都当作STRING类型处理。执行如下语句后,返回结果为空。
---创建表parttest。
create table parttest (a bigint) partitioned by (pt bigint);
---向表中插入数据。
insert into parttest partition(pt)(a,pt) values (1, 1);
insert into parttest partition(pt)(a,pt) values (1, 10);
---查询表中字段pt大于等于2的行。
select * from parttest where pt >= '2';示例
-
创建分区。
--创建一个二级分区表,以日期为一级分区,地域为二级分区 CREATE TABLE src (shop_name string, customer_id bigint) PARTITIONED BY (pt string,region string); -
使用分区列作为过滤条件查询数据。
--正确使用方式。MaxCompute在生成查询计划时只会将'20170601'分区下region为'hangzhou'二级分区的数据纳入输入中。 select * from src where pt='20170601'and region='hangzhou'; --错误的使用方式。在这样的使用方式下,MaxCompute并不能保障分区过滤机制的有效性。pt是STRING类型,当STRING类型与BIGINT(20170601)比较时,MaxCompute会将二者转换为DOUBLE类型,此时有可能会有精度损失。 select * from src where pt = 20170601;
相关文档
分区相关操作(如添加分区、修改分区值等)命令请参见分区和列操作。
2.6 生命周期
MaxCompute表的生命周期(Lifecycle),指表(分区)数据从最后一次更新的时间算起,在经过指定的时间后没有变动,则此表(分区)将被MaxCompute自动回收。这个指定的时间就是生命周期。通过设置生命周期可以实现自动数据清理或数据保留,降低存储成本。
生命周期说明
-
生命周期单位为天,取值为正整数。
-
对于非分区表,如果表数据在生命周期内没有被修改,经过指定天数后此表将会被MaxCompute自动回收(类似DROP TABLE操作)。生命周期从最后一次表数据被修改的时间(LastModifiedTime)开始计算。
-
对于分区表,每个分区可以分别被回收。在生命周期内未被修改数据的分区,经过指定的天数后此分区将会被回收,否则会被保留。每个分区的生命周期是从最后一次分区数据被修改的时间(LastModifiedTime)开始计算。不同于非分区表,分区表的最后一个分区被回收后,该表不会被删除。
说明
生命周期回收为每天定时启动,扫描全量分区。LastModifiedTime需要超过生命周期指定的时间才会回收。
假设某个分区表生命周期为1天,该分区数据最后一次被修改的时间是2020年02月17日15时。如果在2020年02月18日15时之前扫描此表(不到一天),则不会回收表分区。如果2020年02月19日回收扫描时发现表分区LastModifiedTime超过生命周期指定的时间,则上述分区会被回收。
