CountDownLatch 与 CyclicBarrier
J.U.C 为我们封装了一些有用的控制并发流程的工具,CountDownLatch、CyclicBarrier、Semaphore 以及 Exchanger,本文先来解释前两个:
- CountDownLatch:倒计时器
- CyclicBarrier:循环栅栏(同步屏障)
CountDownLatch
“倒计时器” 这个名字听起来就很好理解,不用看文档我们大概就能猜出来,一个线程执行一定的时间后另一个线程才可以开始(继续)执行。
来看个场景,假设我们需要分别处理两件事情,当这两件事情都执行完毕后,打印出 FINISH 字样。
我们先来想一下,如果没有 CountDownLatch 这个工具,怎么解决这个问题?
join 方法。
这个之前的文章中并没有讲过,不是很难,这里给大家简单解释一遍:
如果线程 A 执行到了 线程 B.join() 语句,其含义就是,当前线程 A 等待线程 B 结束运行之后才从 线程 B.join() 这条语句返回然后继续执行。
代码如下,我们使用两个线程分别处理这两件事情:
Thread threadA = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("first thing finish");
}
});
Thread threadB = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("second thing finish");
}
});
threadA.start();
threadB.start();
threadA.join();
threadB.join();
System.out.println("FINISH"); 可以看到,这里实际上有三个线程,主线程 + Thread A + ThreadB,主线程执行到 threadA.join(),需要等到 threadA 执行完才能继续往下执行,接着,走到 threadB.join(),同样的,主线程需要等到 threadB 执行完才能继续往下执行。
Thread 类 除了提供 join() 方法之外,还提供了 join(long millis) 和 join(long millis,int nanos) 两个具备超时特性的方法。也就是说,如果线程在给定的超时时间里没有终止,那么将会从该超时方法中返回。
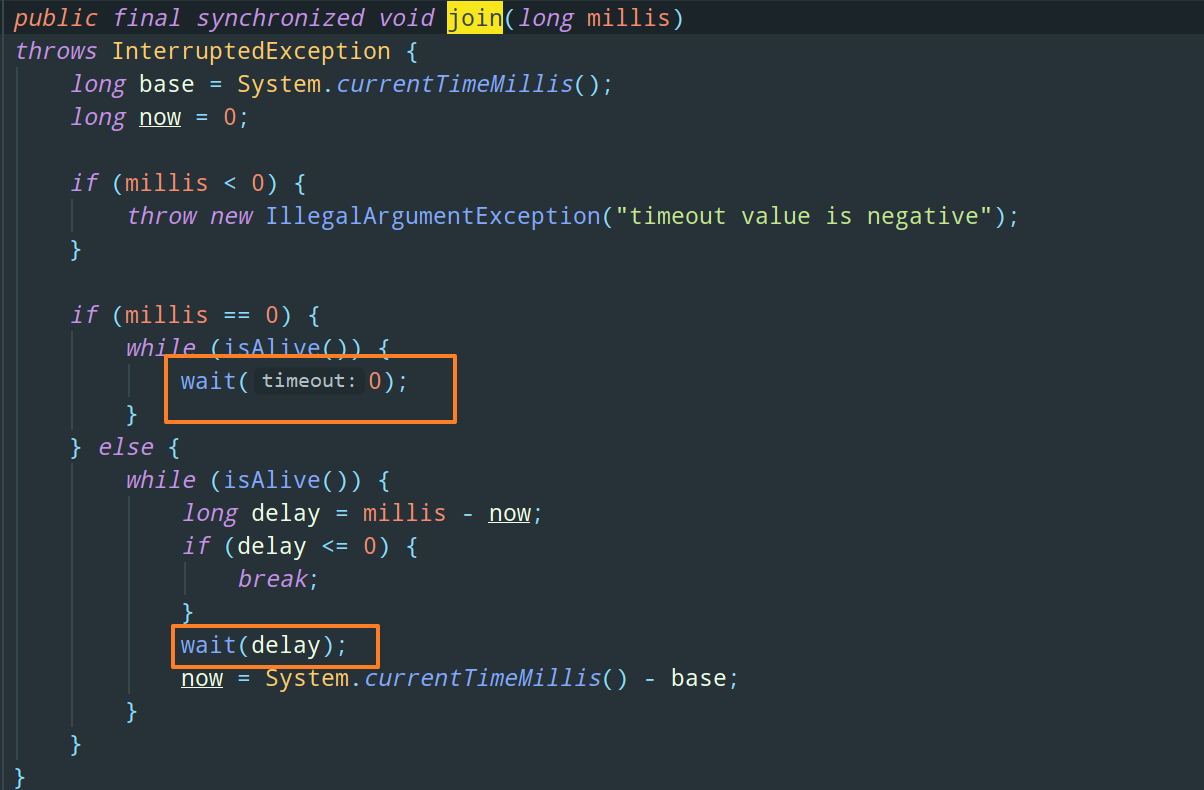
至于 join 的底层原理,其实各位应该也能想出来,肯定是 wait/notify 等待通知机制:
再来看使用 CountDownLatch 如何实现这个场景。

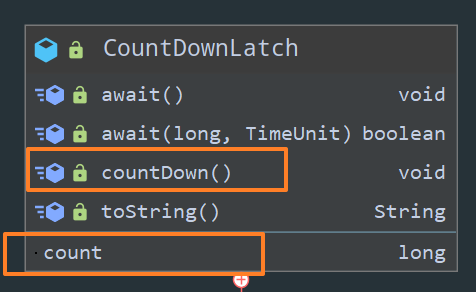
