通俗易懂之 AQS
为什么有了 synchronized 还需要 Lock?
之前我们说过,Java 有两套锁实现,一个就是原生的 synchronized 关键字,另一个就是实现了 Lock 接口的类比如 ReentrantLock。那么既然有了前者,为什么还大费力气整出一套新的实现呢?
我们先来看看这两套锁的使用方式:
// synchroinzed
class Test {
// 普通同步方法
public synchronized void test1() {
// do something ....
}
}
// Lock
class Test {
public void test1() {
ReentrantLock reentrantLock = new ReentrantLock();
// 加锁
reentrantLock.lock();
// do something ....
// 解锁
reentrantLock.unlock();
}
}对于 synchronized 来说,它把锁的获取和释放操作完全隐藏起来了,进入同步块的时候自动尝试去获取锁,退出同步块时候的自动释放锁,也就是说获取锁操作一定是在释放锁操作之前的。
显然,这种方式简化了锁的管理,但也固化了锁的管理。比如对于下面这样一个场景,synchronized 就无能为力了:
- 先获得锁 A,然后再获取锁 B,当锁 B 获得后,释放锁 A 并同时获取锁 C,当锁 C 获得后,再释放 B 同时获取锁D,以此类推。
这种情况下,就比较适合使用 Lock 那样手动获取和释放锁的方式了。
Lock 接口概览
Lock 其实也没啥神秘的,整个接口就 6 个方法:
public interface Lock {
void lock();
void lockInterruptibly() throws InterruptedException;
boolean tryLock();
boolean tryLock(long time, TimeUnit unit) throws InterruptedException;
void unlock();
Condition newCondition();
}lock():尝试获取锁,获取锁成功后返回lockInterruptibly():可中断的获取锁。所谓可中断的意思就是,在锁的获取过程中可以中断当前线程tryLock():尝试非阻塞的获取锁。不同于 lock() 方法在锁获取成功后再返回,该方法被调用后就会立即返回。如果最终获取锁成功返回 true,否则返回 falsetryLock(long time, TimeUnit unit):超时的获取锁。如果在指定时间内未获取到锁,则返回 falseunlock():释放锁newCondition():当前线程只有获得了锁,才能调用Condition接口的 await 方法。Condition接口本文就先不做详细赘述了
Lock 接口底层:AQS 概述
事实上,Lock 接口的实现基本都是通过聚合了一个队列同步器(AbstractQueuedSynchronizer,AQS)的子类来完成线程访问控制的。比如 ReentrantLock:
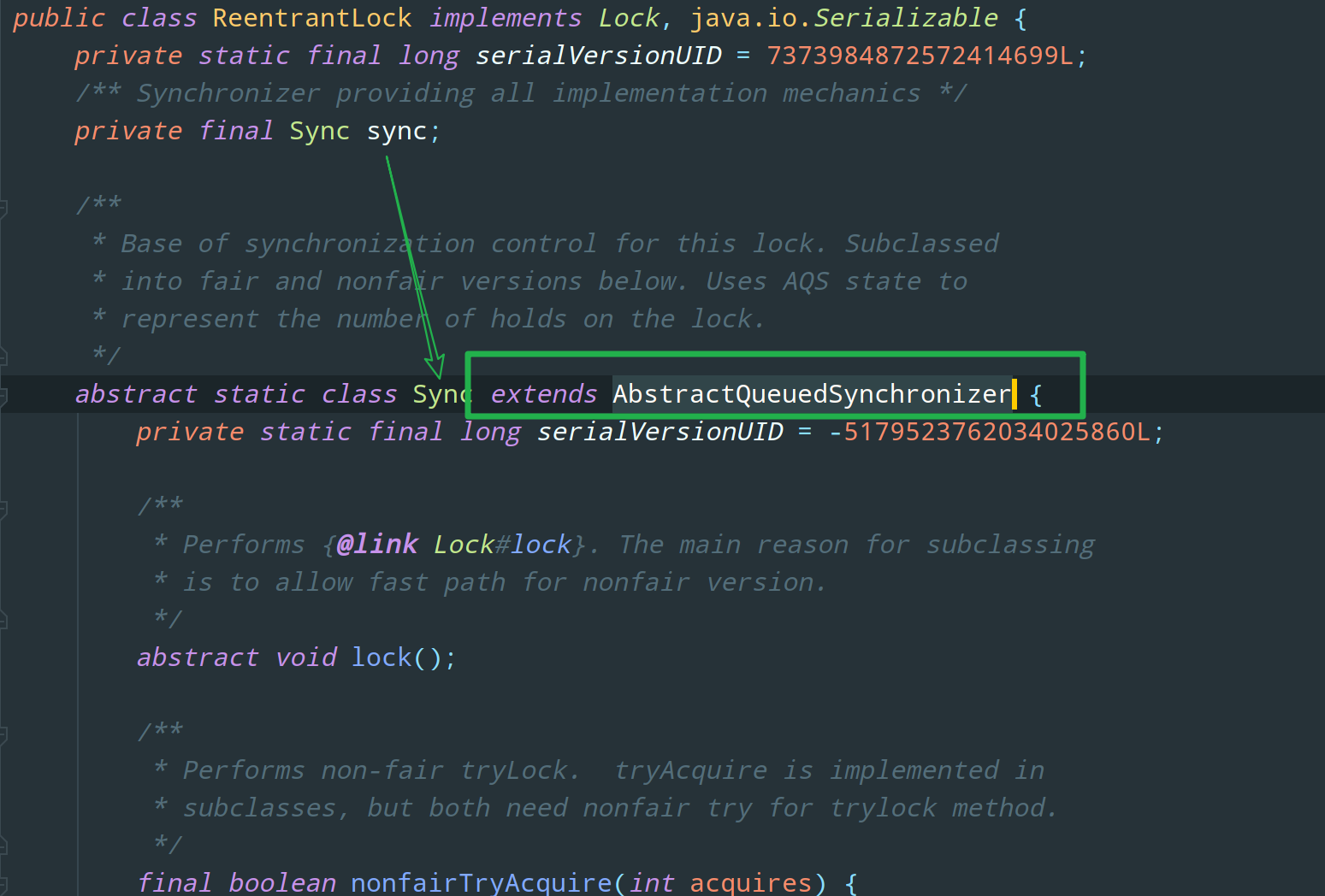
AQS 队列同步器是一个抽象类,也称为同步器,就是本文的重点啦:
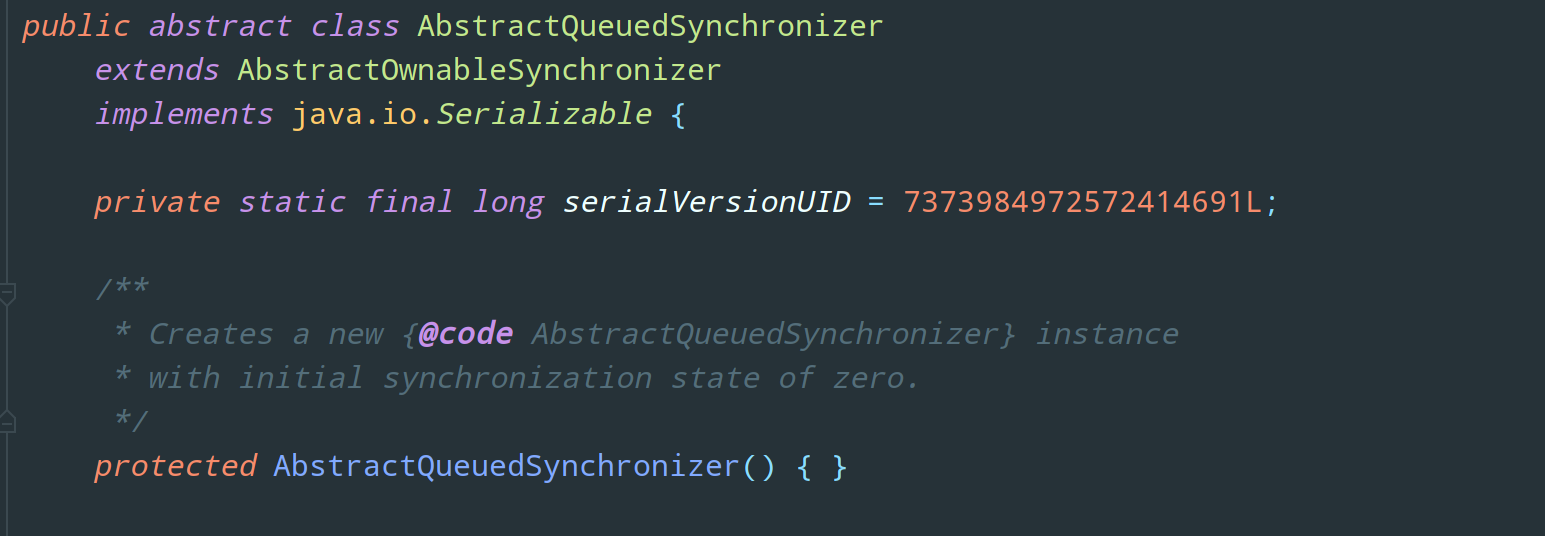
⭐ 理解 模板方法设计模式 是理解 AQS 的关键,所谓模板方法可以简单理解为不可被子类重写的方法,模板方法相当于一个骨架,也就是说整体骨架不能被改变,里面具体实现细节可以开放给子类进行重写。
具体来说,AQS 将一些方法开放给子类进行重写,进而 AQS 提供的模板方法就会调用这些被子类重写的方法。举个例子:
AQS 中的模板方法 acquire(),可以看到被 final 关键字标识了,不可被继承重写:
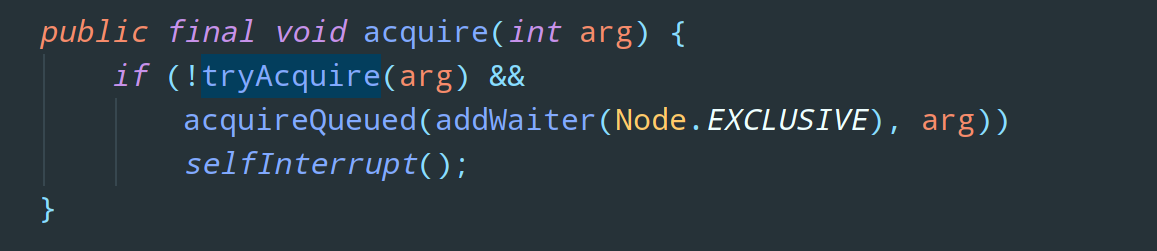
但是这个模板方法中调用的 tryAcquire 就是开放给子类进行重写的,AQS 中默认是这样的:

比如 ReentrantLock 中的内部类 NonfairSync 继承了 AQS,它重写了 tryAcquire 方法:

如果面试的时候面试官这样问你:谈谈你对 AQS 的理解。兄弟们,不要犹豫,先直接讲一下模板方法设计模式然后无脑背出下面这段话再说:
AQS 是一个抽象类,是用来构建锁或者其他同步组件的基础框架,它使用了一个
volaitle修饰的 int 成员变量state表示同步状态,通过内置的 FIFO 双向队列(源码注释上写的 CLH(Craig,Landin,and Hagersten) 队列(三个人名的简称),其实就是一个先进先出的双向队列)来完成线程们获取资源的时候的排队工作。具体来说,如果某个线程请求锁(共享资源)失败,则该线程就会被加入到 CLH 队列的末端。当持有锁的线程释放锁之后,会唤醒其后继节点,这个后继节点就可以开始尝试获取锁。
画个图直观看一下:

下面来详细解释下:
成员变量 state
先来看 state 相关的三个方法:
private volatile int state;
protected final int getState() {
return state;
}
protected final void setState(int newState) {
state = newState;
}
protected final boolean compareAndSetState(int expect, int update) {
return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
}很简单,没啥好说的。。。
state 是用来表示同步状态的,什么意思呢。比如说当前有一个线程,调用 ReentrantLock 的 lock() 方法进行加锁,这个加锁的过程,其实就是通过 CAS 操作将 state 变量的值增加 1:
final void lock() {
if (compareAndSetState(0, 1))
// CAS 成功,即没有线程持有锁,此时当前线程可直接获取锁
setExclusiveOwnerThread(Thread.currentThread());
else
// CAS 失败,当前线程入队
acquire(1);
}
public final void acquire(int arg) {
if (!tryAcquire(arg) && // 此方法会尝试去获取锁
// 将当前线程加入 CLH 队列中
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}对应的,释放锁操作就是将 state 的变量减 1:

CLH 队列
如果没竞争到锁,这个线程就会进入 CLH 等待队列,跟我们平常做算法题一样,这个队列中已经内置了一个不带任何信息的头节点 head。
如上段代码所示,addWaiter 方法会是使用 CAS 操作创建一个 Node 节点添加到队列的末尾:
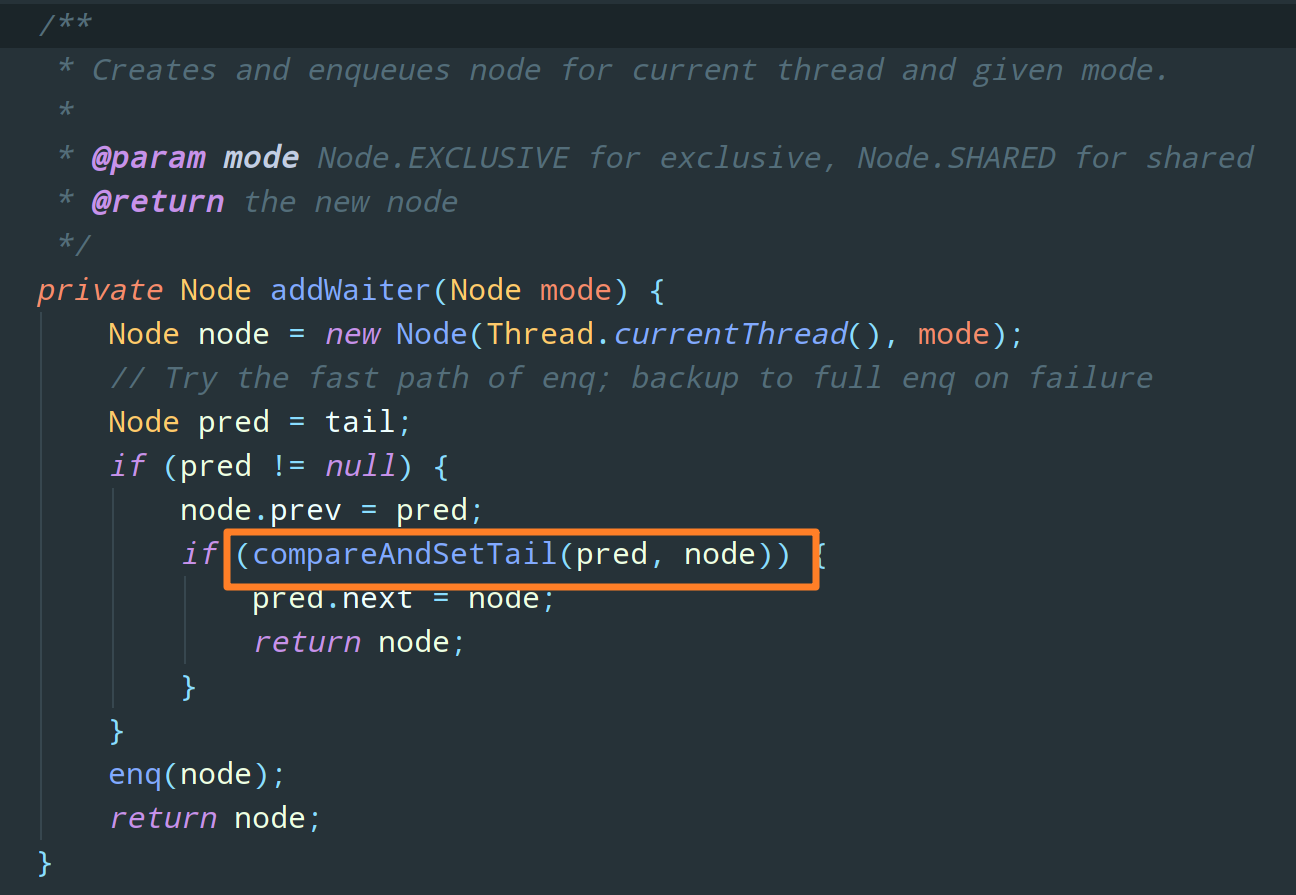
看下图:
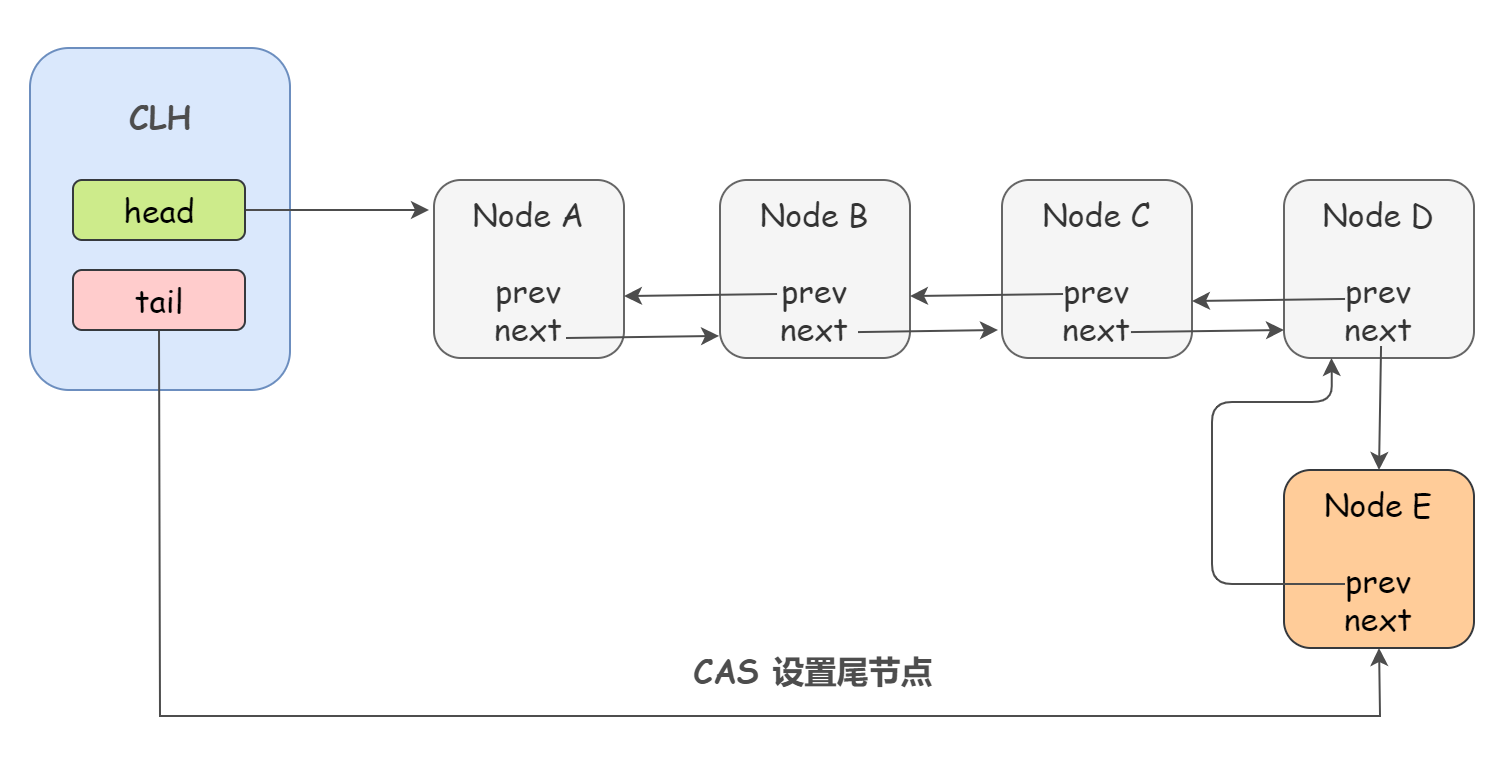
第一个节点就是成功获取同步资源的节点(为了和头节点 head 区分开,这里我们将他称为 “首节点” 吧),首节点的线程 A 在释放同步资源时,将会唤醒器其后继节点 B,而后继节点 B 被唤醒后,就会重新尝试加锁,同样还是 CAS 操作给 state 变量加 1,如果成功,就将自己设置为首节点。如下图:
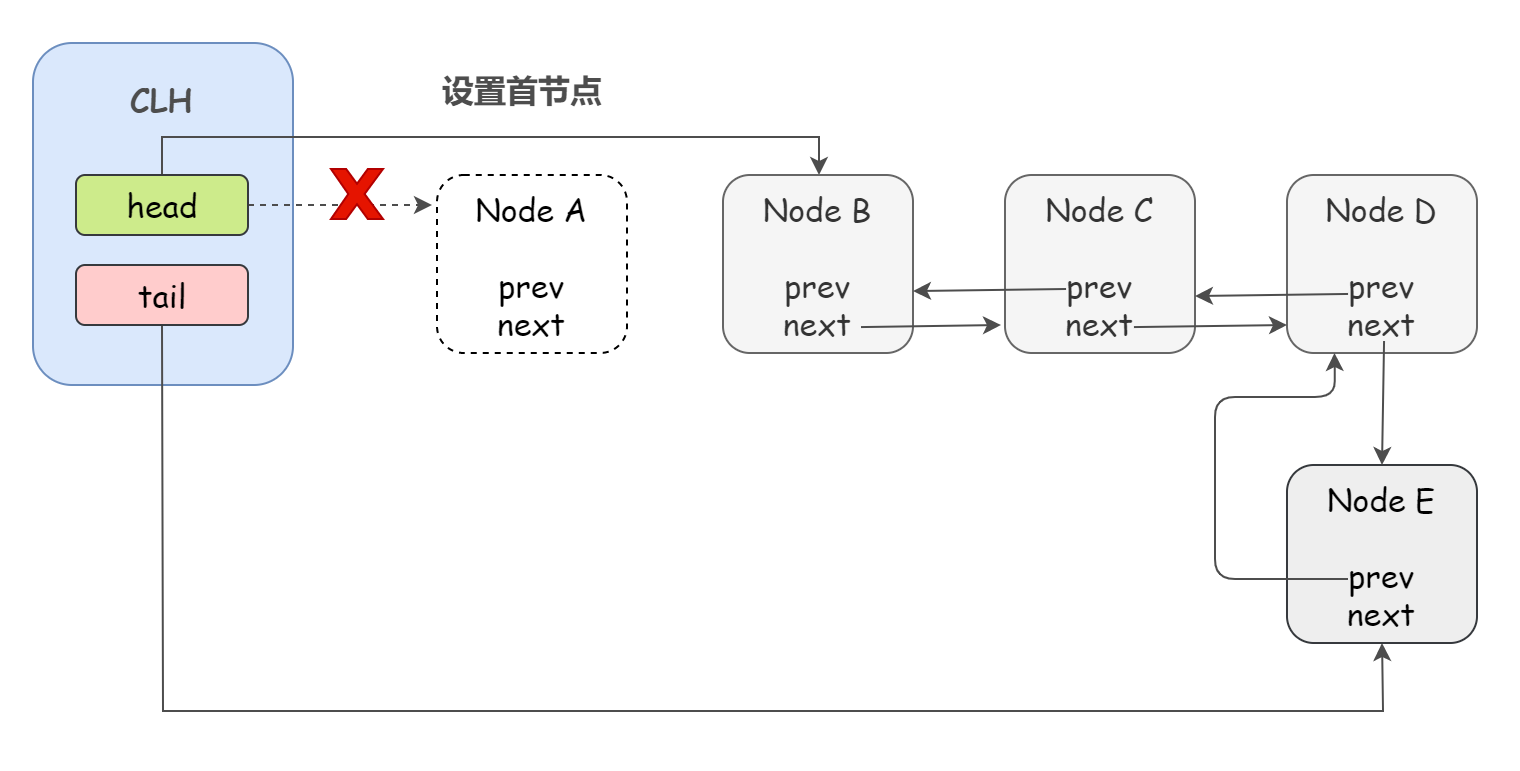
看了上图,可能有同学会疑惑,为什么设置首节点就不需要 CAS 操作呢?很简单,既然能够走到设置首节点这一步,那一定是已经获取到了同步资源了,显然只有一个线程能够走到一步,所以也没必要使用 CAS 了。
还需要特别注意的是:
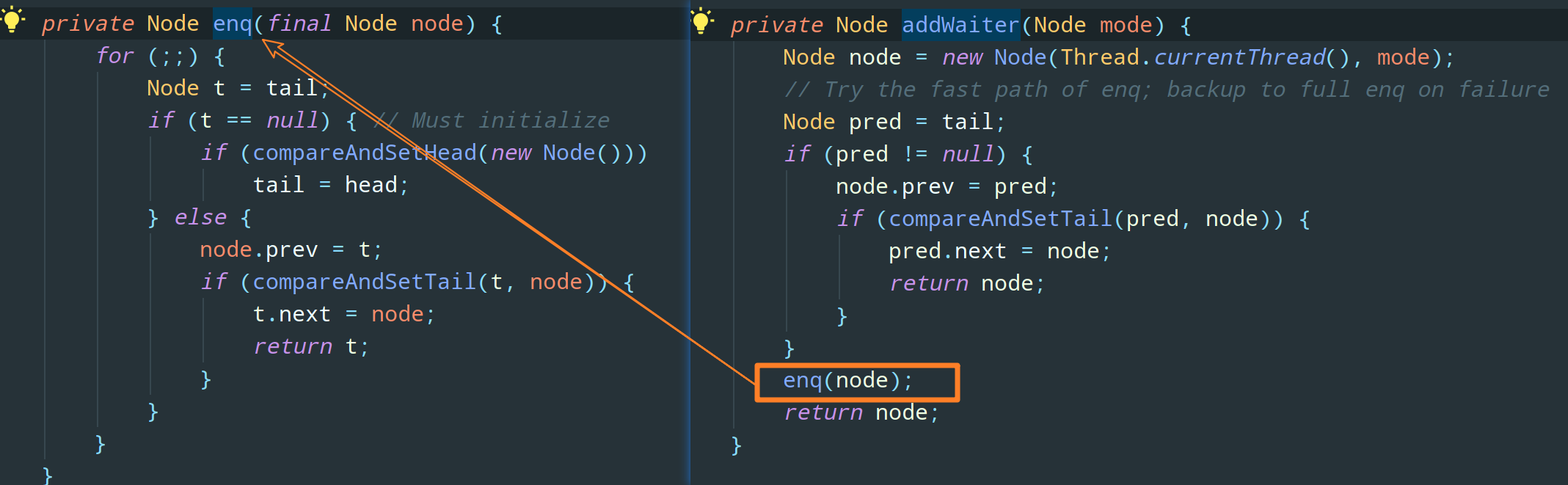
在 enq(final Node node) 方法中,AQS 通过 “死循环” 的方式来保证节点的正确添加,在 “死循环” 中只有通过 CAS 将节点设置成为尾节点之后,当前线程才能从该方法返回,否则,当前线程不断地尝试设置。
可以看出来,enq(final Nodenode) 这个方法通过 CAS 将并发添加节点的请求变得 “串行化” 了。