生命周期主要提供定期回收表或分区的功能,每天根据服务的繁忙程度,不定时回收。不能确保表或分区的生命周期到期后立刻被回收。
删除表后,表的所有属性信息全部会被删除,包括生命周期。新建同名表后,表的生命周期以新设置的属性为准。
-
只能在表级别设置生命周期,不能在分区级别设置生命周期。为分区表指定的生命周期适用于该表的所有分区。创建表时即可指定生命周期。
-
如果您没有为表指定生命周期,则表(分区)不会根据生命周期规则被MaxCompute自动回收。
-
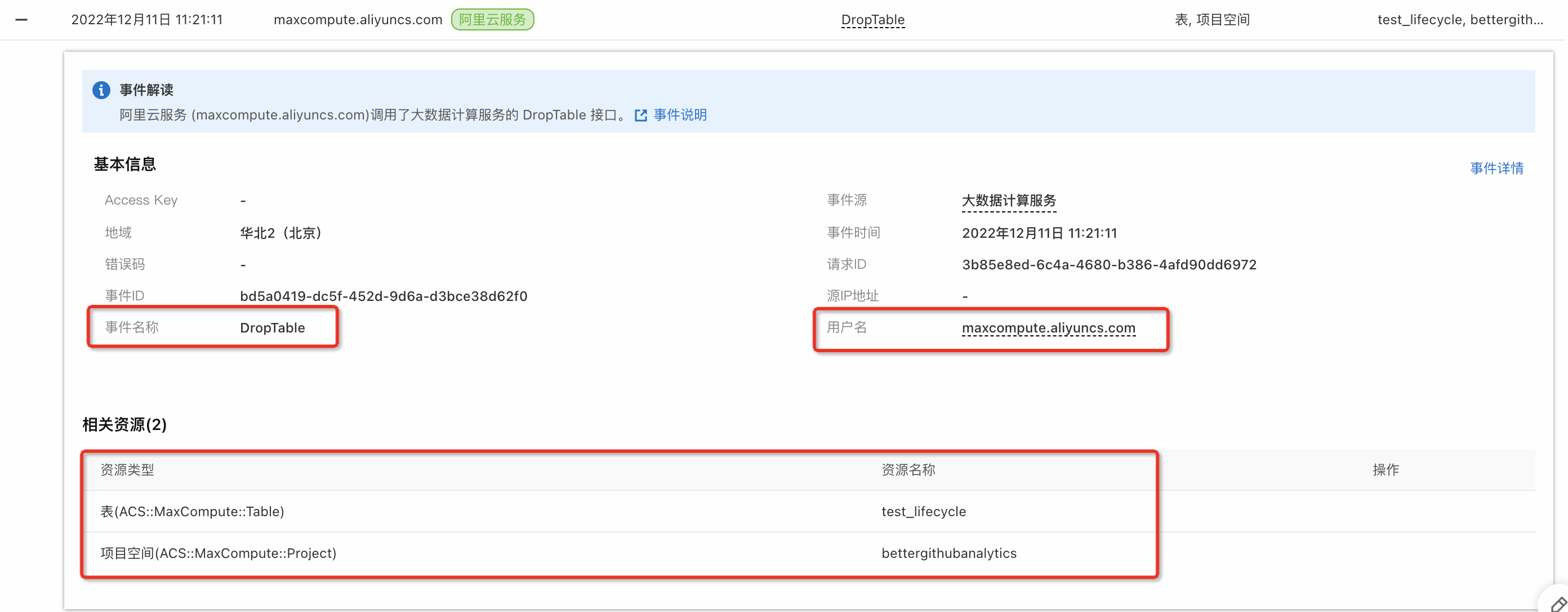
用于执行生命周期回收数据操作的用户是阿里云服务:
maxcompute.aliyuncs.com,您可以在操作审计中获取操作记录,详情请参见事件查询快速入门。示例如下:- 表
bettergithubanalytics.test_lifecycle依据生命周期被MaxCompute自动回收,可看到如下记录。
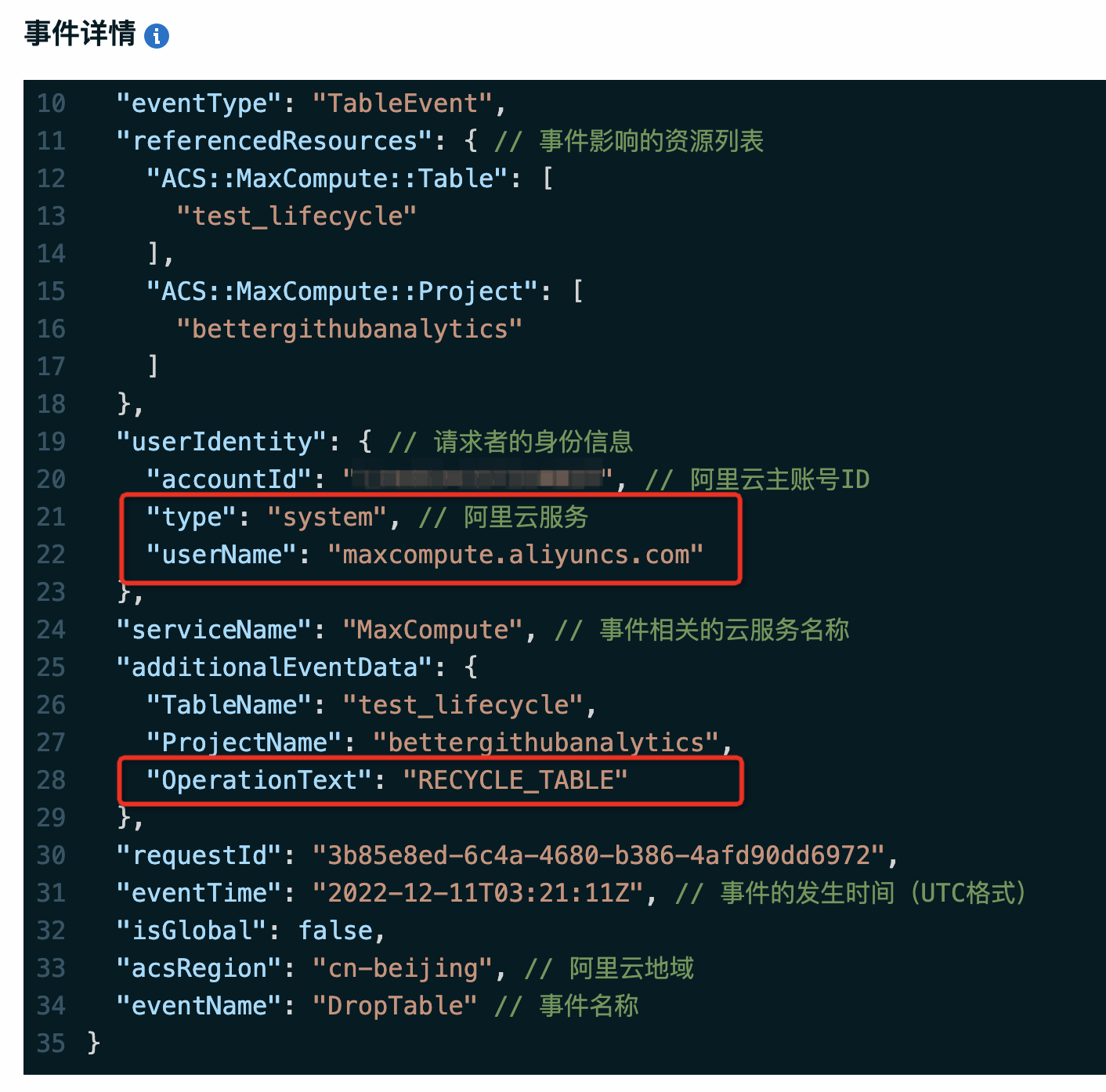
- 表
bettergithubanalytics.sale_detail的分区sale_date=2013/region=china依据生命周期被MaxCompute自动回收,可看到如下记录。


- 表分区的回收操作记录也支持使用DataWorks的数据地图功能查看,详情请参见数据地图概述。其显示操作人账号为MaxCompute系统账号
odps_user@aliyun.com,即名称为maxcompute.aliyuncs.com的阿里云服务。

- 表
相关文档
- 关于建表时如何指定、修改表生命周期、修改表
LastModifiedTime等操作,请参见表操作。 - 更多关于生命周期的操作,例如对已有表或新建表设置生命周期、禁止或恢复生命周期操作,请参见生命周期操作。
2.7 资源
资源是指为了完成数据处理任务而需要使用的各种辅助文件或程序。这些资源通常用于运行MapReduce或UDF(User-Defined Function)等作业。MaxCompute的资源管理功能允许用户上传、注册和管理这些资源。
概念
资源(Resource)是MaxCompute的特有概念,如果您想使用MaxCompute的自定义函数(UDF)或MapReduce功能,需要依赖资源来完成,如下所示:
- SQL UDF:您编写UDF后,需要将编译好的JAR包以资源的形式上传到MaxCompute。运行此UDF时,MaxCompute会自动下载这个JAR包,获取您的代码来运行UDF,无需您干预。上传JAR包的过程就是在MaxCompute上创建资源的过程,这个JAR包是MaxCompute资源的一种。
- MapReduce:您编写MapReduce程序后,将编译好的JAR包作为一种资源上传到MaxCompute。运行MapReduce作业时,MapReduce框架会自动下载这个JAR资源,获取您的代码。