CountDownLatch 的构造函数接收一个 int 类型的参数(count)作为计数器,每调用一次 countDown 方法,这个 count 就会减 1。当 count 不为 0 的时候,我们可以调用 CountDownLatch 的 await 方法阻塞当前线程,直到 count 变为 0,当前线程才可以继续往下执行。
代码如下:
static CountDownLatch countDownLatch = new CountDownLatch(2);
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("first thing finish");
countDownLatch.countDown(); // count --
System.out.println("second thing finish");
countDownLatch.countDown(); // count --
}
}).start();
countDownLatch.await(); // 主线程被阻塞住,直到 count = 0
System.out.println("FINISH"); 怎么样,是不是比原生的 join 方法写起来简单很多,而且只需要 new 一个线程就行了。
CyclicBarrier
Cyclic 翻译为可循环使用的,老实说,“循环栅栏” 这个翻译第一次看的话真的有点让人摸不着头脑,“同步屏障” 这个翻译可能更利于理解。
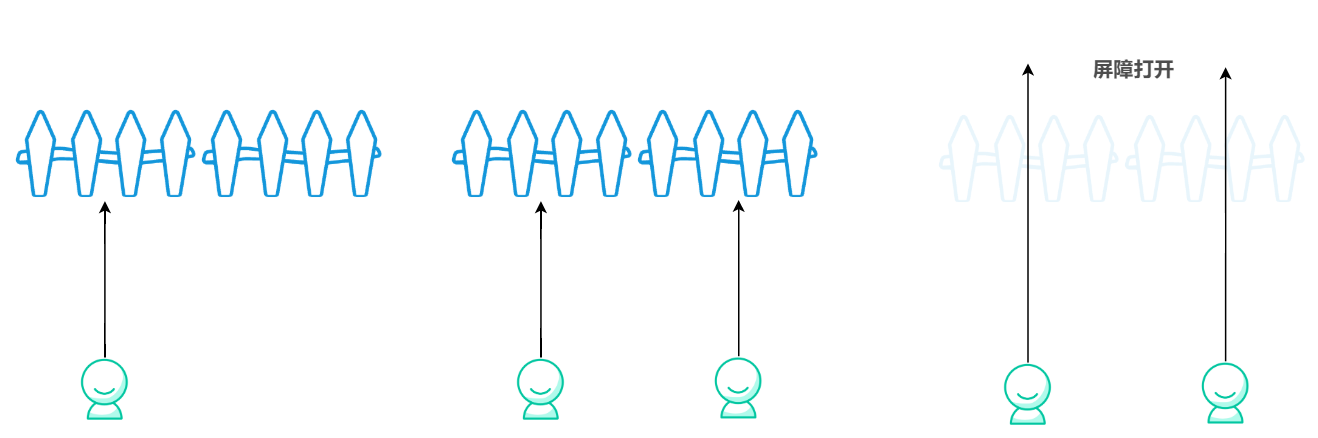
当然了,也不是很难,CyclicBarrier 跟 CountDownLatch 的功能是一样的,即 “等待计数” 功能,具体来说,CyclicBarrier 做的事情是:让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续运行。
CyclicBarrier 默认的构造方法是 CyclicBarrier(int parties),其参数 parties 就表示被屏障拦截的线程数量,每个线程执行完各自的逻辑后可以调用 await 方法告诉 CyclicBarrier 我已经到达了屏障,然后当前线程就会被阻塞。直到抵达屏障的数量达到 parties,屏障打开,被阻塞的线程才可以继续往下执行。
举个例子,我们新建一个 parties = 2 的同步屏障:
static CyclicBarrier cyclicBarrier = new CyclicBarrier(2);
new Thread(new Runnable() {
@Override
public void run() {
cyclicBarrier.await(); // 子线程已达到屏障
System.out.println("child Thread");
}
}).start();
cyclicBarrier.await(); // 主线程已到达屏障