另外,每一个 Node 中除了持有当前线程的引用,同时还有一个成员变量 waitStatus,表示当前线程的等待状态,这个状态又分别是啥呢?我们来看看 Node 的定义:
static final class Node {
static final int CANCELLED = 1;
static final int SIGNAL = -1;
static final int CONDITION = -2;
static final int PROPAGATE = -3;
volatile int waitStatus;
volatile Node prev; // 前驱节点
volatile Node next; // 后继节点
volatile Thread thread; // 当前线程的引用
Node nextWaiter;
}
private transient volatile Node head; // 头节点
private transient volatile Node tail; // 最后一个节点可以看到,一共定义了 4 个状态,这里我们需要重点关注下面这两个:
CANCELLED:表示取消状态,就是说我不要这个锁了,请你把我从队列中移出去SINGAL:表示当前节点的后继节点正在挂起等待,注意是后继节点,不是当前节点
总结
AQS 其实还有两种资源模式,独占 Exclusive(排它锁模式)和共享 Share(共享锁模式)。在 AQS 的所有子类中,只会使用这两种模式的其中之一,要么实现并使用了独占锁的 API,要么使用了共享锁的 API,不会一个子类同时使用两套不同的模式。关于这一点会在下篇文章给出详细解释。
另外,这篇文章还是屏蔽了不少细节的,不过如果面试的时候能够流畅的说出来上述这些其实也就没啥问题了。
最后,我是飞天小牛肉,长风破浪会有时,小伙伴们下期文章再见~
AQS 的两套模式
AQS 的两套模式
前文说过,AQS 采用模板方法设计模式,学习 AQS 其实就是学习它提供的模板方法:
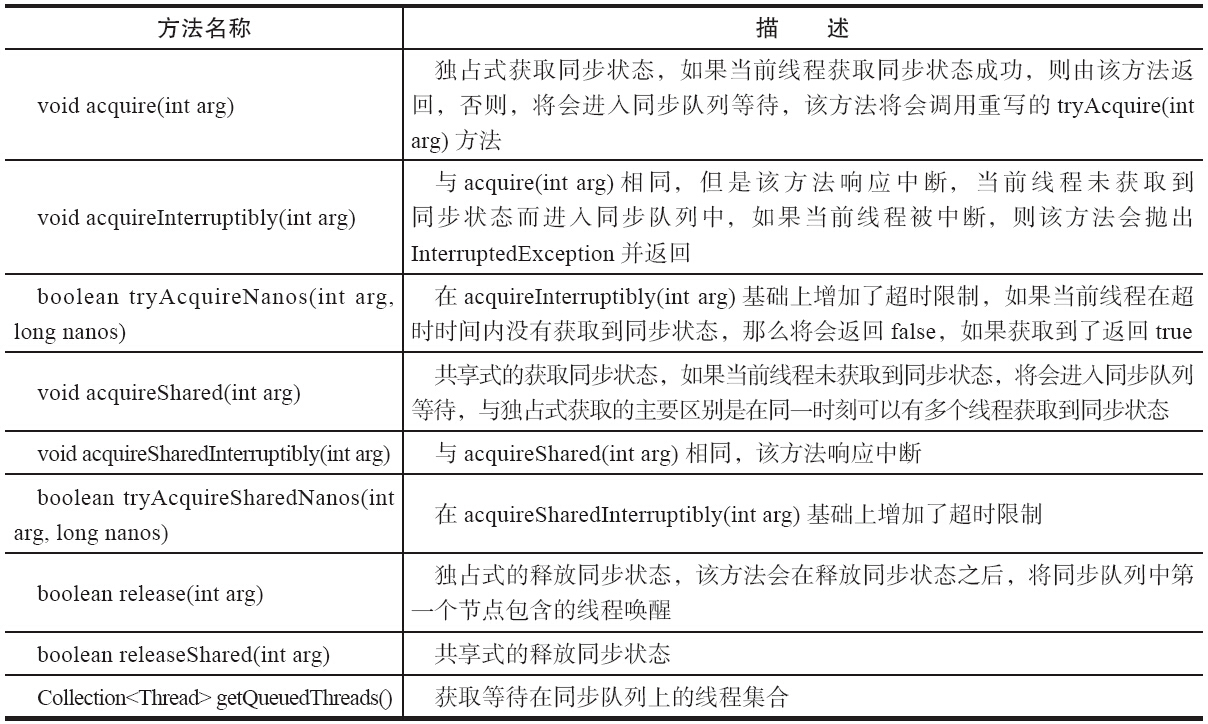
基本上可以分为 3 类:
- 独占式获取与释放同步状态
- 共享式获取与释放同步状态
- 查询同步队列中的等待线程情况
这里提到的:独占 Exclusive(排它锁模式)和共享 Share(共享锁模式)就是 AQS 提供的两种模式。事实上,在 AQS 的所有子类中,只会使用这两种模式的其中之一,要么实现并使用了独占锁的 API,要么使用了共享锁的 API,不会一个子类同时使用两套不同的模式。
那么具体是如何体现出来的呢?我们已经知道,AQS 是通过一个双向队列来完成对线程获取资源时候的排队工作的,独占锁与共享锁在创建自己的节点时(addWaiter 方法)会通过 nextWaiter 变量来表明身份,看下面源码,注释已经写的非常清楚了:
static final class Node {
/** Marker to indicate a node is waiting in shared mode */
static final Node SHARED = new Node();
/** Marker to indicate a node is waiting in exclusive mode */
static final Node EXCLUSIVE = null;
/**
* Link to next node waiting on condition, or the special
* value SHARED. Because condition queues are accessed only
* when holding in exclusive mode, we just need a simple
* linked queue to hold nodes while they are waiting on
* conditions. They are then transferred to the queue to
* re-acquire. And because conditions can only be exclusive,
* we save a field by using special value to indicate shared
* mode.