您同样可以将文本文件以及MaxCompute中的表作为不同类型的资源上传到MaxCompute,您可以在UDF及MapReduce的运行过程中读取、使用这些资源。MaxCompute提供了读取、使用资源的接口。详情请参见资源使用示例及UDF使用说明。
说明
MaxCompute的自定义函数(UDF)或MapReduce对资源的读取有一定的限制,详情请参见使用限制。
资源类型
MaxCompute支持上传的单个资源大小上限为2048 MB,资源包括以下几种类型:
-
File类型:仅支持.zip、.so和.jar类型的File资源。
-
Table类型:MaxCompute中的表。
说明
MapReduce引用的Table类型资源中,Table字段类型目前只支持BIGINT、DOUBLE、STRING、DATETIME、BOOLEAN,其他类型暂未支持。
JAR类型:编译好的Java JAR包。
Archive类型:通过资源名称中的后缀识别压缩类型,支持的压缩文件类型包括.zip、.tgz、.tar.gz、.tar、.jar。
Python类型:您编写的Python代码,用于注册Python UDF函数。
相关文档
- 资源的相关操作请参见资源操作或MaxCompute资源管理。
- 如果您的代码或函数中需要使用MaxCompute资源文件,则需先创建或上传资源至目标工作空间后再引用。详情请参见创建并使用MaxCompute资源。
2.8 函数
函数是用来在SQL语句中执行特定操作的编程构件,包括内建函数和用户自定义函数(User Defined Function,以下简称UDF)。
MaxCompute为您提供了SQL计算功能,您可以在MaxCompute SQL中使用系统的内建函数完成一定的计算和计数功能。但当内建函数无法满足要求时,您可以使用MaxCompute提供的Java或Python编程接口开发自定义函数。
- 内建函数:可以简化SQL查询的编写,提高数据处理的效率。
- 自定义函数(UDF):为MaxCompute提供了高度的灵活性,允许您根据具体业务逻辑进行定制化的数据计算和分析。
自定义函数(UDF)可以进一步分为标量值函数(UDF)、自定义聚合函数(UDAF)和自定义表值函数(UDTF)三种类型。
您在开发完成UDF代码后,需要将代码编译成Jar包,并将此Jar包以Jar资源的形式上传到MaxCompute,最后在MaxCompute中注册此UDF。
说明
使用UDF时,只需在SQL中指明UDF的函数名及输入参数即可,使用方式与MaxCompute提供的内建函数相同。
相关文档
2.9 任务
任务(Task)是MaxCompute的基本计算单元,用户通过编写SQL或者MapReduce程序来表达数据处理的逻辑,然后提交这些程序到MaxCompute服务上执行,MaxCompute会把这些程序转换为一个或多个任务,并在分布式环境中并行执行。
对于您提交的大多数任务,特别是计算型任务,例如SQL DML语句、MapReduce,MaxCompute会对其进行解析,得到任务的执行计划。执行计划由具有依赖关系的多个执行阶段(Stage)构成。