System.out.println("main Thread"); 随着主线程和子线程陆续抵达屏障,parties 数量被满足,屏障打开,各个线程可以接着自己的 await 方法往下执行。如下图:
如果上述代码中,我们传入的 parties 是 3 的话,主线程和子线程就会被一直阻塞住,因为抵达屏障的线程数量不满足 parties,屏障无法打开。
另外,CyclicBarrier 还提供一个更高级的构造函数 CyclicBarrier(int parties,Runnable barrier-Action),就是说,当抵达屏障的线程数量满足 parties 后,在所有被阻塞的线程继续执行之前(即屏障打开之前),率先 barrier-Action 方法。
就好比一堆人要刑满释放了,在出狱之前得给所有人都套上电子锁链,这个意思。
来看如何用 CyclicBarrier 实现上面那个场景题:
static CyclicBarrier cyclicBarrier = new CyclicBarrier(3);
Thread threadA = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("first thing finish");
cyclicBarrier.await(); // threadA 线程已达到屏障
}
});
Thread threadB = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("second thing finish");
cyclicBarrier.await(); // threadB 线程已达到屏障
}
});
threadA.start();
threadB.start();
cyclicBarrier.await(); // 主线程已达到屏障
System.out.println("FINISH"); 戏说不是胡说:Semaphore 与 ExchangerSemaphore
书中把 Semaphore 翻译成信号量,我感觉不是很好理解,翻译为 “许可证” 更好。
我就不整一些特别虚的概念了,直接来给大家举个通俗易懂的例子:
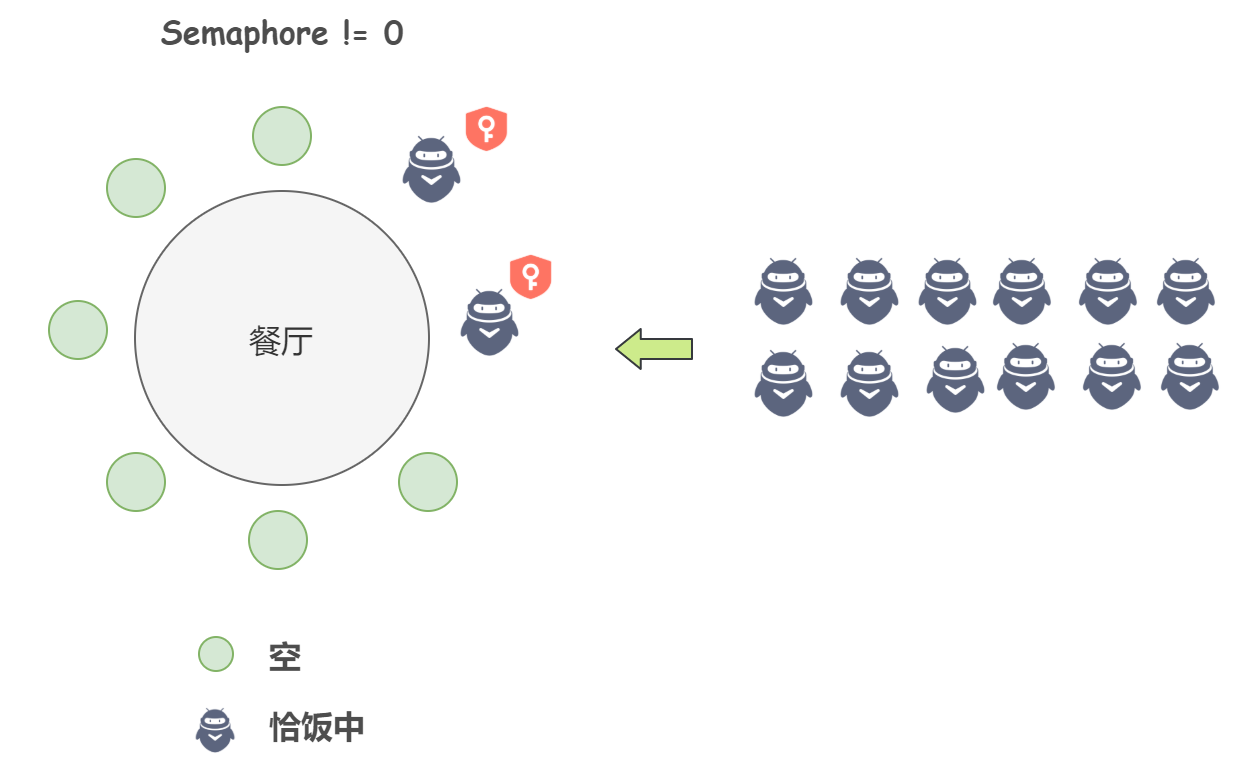
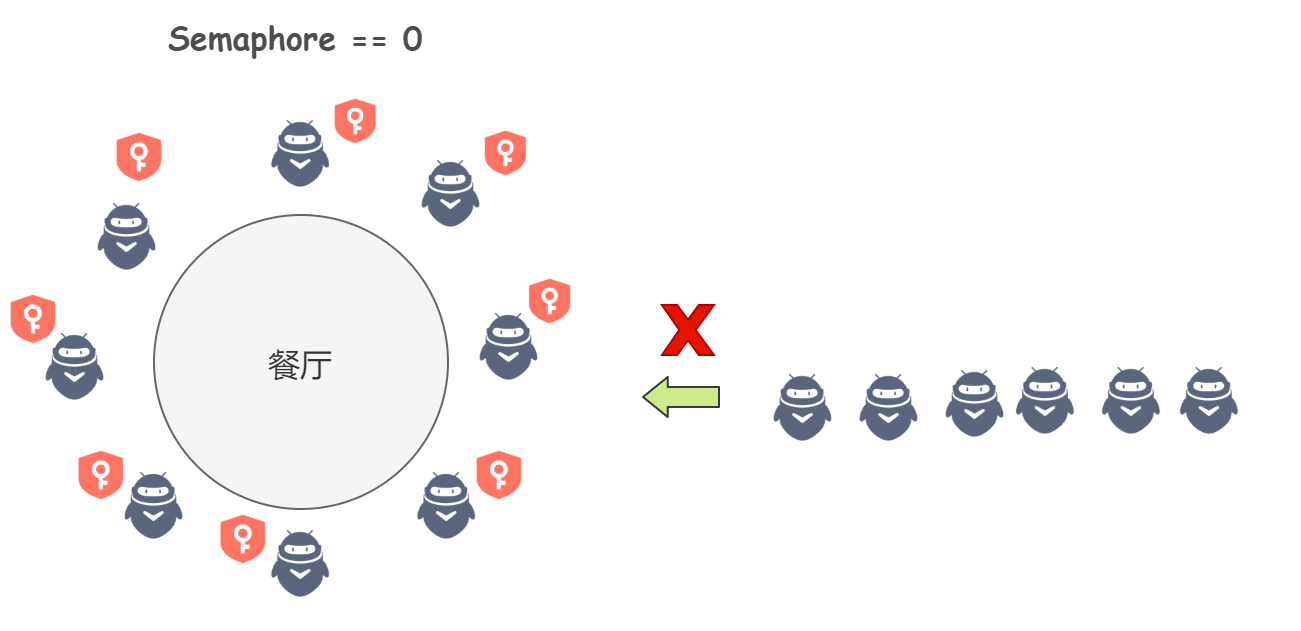
国庆期间我们去餐厅恰饭,一个餐厅只有 20 张椅子,那么同时只有 20 个人可以进去恰饭,也即这 20 个人拥有了许可证,而多出来的人,需要等餐厅内的一些人走了,才能拥有许可证即进入餐厅恰饭。
一个餐厅有 20 张椅子、一个餐厅有 20 张许可证,用代码来表示:
Semaphore s = new Semaphore(20);当一个人走进这家餐厅恰饭, 他首先需要申请获得许可证:
s.acquire()当这个人恰完饭离开餐厅后,他手中的许可证就被释放了,也即可以给别人用了:
s.release()怎么说,Semaphore 是不是很简单?