*/
Node nextWaiter;需要注意的是,从 nextWaiter 的注释上我们可以看到:
condition queues are accessed only when holding in exclusive mode
就是说 Condition 这个类只有在独占模式下才能被使用。当然这个是后话了,这里大家有个印象就行。
下面我们来详细分析下这两种模式下的模板方法。
独占模式
顾名思义,独占锁就是在同一时刻只能有一个线程获取到锁,而其他获取锁的线程只能在队列中等待,只有当获取锁的线程释放了锁,后继的线程才能够去尝试获取锁。
独占锁的获取 acquire
public final void acquire(int arg) {
if (!tryAcquire(arg) && // 此方法会尝试去获取锁
// 将当前线程加入 CLH 队列中
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
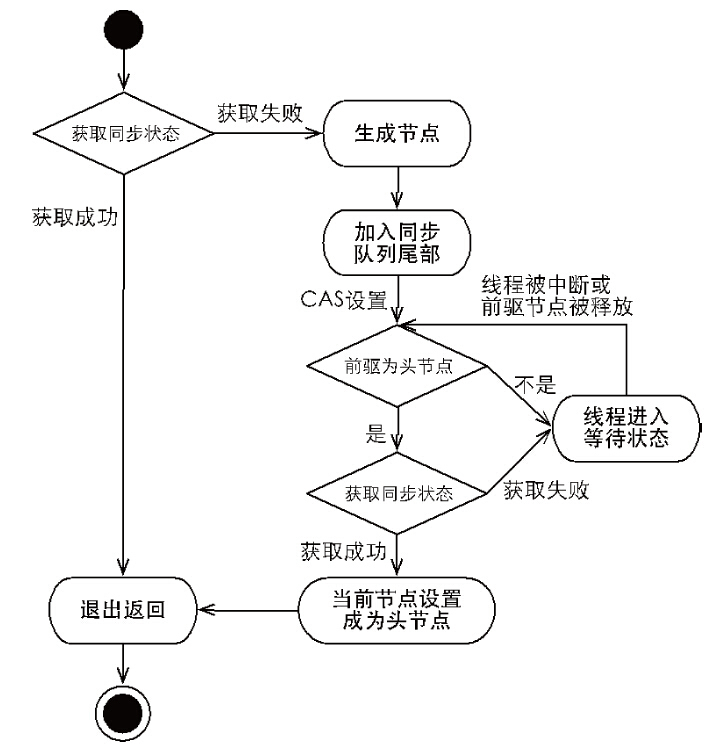
}方法很好理解,首先 tryAcquire 会去尝试获取锁,如果获取锁成功,则方法结束(selfInterrupt);如果获取锁失败,则会将通过 addWaiter 方法构造一个 EXCLUSIVE 节点,将该节点加入到 CLH 队列的尾端,然后调用 acquireQueued 方法从队列中排队获取锁。
这里多提一嘴,tryAcquire 这个方法是 AQS 开放给子类进行重写的,所以子类可以自定义这个方法来实现公平竞争或者非公平竞争(是否允许插队)。
具体怎么把一个节点插入到 CLH 队列,上篇文章已经说过了,这里我们就来看下从队列中排队获取锁的逻辑:
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
// 当前节点的前驱节点
final Node p = node.predecessor();
// 如果当前节点的前驱节点是头节点并且成功获取锁,则当前线程获取到独占锁
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return interrupted;
}
// 获取独占锁失败,则当前线程进入等待态
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}上述代码有两个重要的地方:
1)if (p == head && tryAcquire(arg)) 如果当前节点的前驱节点是头节点并且成功获取锁,则当前线程获取到独占锁。所谓当前节点的前驱节点是头节点(不存储任何数据的节点),意思就是当前节点是第一个元素节点(在上篇文章中为了和头节点做区分,我们把它称作首节点)。也就是说,当某个节点是头节点的后继节点的时候,就表示之前持有独占锁的线程已经释放了,于是这个时候当前线程就有资格去获取独占锁了。
另外,这样设计也能够保证 CLH 队列的 FIFO 原则。
2)for(;;),这是啥?没错,死循环,自旋。也就是说我们新加入到 CLH 队列的这个节点会以 “死循环” 的方式获取锁。如果获取锁失败,则阻塞该节点中的线程。只有当这个节点的前驱节点出队了,或者该阻塞线程被中断了,这个被阻塞线程才会被唤醒。
最后,结合上面所讲的,我们再来看一下书中给出的获取独占锁的流程图,应该比较好理解了:
独占锁的释放 release
这段代码比较简单:
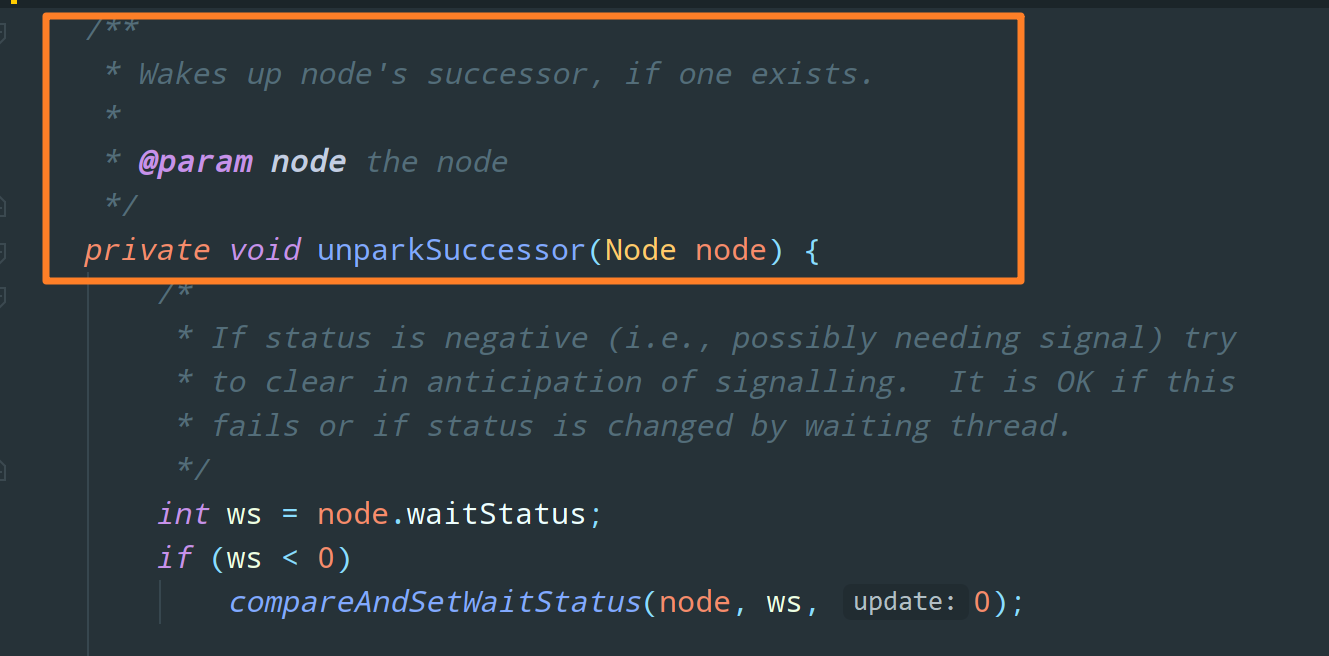
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}首先 tryRelease 尝试释放锁,如果释放成功则执行 if 块中的代码,unparkSuccessor 就是用来通过 CAS 操作 wake up node's successor 唤醒当前节点的后继节点的:
而 compareAndSetWaitStatus 其实就是个壳儿,调用的是 UnSafe 类的 compareAndSwapInt 方法:

小结
小结下独占锁的获取和释放流程:
- 在获取同步状态(锁)时,AQS 维护一个 CLH 双向队列,获取锁失败的线程都会通过 CAS 操作被加入到队列尾端,并且在队列中无限自旋等待获取锁;
- 停止自旋(或者说被移除 CLH 队列)的条件是其前驱节点为头节点并且成功获取了独占锁;
- 当前节点(线程)成功释放掉独占锁后,AQS 就会紧接着唤醒该节点的后继节点,这样,这个后继节点又会开始去尝试获取锁。循此往复。
共享模式
共享式获取与独占式获取最主要的区别在于同一时刻能否有多个线程同时获取到同步状态(锁)。
共享锁的获取 acquireShared
public final void acquireShared(int arg) {
if (tryAcquireShared(arg) < 0)
doAcquireShared(arg);
}和独占锁的获取差不多,该方法中会首先调用 tryAcquireShared 方法尝试去获取锁,如果返回值为大于等于 0 的就说明成功获取锁,方法结束;否则,获取锁失败,会执行 doAcquireShared 方法:
private void doAcquireShared(int arg) {
final Node node = addWaiter(Node.SHARED);
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head) {
int r = tryAcquireShared(arg);
if (r >= 0) {
setHeadAndPropagate(node, r);
p.next = null; // help GC
if (interrupted)
selfInterrupt();
failed = false;
return;
}
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}逻辑和独占锁的 tryAcquire 完全一样,无限自旋去获取锁,在自旋过程中,如果当前节点的前驱节点为头节点,则当前节点(线程)就会调用 tryAcquireShared 去尝试获取锁,如果返回值大于等于 0,表示获取锁成功,就退出自旋。
共享锁的释放 releaseShared
public final boolean releaseShared(int arg) {
if (tryReleaseShared(arg)) {
doReleaseShared();
return true;
}
return false;
}逻辑也是和独占锁的释放基本差不多,当前节点释放掉持有的共享锁之后,将会唤醒其后继节点。
doReleaseShared 如下:
private void doReleaseShared() {
for (;;) {
Node h = head;
if (h != null && h != tail) {
int ws = h.waitStatus;
if (ws == Node.SIGNAL) {
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))
continue; // loop to recheck cases
unparkSuccessor(h);
}
else if (ws == 0 &&
!compareAndSetWaitStatus(h, 0, Node.PROPAGATE))
continue; // loop on failed CAS
}
if (h == head) // loop if head changed
break;
}
}可以看出这里稍微有点不同的是,独占锁的释放直接就调用了 unparkSuccessor 方法唤醒后继节点,而共享锁这里,在 unparkSuccessor 之前还加了一个循环和 CAS 的操作来确保共享锁成功释放。
这个原因也非常简单,因为共享锁可能会被多个线程持有,那么在释放的时候就可能会有多个线程同时释放锁这种情况,所以需要用循环和 CAS 来保证这多个线程都能成功释放掉锁。
小结
小结下共享锁的获取和释放流程:
- 在获取同步状态(锁)时,AQS 维护一个 CLH 双向队列,获取锁失败的线程都会通过 CAS 操作被加入到队列尾端,并且在队列中无限自旋等待获取锁;
- 停止自旋(或者说被移除 CLH 队列)的条件是其前驱节点为头节点并且成功获取了共享锁;
- 通过循环 + CAS 操作确保当前节点(线程)成功释放掉共享锁后,AQS 就会紧接着唤醒该节点的后继节点,这样,这个后继节点又会开始去尝试获取锁。循此往复。
总结
关于锁超时获取和超时释放的模板方法这篇文章就没有做介绍了,感兴趣的各位可以自行去看源码,道理都差不多。大伙儿看完这篇文章,对 AQS 应该有了一个比较清晰的认识了吧。
其实 ReentrantLock 就这么简单
ReentrantLock 常被人们称为重入锁,顾名思义,就是一个线程可以对同一个资源重复加锁。需要注意的,ReentrantLock 并不是重入锁的唯一代名词,synchronized 也是一种可重入锁。
反映到代码层面上来说,ReentrantLock 不像 synchronizd 那种隐式的可重入,但是在调用 lock() 方法时,已经获取到锁的线程,能够再次调用 lock() 方法获取锁而不被阻塞。
另外,前文说过,tryAcquire 这个方法是 AQS 开放给子类进行重写的,所以子类可以自定义这个方法来实现公平竞争或者非公平竞争(是否允许插队),也即公平锁和非公平锁。所谓公平锁,也就是等待时间最长的线程最先获取锁,或者说锁是被顺序获取的。ReentrantLock 提供了一个构造函数,能够控制锁是否是公平的。
所以呢,关于 ReentrantLock,理解了上篇文章的 AQS,本文的重点就只有两个:
- 重入锁的实现原理
- 公平锁和非公平锁的实现原理
理清了 ReentrantLock 中每个类的逻辑关系,其实 ReentrantLock 真的很好理解。
重入锁原理
想要实现一个线程可以多次重复获取某个锁而不会被阻塞,需要解决两个问题:
- 获取锁:锁需要去识别获取锁的线程和当前占据锁的线程是否是同一个,如果是,则重复成功获取
- 释放锁:如果某个线程重复 n 次获取了锁,则只有在第 n 次释放该锁后,其他线程才能够获取到该锁。这个实现其实很简单,用一个计数器(也就是代码中的同步状态 state)存储下锁被占用的次数,每释放一次就减 1 就行了