目前,执行计划在逻辑上可以被看作一个有向图,图中的点是执行阶段,各个执行阶段之间的依赖关系是图的边。MaxCompute会依照图(执行计划)中的依赖关系执行各个阶段。在同一个执行阶段内,会有多个进程,也称之为Worker,共同完成该执行阶段的计算工作。同一个执行阶段的不同Worker只是处理的数据不同,执行逻辑完全相同。计算型任务在执行时,会被实例化,您可以对这个实例(Instance)进行操作,例如获取实例状态(Status Instance)、终止实例运行(Kill Instance)等。
部分MaxCompute任务并不是计算型的任务,例如SQL中的DDL语句,这些任务本质上仅需要读取、修改MaxCompute中的元数据信息。因此,这些任务无法被解析出执行计划。
说明
在MaxCompute中,并不是所有的请求都会被转化为任务(Task),例如项目空间(Project)、资源(Resource)、自定义函数(UDF)及实例(Instance)的操作均不需要通过MaxCompute的任务来完成。
相关文档
查看MaxCompute SQL对应的DML语句的执行计划结构,可使用explain语句,详情请参见EXPLAIN。
2.10 任务实例
在MaxCompute中,您提交的SQL、Spark和MapReduce任务在执行时会被实例化,以MaxCompute实例(下文简称为实例或Instance)的形式存在。这个实例代表了该任务从开始执行到完成的整个生命周期,并包含了任务的各种运行信息,如任务ID、开始时间、结束时间、运行状态、日志等。
实例会经历运行(Running)和结束(Terminated)两个阶段。
运行阶段的实例状态为Running(运行中),而结束阶段则会有Success(成功)、Failed(失败)和Cancelled(被取消)三种状态。您可以根据运行任务时MaxCompute给出的实例ID进行查询、改变任务的状态等操作,示例如下。
--查看某实例的状态。
status instance_id;
--停止某实例,将其状态设置为Cancelled。
kill instance_id;
--查看某实例的运行日志。
wait instance_id;其中,instance_id为需要查询的实例ID号,请您根据实际的ID号进行替换。
相关文档
更多关于实例操作的信息请参见资源操作。
三、ACID语义
本文为您介绍MaxCompute在作业并发情况下ACID的语义及Transactional表的ACID语义。
3.1 相关术语
- 操作:指在MaxCompute上提交的单个作业。
数据对象:指持有实际数据的对象,例如非分区表、分区。 - INTO类作业:指INSERT INTO、DYNAMIC INSERT INTO等包含关键字INTO的SQL作业。
- OVERWRITE类作业:指INSERT OVERWRITE、DYNAMIC INSERT OVERWRITE等包含关键字OVERWRITE的SQL作业。
- Tunnel数据上传:可以归结为INTO类或OVERWRITE类作业。
3.2 ACID语义描述