那具体的应用场景呢?
我们再来举个例子:
假设我们现在需要同时读取几万个文件的数据并存储到数据库中,单线程跑显然效率非常低下,于是呢,我们启动了 30 个线程来同时去读取文件。
读取完文件后还要存储到数据库中,但是,数据库的连接数只有 10 个,也就是说,虽然我们有 30 个读取文件的数据,但是同时只能由 10 个线程来保存数据。或者说,有 30 个人排队恰饭,但是餐馆里只有 10 张椅子,这时候,我们就可以利用 Semaphore 来发放许可证了:
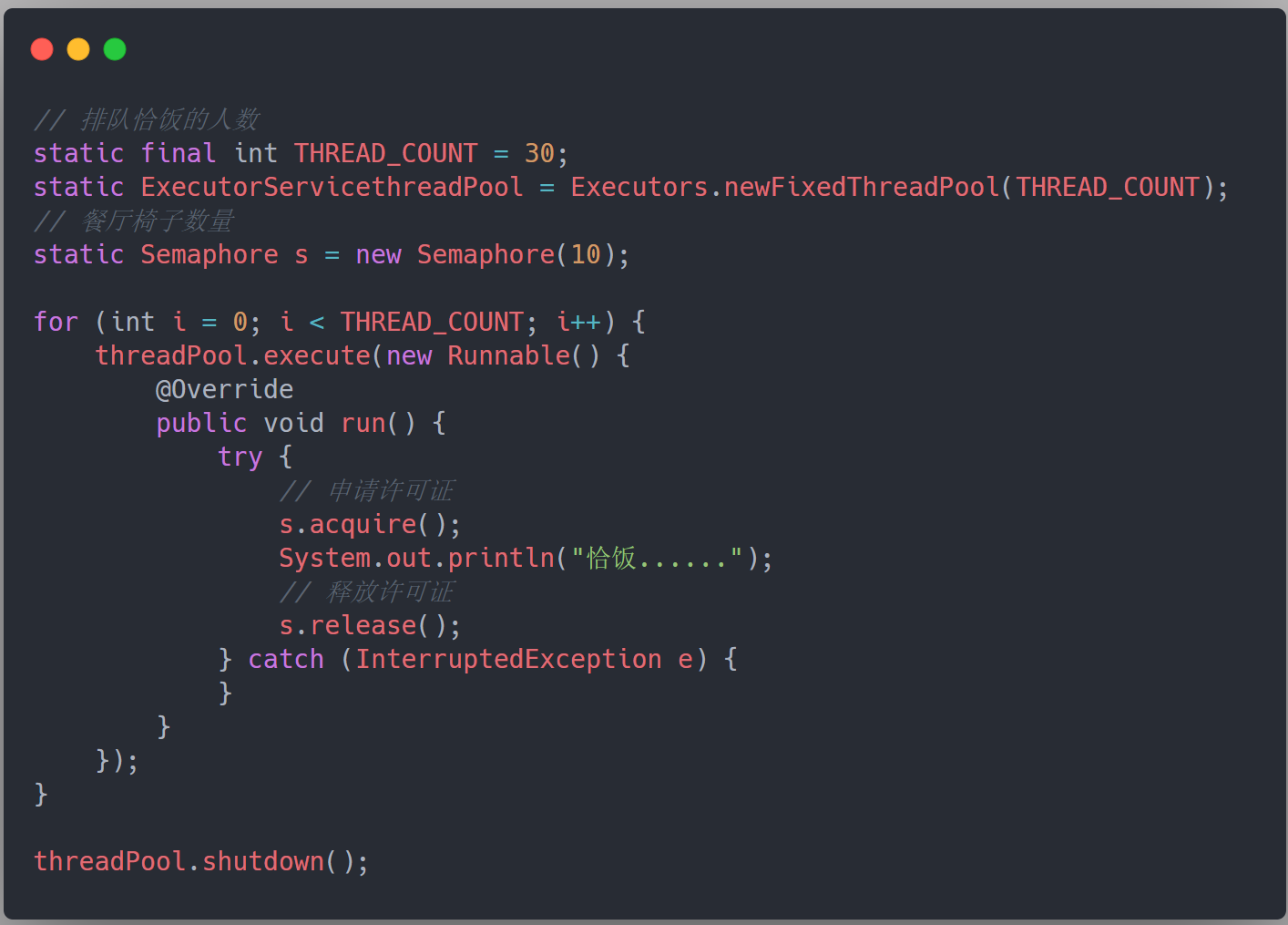
综上,可以看出,Semaphore 最大的用途就是用来做流量控制。
Exchanger
“交换者”,看名字好像有点云里雾里的感觉,不多废话,直接举例:
假设有一个大佬 A 和大佬 B,两个人分别拥有一个金库和一把钥匙,每个金库里分别存着藏宝图的一半,打开这两个金库就能知道大宝箱的具体位置,但是它们各自的钥匙只能打开对方金库的锁,所以这两位大佬想要互相交换钥匙并打开各自的金库,但是它们又都不相信对方,想要找一个中间方来管理,即 Exchanger:
Exchanger<String> exchanger = new Exchanger<String>();泛型即表示他们要交换的东西。
大佬 A 把自己的钥匙交给 Exchanger:
String strA = exchanger.exchange("大佬 A 的钥匙");
// 阻塞住
System.out.println("A: 获取" + strA); 大佬 B 把自己的钥匙交给 Exchanger:
String strB = exchanger.exchange("大佬 B 的钥匙");
System.out.println("B: 获取" + strB); Exchanger 收集了这两把钥匙,开始交换!大佬 A 获得了大佬 B 的钥匙,大佬 B 获得了大佬 A 的钥匙,输出如下:
B: 获取大佬 A 的钥匙
A: 获取大佬 B 的钥匙那具体的应用场景呢?