先来看获取锁的方法,对于公平锁和非公平锁来说,它们获取锁的方式是不同的,这里以获取非公平锁为例:
事实上,ReentrantLock 的
tryLock方法调用的也就是非公平锁的方法,也就是说,即使该锁是公平锁,使用 tryLock() 方法的话也会使用非公平的方式去获取锁public boolean tryLock() { return sync.nonfairTryAcquire(1); }
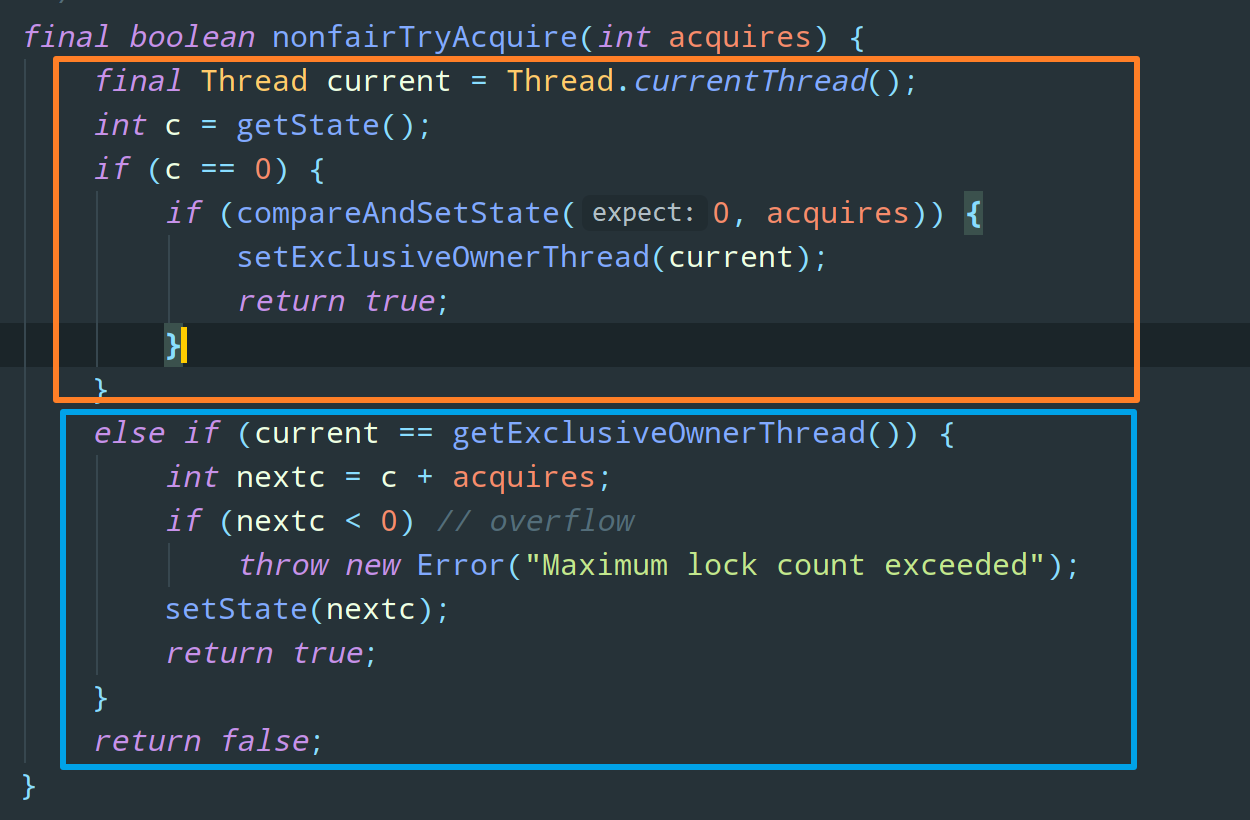
上图橙色框中的代码比较简单,如果该锁没有被任何线程占有,则 CAS 操作去获取这个锁就行了,CAS 成功则获取锁成功;蓝色框中的代码,表示如果该锁已经被占有了,那么检查下占有该锁的线程是不是当前来获取锁的线程,如果是,计数器(同步状态 state)+ 1,返回 true 表示获取锁成功。
而对于锁的释放 tryRelease 方法,不同于获取锁,无论是公平锁还是非公平锁,它们的释放方式都是一样的:
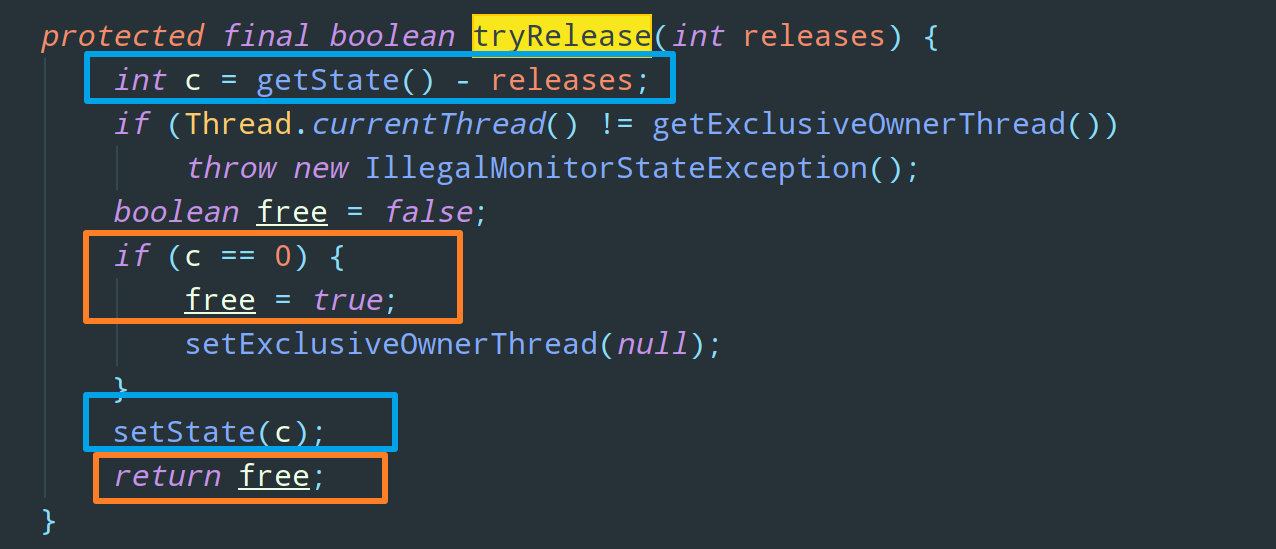
tryRelease 的逻辑很简单,核心就是我在图中标注出来的两行代码,可以看到,该方法将同步状态 state 是否为 0 作为最终释放的条件,当同步状态为 0 时,将占有线程设置为 null,并返回 true,表示释放成功。这就呼应了我们在文首提到的 Reentrant 是一种重入锁,就是说如果该锁被同一个线程重复获取了 n 次,那么前 n-1 次 tryRelease 方法返回的都是 false,只有同步状态完全释放了即 state = 0 的时候,tryRelease 才返回 true 表示该锁不再被占用。
公平锁和非公平锁原理
先来看 ReentrantLock 的类关系图,下图中红线表示内部类,蓝线表示继承,绿色虚线表示实现接口:

可以看到,Snyc 是 ReentrantLock 的内部类并且继承自 AQS,同时,Sync 还拥有两个子类:NonfairSync、FairSync。从名字也就可以看出来,这两个子类分别用来实现非公平锁和公平锁的相关操作。
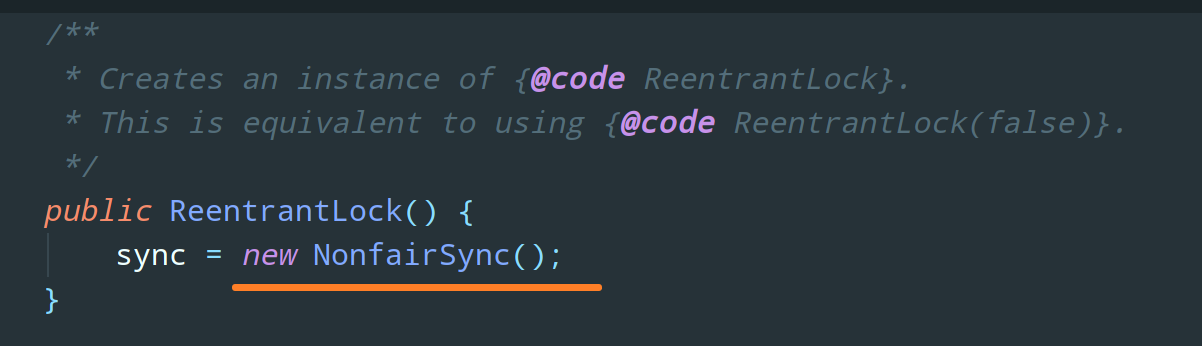
ReentrantLock 的无参构造使用的就是非公平锁:
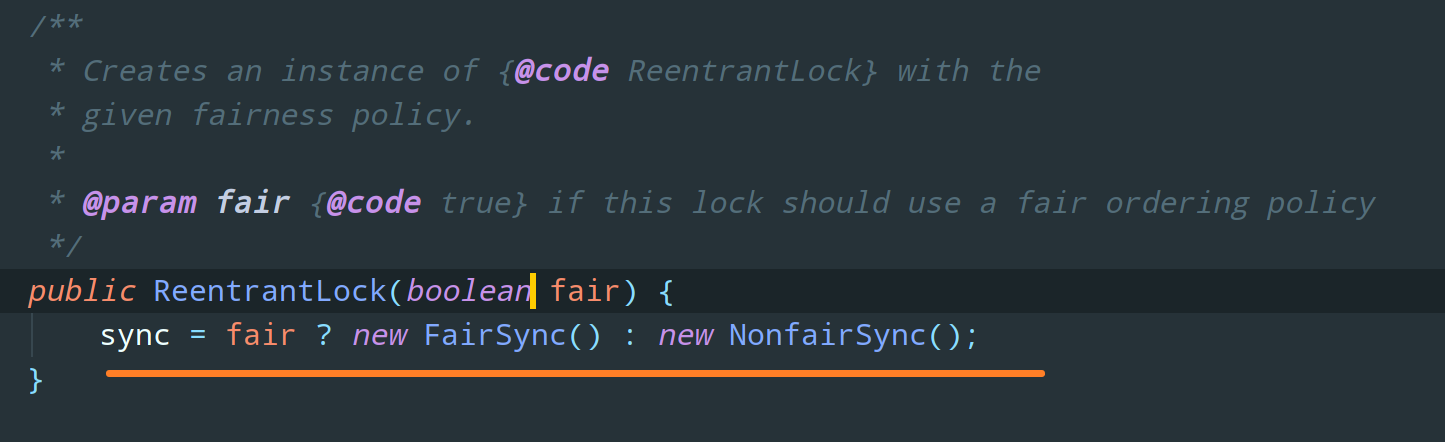
当然也可以传入一个 boolean 值,true 时为公平锁,false 时为非公平锁:
我们来看下这两个子类重写了哪些方法,如下图所示:
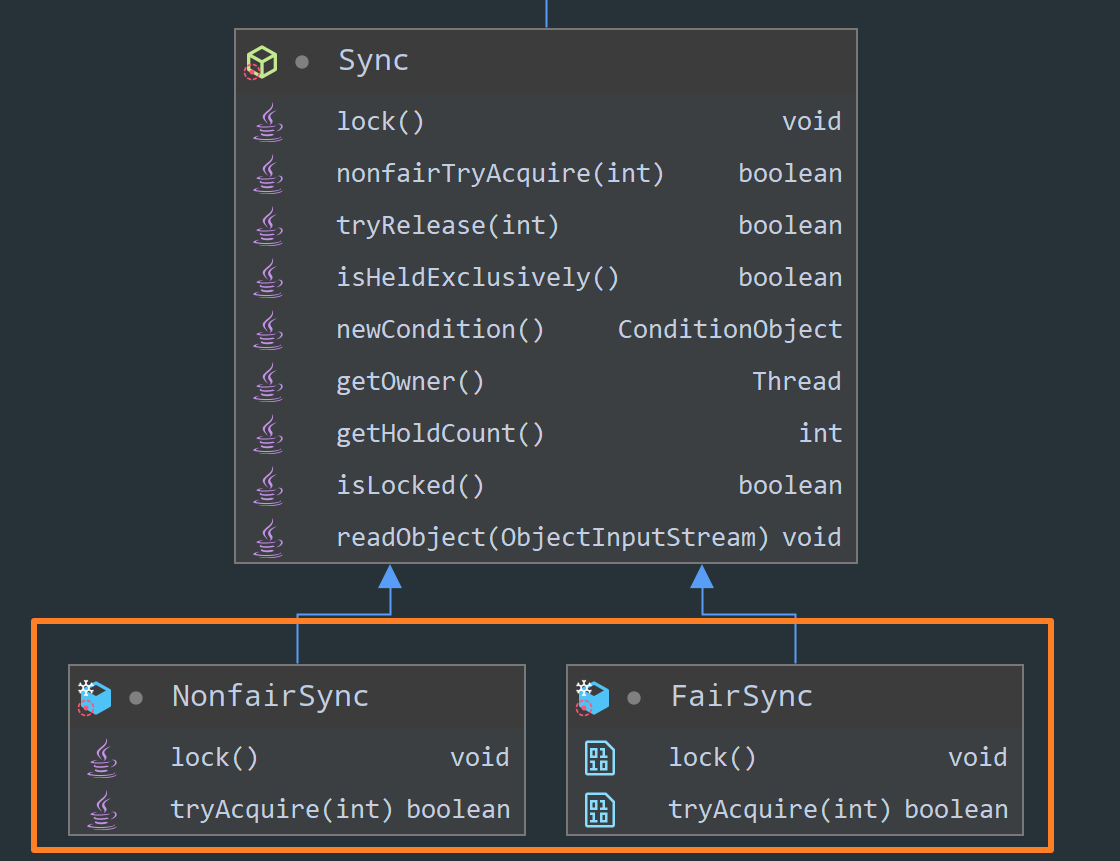
可以看到,这两个子类只重写了加锁方法,也证实了我们上文说的:无论是公平锁还是非公平锁,它们的释放方式都是一样的。现在,我们来捋一下整体的加锁流程,从调用 ReentranLock 的 lock 方法加锁开始:
ReentrantLock.lock` -> `Sync.lock` -> `NonfairSync/FairSync.lock` -> `AQS.acquire` -> `NonfairSync/FairSync.tryAcquire()是不是非常清楚了!
其中,非公平锁的 tryAcquire 调用的就是 nonfairTryAcquire 方法,这个在上一节我们已经解释过了,把 nonfairTryAcquire 方法提到 Sync 中去的原因,就是因为 ReentrantLock 想要它的 tryLock 这个方法无论什么情况都以非公平的方式去获取锁:
protected final boolean tryAcquire(int acquires) {
return nonfairTryAcquire(acquires);
}再来看公平锁的 tryAcquire 方法:
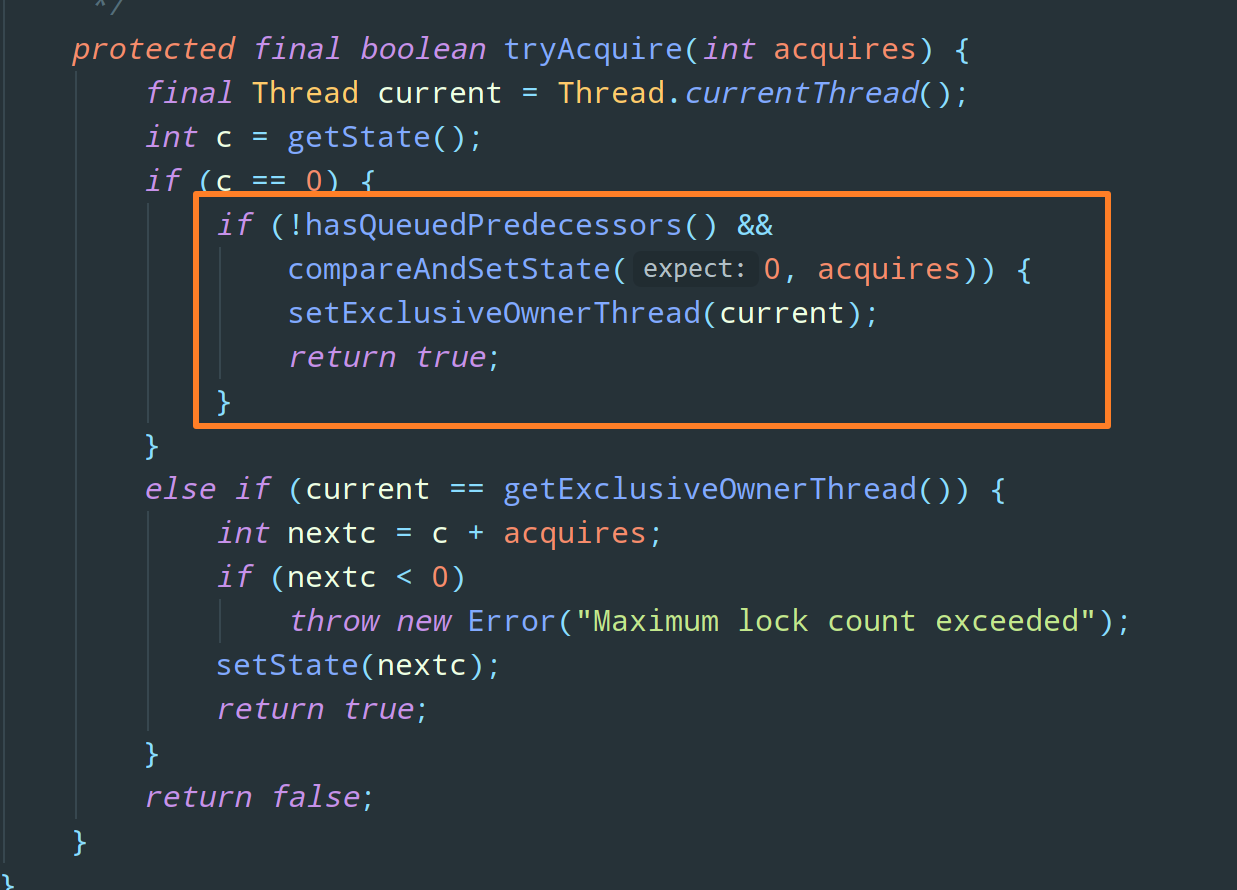
对比下非公平锁的 nonfairTryAcquire,你会发现这两个方法基本上是差不多的,只不过公平锁多了一个 hasQueuedPredecessors 的逻辑判断,可以看下这个方法:
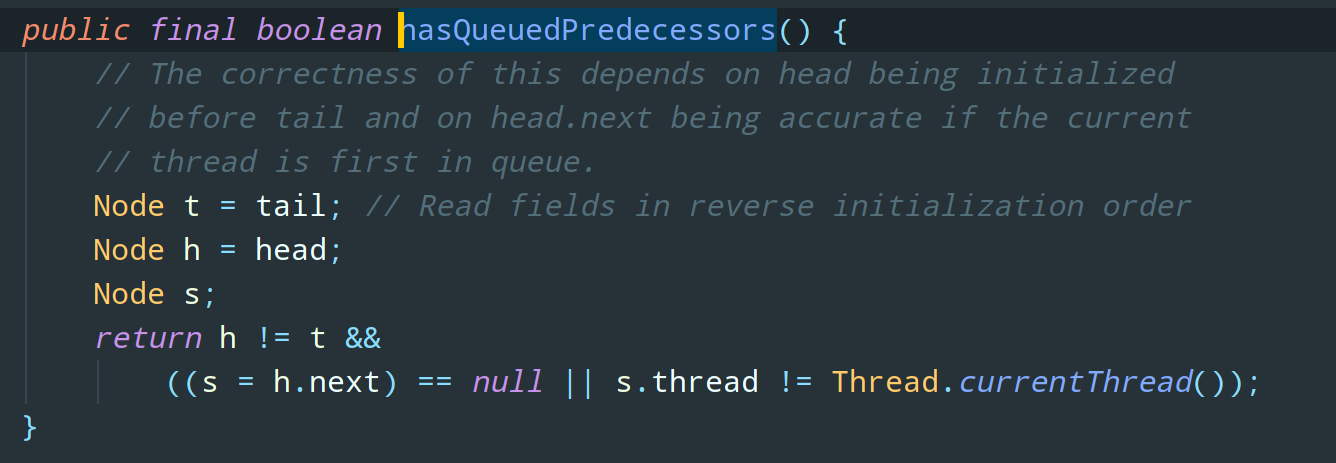
很简单,其实从方法名都能看出来,就是判断下当前节点是否有前驱节点,如果有则返回 true。
那么公平锁整体的逻辑就是,如果等待队列中当前节点(尝试获取锁的当前线程)存在前驱节点,则表示有线程比当前线程更早地请求获取锁,所以,公平来讲,当前线程需要等待前驱线程获取并成功释放锁之后才能去尝试获取锁。
公平锁 vs. 非公平锁
可以发现,ReentrantLock 无论是无参构造还是 tryLock 方法,使用的都是非公平锁的方式。这是为啥呢?因为非公平锁的性能更高。
公平锁为了保证公平,保证按照时间顺序来获取锁,就必定要进行频繁的线程上下文切换,而非公平锁不需要,谁 CAS 成功了谁就能拿到锁,极少的线程切换保证了其更大的吞吐量。
当然,公平锁的存在自然有它的意义,虽然说非公平锁的性能更好,但是存在线程 “饥饿” 现象,也就是说由于非公平锁采用了争抢的方式,有可能导致某些线程永远也获取不到锁。
所以至于公平锁还是非公平锁,按照场景来选择才是明智之举。