- 原子性(Atomicity):一个操作或是全部完成,或是全部不完成,不会结束在中间某个环节。
- 一致性(Consistency):从操作开始至结束的期间,数据对象的完整性没有被破坏。
- 隔离性(Isolation):操作独立于其他并发操作完成。
- 持久性(Durability):操作处理结束后,对数据的修改将永久有效,即使出现系统故障,该修改也不会丢失。
3.3 MaxCompute并发写操作的ACID特性
- 原子性(Atomicity)
- 任何时候MaxCompute会保证在冲突时只有一个作业执行成功,其他冲突作业执行失败。
- 对于单个表或分区的CREATE、OVERWRITE、DROP操作,可以保证其原子性。
- 跨表操作时不支持原子性(例如MULTI-INSERT)。
- 在极端情况下,以下操作可能不保证原子性:
- DYNAMIC INSERT OVERWRITE多于一万个分区,不支持原子性。
- INTO类操作:这类操作失败的原因是事务回滚时数据清理失败,但不会造成原始数据丢失。
- 一致性(Consistency)
- OVERWRITE类作业可保证一致性。
- INTO类作业在冲突失败后可能存在失败作业的数据残留。
- 隔离性(Isolation)
- 非INTO类操作保证读已提交。
- INTO类操作存在读未提交的场景。
- 持久性(Durability)
- MaxCompute保证数据的持久性。
3.4 Transactional表的ACID特性
Transactional表的ACID特性在MaxCompute并发写操作的ACID特性基础上,支持如下新特性:
- INTO类操作保证读已提交,作业冲突执行失败后无数据残留。
- 对于单个非分区表或单个分区的UPDATE、DELETE、MERGE小文件操作,可以保证其原子性。
例如,当两个UPDATE操作并发修改同一分区时,只会有一个UPDATE操作执行成功。不会存在一个UPDATE操作部分执行成功,也不会存在两个UPDATE操作分别执行成功的情况。
操作并发冲突说明
当作业并发运行且写入相同目标表时,可能出现冲突。产生冲突时,先结束的作业会执行成功,后结束的作业可能会因冲突而报错。
下表为作业并发提交场景下,对同一个非分区表或分区的并发操作先后结束的冲突说明。
| 作业类型 | INSERT OVERWRITE/TRUNCATE作业(后结束) | INSERT INTO作业(后结束) | UPDATE/DELETE作业(后结束) | MERGE小文件作业(后结束) |
|---|---|---|---|---|
| INSERT OVERWRITE/TRUNCATE作业(先结束) |
|
|
|
|
| INSERT INTO作业(先结束) |
|
|
|
|
| UPDATE/DELETE作业(先结束) |
|
|
|
|
| MERGE小文件作业(先结束) |
|
|
|
|
综上所述,冲突报错规则概括如下:
- INSERT类操作不会因为数据变化而产生冲突报错。
- UPDATE、DELETE、MERGE小文件操作会因为目标非分区表或分区数据变化而产生冲突报错。
原文地址:
1 Comment