我们再来举个例子:
比如我们需要把某个重要数据录入到 Excel 中,为了避免错误,A 和 B 两个人同时进行录入,录入到 Excel 之后,系统对这两个 Excel 数据进行校对,看看是否录入一致:
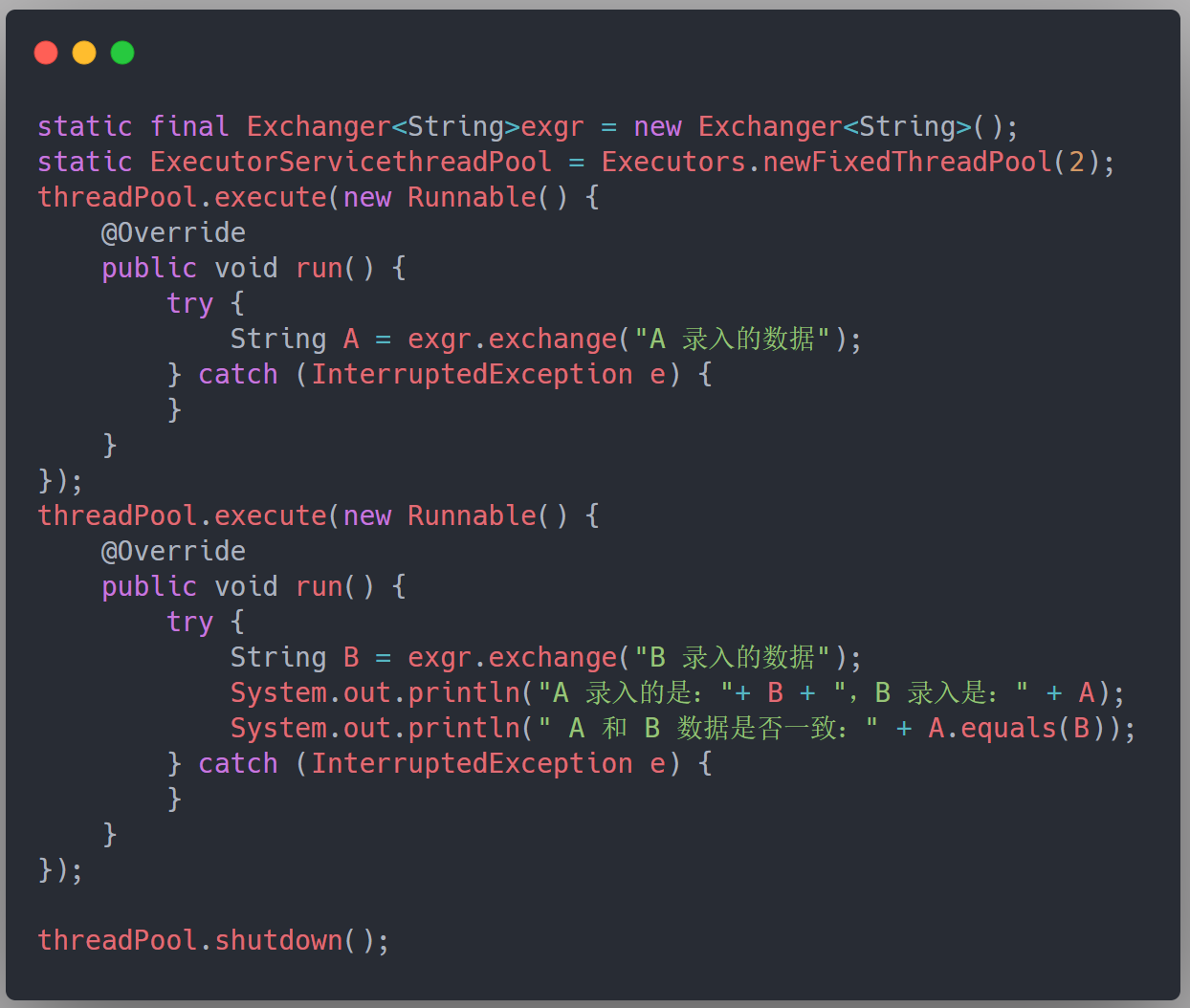
综上,小结一下 Exchanger:
Exchanger 用于进行线程间的数据交换,两个线程通过 exchange 方法交换数据,如果第一个线程先执行 exchange() 方法,它会一直等待第二个线程也执行 exchange 方法,当两个线程都执行完后,这两个线程就可以交换数据,将本线程生产出来的数据传递给对方。
线程隔离术 ThreadLocal
ThreadLocal 称不上是工具类,但是我不知道该怎么分组,所以就放在这里讲吧
ThreadLocal 使用示例
先来看段代码,感受下,什么是线程隔离术:
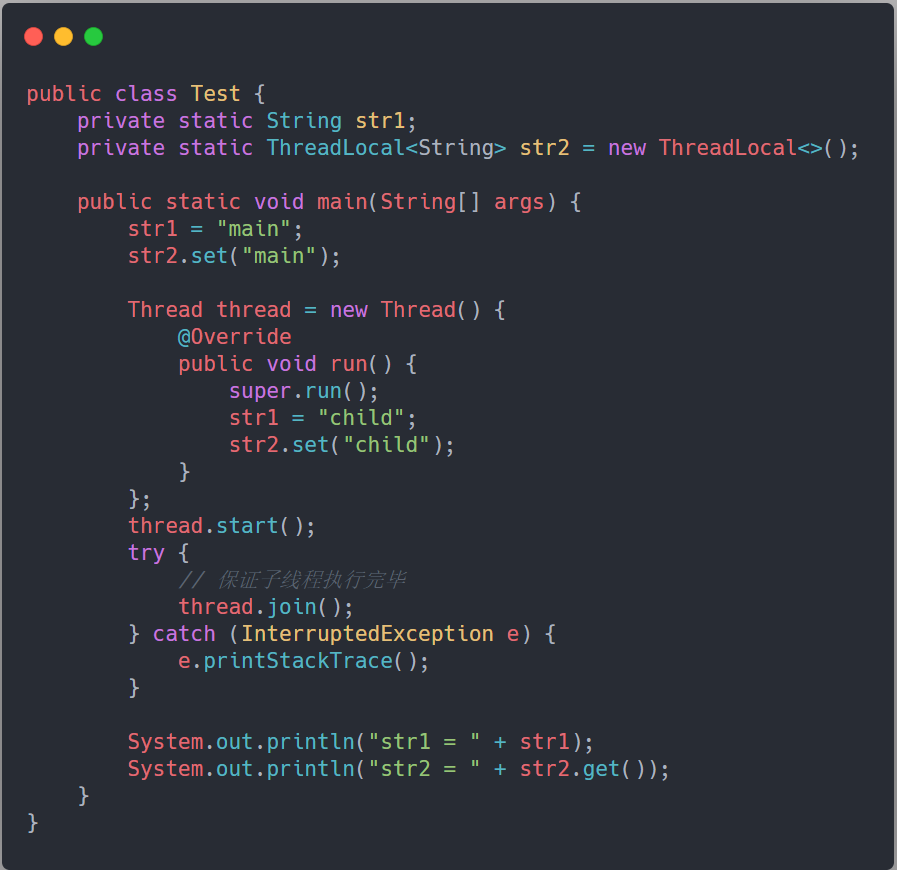
运行结果如下:
- str1 = child
- str2 = main
str1 是 String 类型,而 str2 被 ThreadLocal 类型包裹,显而易见,子线程中对 str2 的修改,主线程中是看不到的。这也就是 “线程隔离术” 的由来。
ThreadLocal 源码分析
看一个新的类的时候呢,我习惯从构造函数开始入手:

尴尬了,ThreadLocal 的构造函数空空如也。