读写锁 ReentrantReadWriteLock
读写锁概述
各位回顾下我们到现在为止学过的几种锁:synchronized 和 ReentrantLock,这两种锁都是排他锁,也就是说在同一时刻只允许一个线程进行访问。
而这篇要讲的读写锁,从名字上也能看出来它包含读和写这一对锁。写锁仍然是排他锁,在写线程访问时,所有的读线程和其他写线程均被阻塞;但是读锁是共享锁,在同一时刻可以允许多个读线程进行访问。
需要注意的是,和 ReentrantLock 支持可重入一样,读写锁中的读锁和写锁也都是可重入的。
通过分离读锁和写锁,使得读写锁的并发性能相比一般的排他锁有了很大提升。
JUC 中定义了一个读写锁的接口:ReadWriteLock:

可以看到,这个接口只有两个方法,readLock 用来获取读锁,writeLock 用来获取写锁。
再点进去看一下 ReadWriteLock 的具体实现:

这里有两个读写锁的具体实现类,一个是比较常见的 ReentrantReadWriteLock,另一个是 Java 8 中新增的 StampedLock,后者是对前者的增强,这里我们先暂且不提,本文重点讲下 ReentrantReadWriteLock。
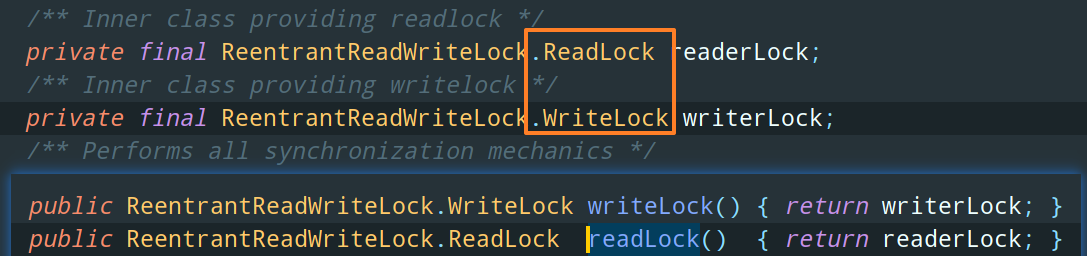
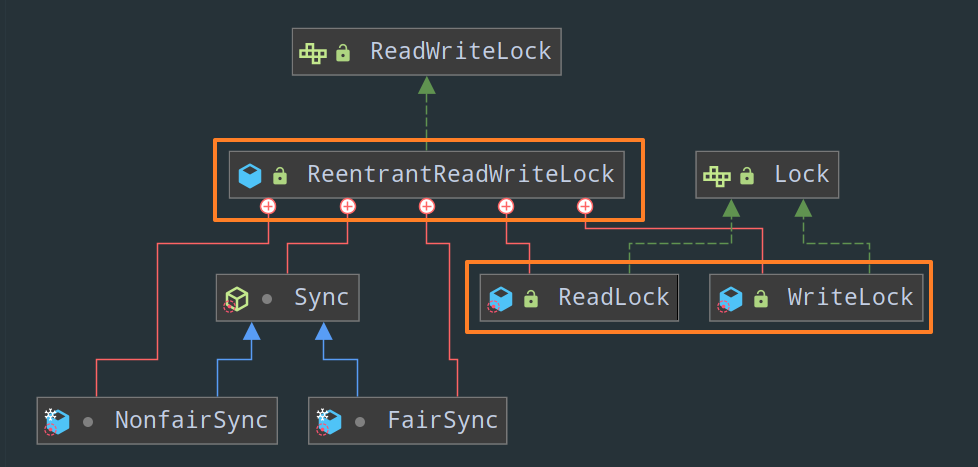
可以发现,ReentrantReadWriteLock 中包含两个内部类,一个是读锁 ReadLock,另一个是写锁 WriteLock,看一眼类的关系图就很明白了:
下面来看一个示例,了解下读写锁的基本使用方式:
public class Test {
static Map<String, Object> map = new HashMap<String, Object>();
// 读写锁
static ReentrantReadWriteLock rwl = new ReentrantReadWriteLock();
// 读锁
static Lock readLock = rwl.readLock();
// 写锁
static Lock writeLock = rwl.writeLock();
// 获取一个 key 对应的 value
public static final Object get(String key) {
// 加读锁
readLock.lock();
try {
return map.get(key);
} finally {
// 释放读锁
readLock.unlock();
}
}
// 设置 key 对应的 value,并返回旧的 value
public static final Object put(String key, Object value) {
// 加写锁
writeLock.lock();
try {
return map.put(key, value);
} finally {
// 释放写锁
writeLock.unlock();
}
}
}编码方式非常简单,在读操作时获取读锁,写操作时获取写锁。当写锁被获取到时,后续(非当前写操作线程)的读写操作都会被阻塞,写锁释放之后,所有操作继续执行。
各位不妨对比一下,如果不用读写锁,我们该怎么实现上段代码,如何使得写操作完成之后的更新对读线程立即可见?就是使用 Java 的等待通知机制,当写操作开始时,所有晚于写操作的读操作均会进入等待状态,只有写操作完成并进行通知之后,所有等待的读操作才能继续执行,这样做的目的是使读操作能读取到正确的数据,不会出现脏读。
很显然,使用读写锁之后的编码方式,比之前使用等待通知机制的方式简单得多。
ReentrantWritLock 的具体实现
下面我们来看一下读写锁 ReentrantWritLock 的具体设计:
- 读写状态的设计
- 写锁的获取与释放
- 读锁的获取与释放
设计读写状态
各位先回顾下 ReentrantLock 中是怎么设置锁的状态的,没错,就是那个 state 变量,通过对 state 变量的加减来表示该锁被同一个线程获取的次数,从而实现可重入操作。
ReentrantLock 是排他锁,同一个时间要么是读线程在占有它,要么是写线程在占有它,所以这个 state 变量只需要维护一个特征就行了。但是,ReentrantReadWriteLock 同时需要维护读锁和写锁,写锁是排他锁,读锁是共享锁,也就是说它需要用这个 state 变量去维护多个读线程和当前写线程的状态。
举个例子,如果当前线程在获取写锁时,读锁已经被获取(读状态不为 0),或者,写锁已经被获取并且该线程不是已经获取写锁的线程,那么,当前线程就会进入等待状态。
那如何在一个整型变量上维护多种状态呢?
这里就需要 “按位切割使用” 的方法,即将 32 位的整型变量 state 切分成两个部分,高 16 位表示读,低 16 位表示写:
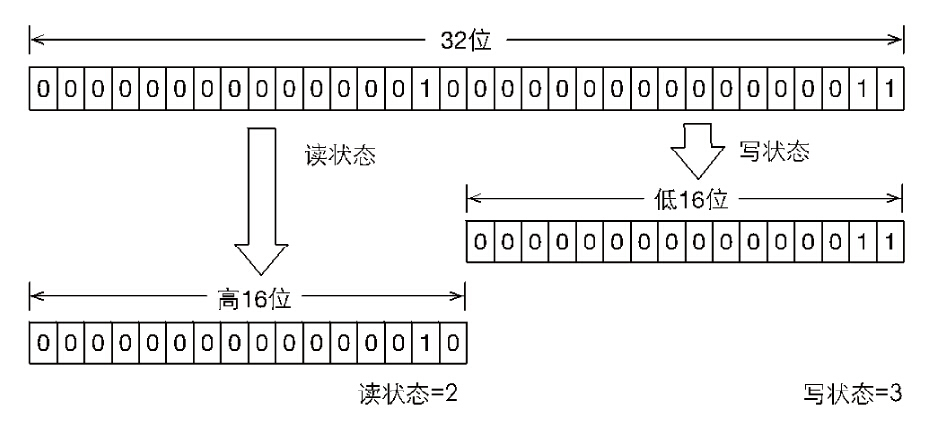
如上图,当前 state 变量表示一个线程已经获取了写锁,且重进入了两次,同时也连续获取了两次读锁。
ReentrantReadWriteLock 是如何从这个变量中快速确定读和写各自的状态呢?
位运算!