转战上面代码段中出现的 set 方法:

代码很好理解,首先获取当前线程,然后获取当前线程的 ThreadLocalMap,不难看出,当某个线程往 ThreadLocal 中 set 值的时候,其实调用的就是该线程中 ThreadLocalMap 的 set 方法
那么问题来了,这个 ThreadLocalMap 是啥?
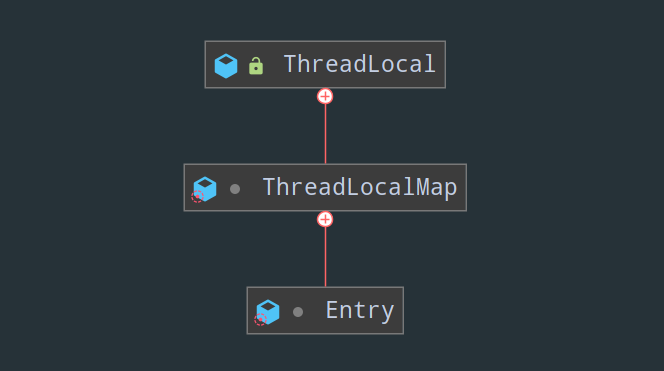
从类结构关系图可以看出,ThreadLocalMap 是 ThreadLocal 的内部类,其中,Entry 是 map 中的节点,从来存储真正的 k-v 数据。
也就是说,当我们往 ThreadLocal 中赋值的时候,其实是在给其内部类 ThreadLocalMap 赋值,更进一步说,是在 ThreadLocalMap 中新建一个 Entry 节点。
再来看一下 ThreadLocal 的 get 方法:
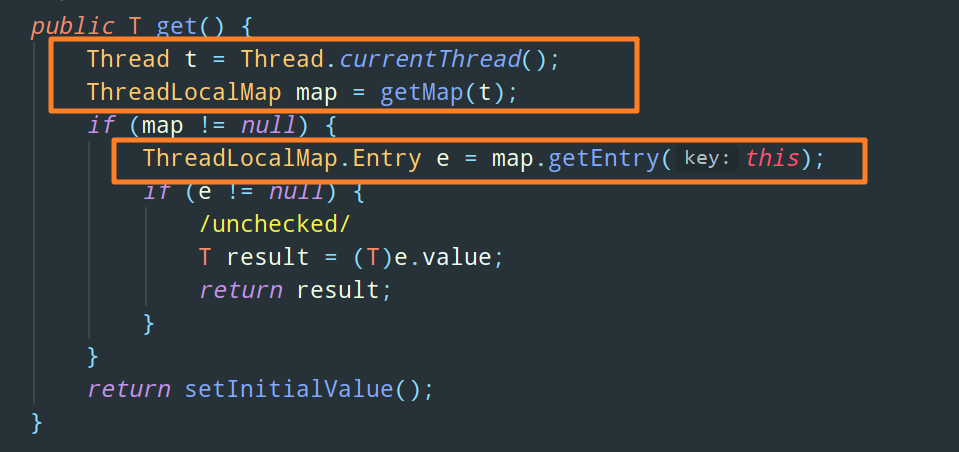
同样的,在 get 方法中也会首先获取到当前线程的 ThreadLocalMap,然后再去根据 key 值获取 Entry 节点
就是说,每个线程的 ThreadLocalMap 是属于线程自己的,ThreadLocalMap 中的 Entry 存储着真正的值,这个值也是属于线程自己的
那么还有一个问题,那就是 Entry 中存储的 key 是什么?
大家想必也看见了,如上图,ThreadLocal 的 get 方法中,map.getEntry() 传入的 key 值是 this,也就是当前 ThreadLocal 的引用
什么情况,ThreadLocal 创建出了 ThreadLocalMap,然后 ThreadLocalMap 把 ThreadLocal 的引用作为了 key 存成了一个 Entry?
确实是这样,听起来还挺绕的,哈哈哈哈
举个例子吧:
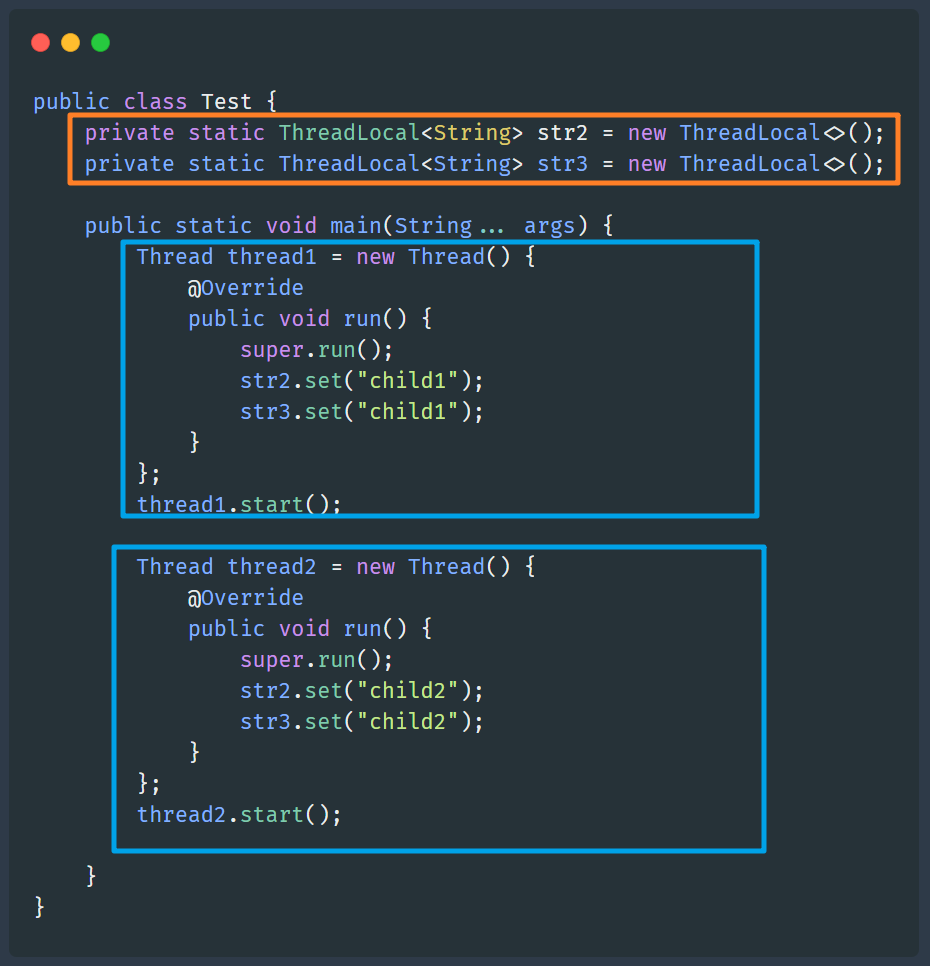
两个 ThreadLocal 变量,两个线程都分别给它们赋了不同的值,也即,这两个线程的 ThreadLocalMap 中,各有两个 Entry 节点,如下图:
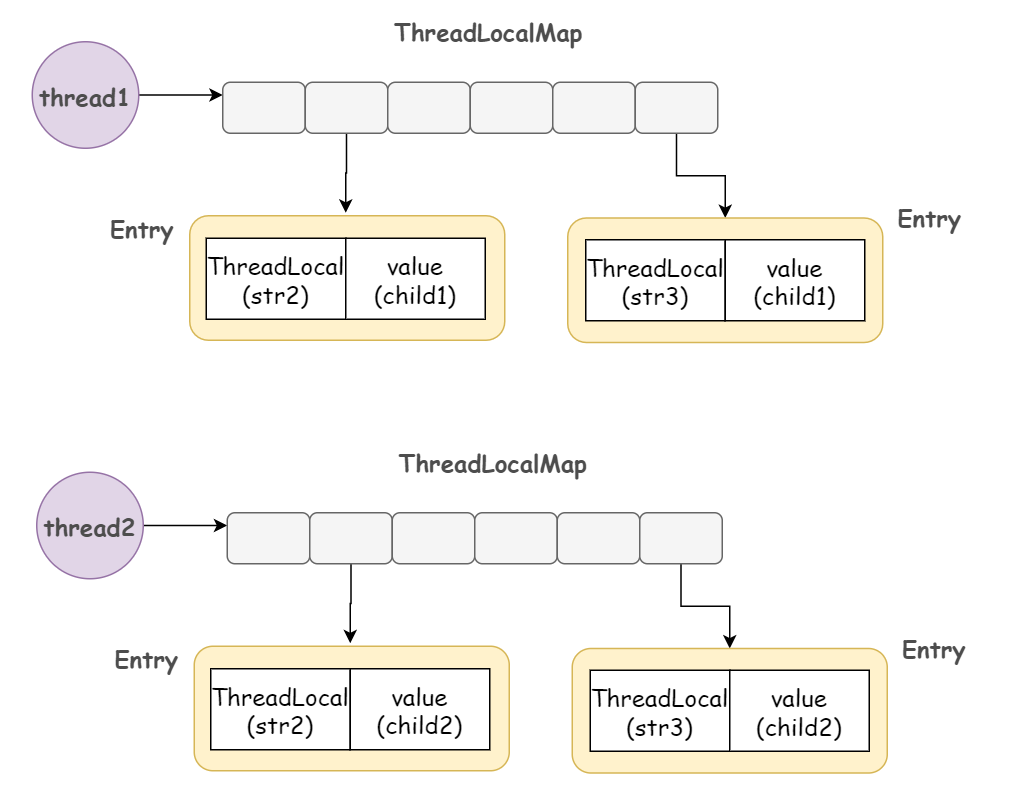
可以看出来,一个 ThreadLocal 只能保存一个 "key : value" 键值对,并且各个线程的数据互不干扰。
ThreadLocal 经典之内存泄漏
要说 ThreadLocal 中最经典的知识点,当属内存泄漏了。
为什么呢,我们来看一下 Entry 节点的具体实现就知道了:
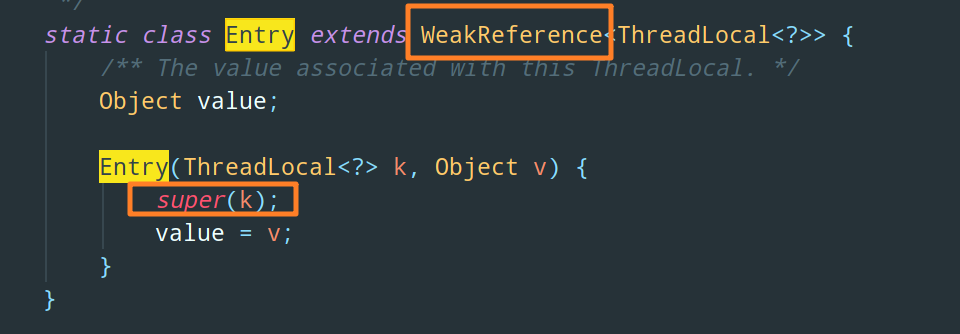
在 Entry 节点中,key 被保存到了 WeakReference(弱引用)对象中。
简单解释一下强引用和弱引用,这属于 JVM 的知识点,这里不做特别详细的解释哈:
- 强引用:Java 中最常见的就是强引用,把一个对象赋给一个引用变量,这个引用变量就是一个强引用。当一个对象被强引用变量引用时,它是不可能被垃圾回收机制回收的,即使该对象以后永远都不会被用到。因此强引用是造成 Java 内存泄漏的主要原因之一
- 弱引用:只要垃圾回收机制一运行,不管 JVM 的内存空间是否足够,总会回收该对象占用的内存
为什么 key 要作为弱引用很好理解:
首先,ThreadLocalMap 是存在于 Thread 内部的,将 ThreadLocal 作为 key 扔到线程本身的的 Map 里,对吧。
在以往我们使用完对象以后等着 GC 来进行清理就行了。但如果 key(ThreadLocal) 是强引用,那就是说,这个 Thread 死亡之前,ThreadLocal 一直被该线程引用着,所以在这个线程销毁之前都是可达的,也即无法 GC,ThreadLocal 无法被回收。如果 ThreadLocal 太多的话,就会出现内存泄漏的问题。
所以,key 需要被保存为弱引用。
虽然 key 被设计成弱应用了,可以从某种程度上避免内存泄漏,但是呢,value 仍然是强引用!
如果我们使用完 ThreadLocal 后,不对 key 为 null 的节点进行移除,还是会发生内存泄漏的
ThreadLocal 为我们提供了 remove 方法用来移除空节点,所以如果我们使用了 ThreadLocal 的 set 方法,最后一定要记得显示地调用 remove 方法:
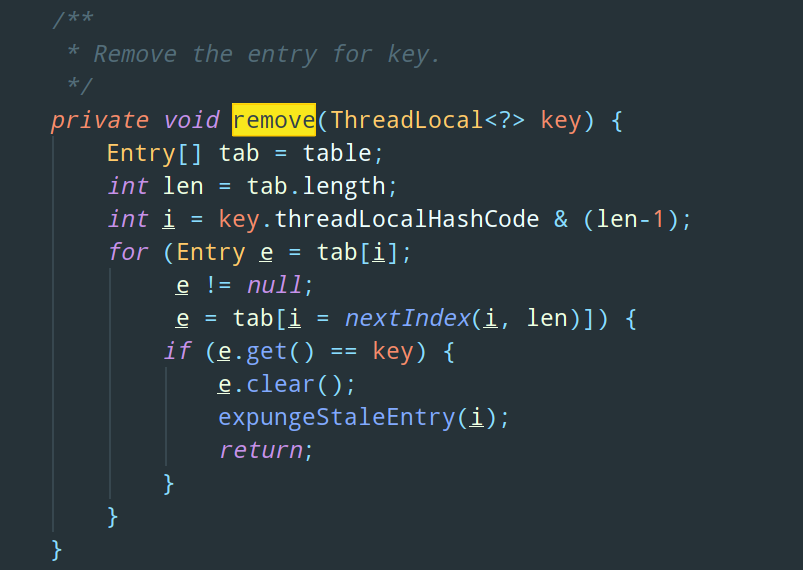
看到这里,不知道大伙儿有没有和我一样的疑问,那就是:value 为啥不和 key 一样设计成弱引用???
不设置为弱引用,是因为不清楚这个 value 除了 ThreadLocalMap 的引用还是否还存在其他引用。
如果 value 是弱引用且不存在其他引用的话,当 GC 的时候就会直接将这个 value 回收掉了,而此时我们的 ThreadLocal 还处于使用期间呢,就会报出 value 为 null 的错误。
所以仍然把 value 设置为强引用。
1 Comment