假设当前同步状态值为 S,计算写状态很简单,将高 16 位全部抹去就好了,即 S & 0x0000FFFF,当写状态增加1时,等于 S+1;
读状态等于 S>>>16,即无符号补 0 右移 16 位。当读状态增加1时,等于 S+(1<<16),也就是 S+0x00010000。
写锁的获取与释放
写锁的释放过程这里就不说了,和 ReentrantLock 的逻辑一样,因为是可重入锁,所以每释放一次写锁就将写锁的状态 - 1 即可。
当我们执行以下代码进行加写锁时:
static Lock writeLock = rwl.writeLock();
writeLock.lock();我们去看看写锁具体的 lock 方法是怎么样的:

调用 AQS 的模板方法 acquire,然后这个模板方法中会去调用 tryAcquire 这个开放给子类进行重写的方法(这个上篇文章已经解释过),ReentrantReadWriteLock 中是怎么重写 tryAcquire 方法的呢:
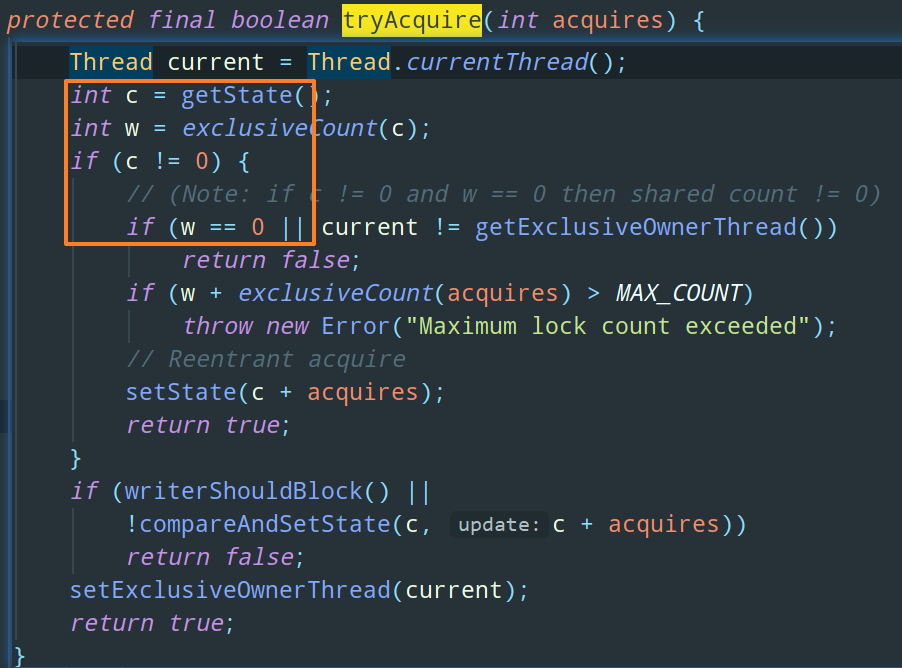
和 ReentrantLock 差不多,除了可重入的处理,这里还增加了一个对读锁的排他处理。各位可以代码中的那一行注释:
Note: if c != 0 and w == 0 then shared count != 0具体来说,代码中 c 这个变量获取到的就是 state 的值,w 这个变量表示的就是 state 中低 16 位的写状态,这里其实有一个推论,那就是如果 state != 0,而 state 的低 16 位 = 0,那是不是就表明 state 的高 16 为一定 != 0,对吧,很好理解。也就是说,如果整体的 state 状态不为 0,而写锁状态为 0,那么说明读锁一定大于 0,即表示读锁已经被获取。如果存在读锁,那么写锁不能被获取。
读锁的获取与释放
同样的,读锁的释放过程这里也不说了,每释放一次读锁就将读锁的状态 - 1 即可。
当我们执行以下代码进行加读锁时:
static Lock readLock = rwl.readLock();
readLock.lock();我们去看看读锁具体的 lock 方法是怎么样的:
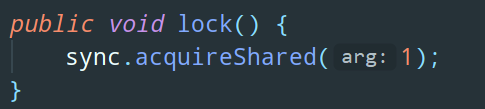
调用 AQS 的模板方法 acquireShared,然后这个模板方法中会去调用 tryAcquireShared 这个开放给子类进行重写的方法:
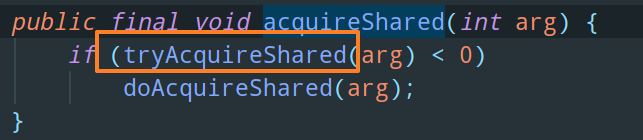
ReentrantReadWriteLock 中是怎么重写 tryAcquireShared 方法的呢:
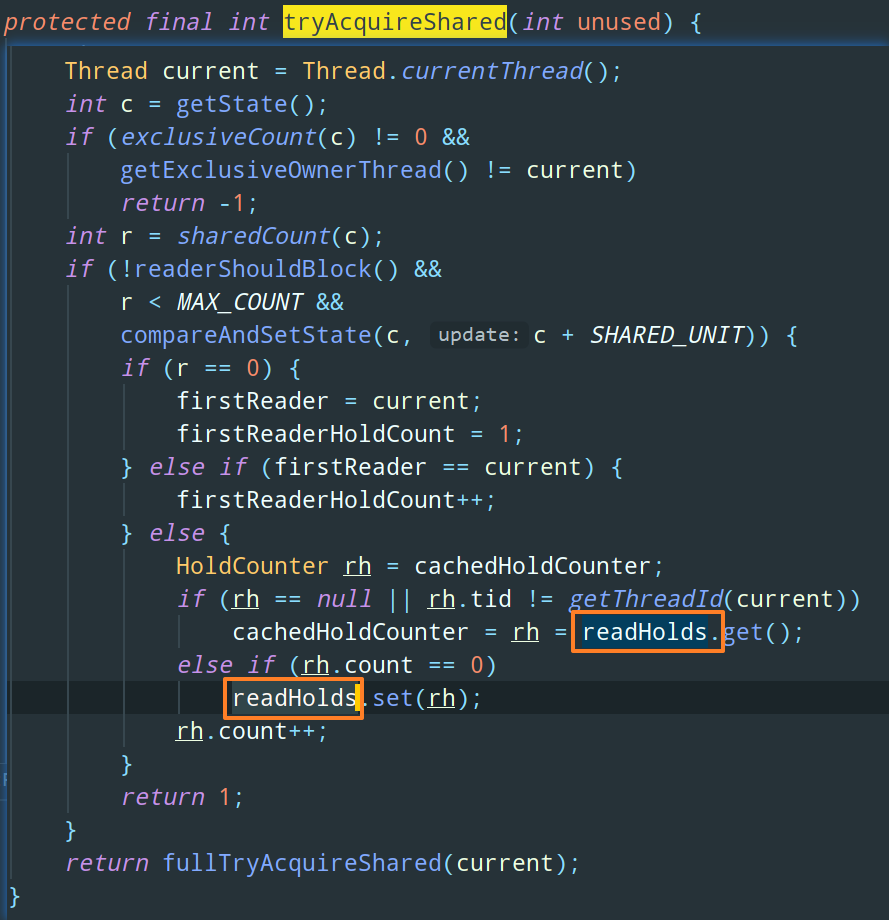
逻辑其实很简单:如果当前线程已经获取了读锁,则增加读状态;如果当前线程在获取读锁时,写锁已被其他线程获取,则进入等待状态;如果写锁是被当前线程获取或者写锁未被获取,则当前线程可以成功获取读锁,增加读状态。
上述代码看起来复杂的原因是获取读锁的实现从 Java 5 到 Java 6 变得复杂许多,主要原因是读状态是所有线程获取读锁次数的总和,而每个线程各自获取读锁的次数只能选择保存在 ThreadLocal 中,由每个线程自己来维护,这使获取读锁的实现变得复杂。
对应到代码中就是图中框出来的那个变量 readHolds,表示当前线程持有的读锁的数量:

锁降级
注意,读写锁中的锁降级不要和 synchronized 的锁升级(锁膨胀)搞混了,事实上这两者就不是一个维度的概念,synchronized 中的锁升级是 JVM 底层帮助我们自动实现的,而读写锁中的锁升级是我们在代码中自己手动制造出来的。
解释一下:读写锁中的锁降级指的是,写锁降级成为读锁。即把持住当前线程所拥有的写锁,然后获取到读锁,随后释放先前拥有的写锁。可以看下 ReentrantReadWriteLock 源码中关于锁降级的示例:
void processCachedData() {
// 获取读锁
rwl.readLock().lock();
if (!cacheValid) {
// 先释放读锁
rwl.readLock().unlock();
// 获取写锁
rwl.writeLock().lock();
try {
// Recheck state because another thread might have
// acquired write lock and changed state before we did.
if (!cacheValid) {
data = ...
cacheValid = true;
}
// 把持住当前线程所拥有的写锁,然后获取读锁
rwl.readLock().lock();
} finally {
// 随后释放先前拥有的写锁
rwl.writeLock().unlock();
}
// 锁降级完成,写锁降级为读锁
}
try {
use(data);
} finally {
rwl.readLock().unlock();
}
}那,锁降级的应用场景是什么呢?
举个例子,线程 A 修改了共享变量(加写锁)并且马上就想使用它(加读锁),那如果线程 A 直接释放写锁然后再去加读锁的话(分段获取),假设此刻另一个线程 B 比线程 A 先一步获取了写锁并修改了数据,那么线程 A 是无法感知到线程 B 所做的数据更新的。
如果线程 A 遵循锁降级的步骤,则线程 B 试图进行获取写锁进行更新的时候将会被阻塞住,直到线程 A 使用完数据并释放读锁之后,线程 B 才能获取写锁进行数据更新。
所以锁降级的主要作用是保证数据的可见性。
图解 Condition 接口
基本使用
前面的文章中我们把 Lock 的加锁和解锁的过程已经讲清楚了,事实上,仅仅是这些还不足以说 Lock 这一套体系有多么强大,回顾下 synchronized 的知识,我们可以通过 Object 类中的 wait 和 notify/notifyAll 方法来随时随地的去挂起和唤醒线程,那对于 Lock 来说,它是通过 Condition 这个接口来实现的:
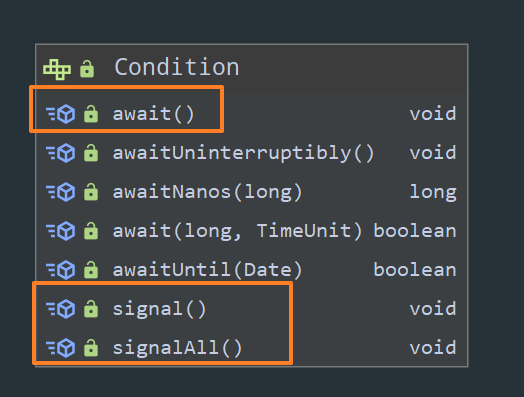
差不多的,await 对应 wait 用来挂起线程,signal/signalAll 对应 notify/notifyAll 用来唤醒线程。
那我们该怎样去获取到 Condition 这个接口对象,从而去调用它其中的方法呢?
这个时候就要掏出我们的 Lock 了:
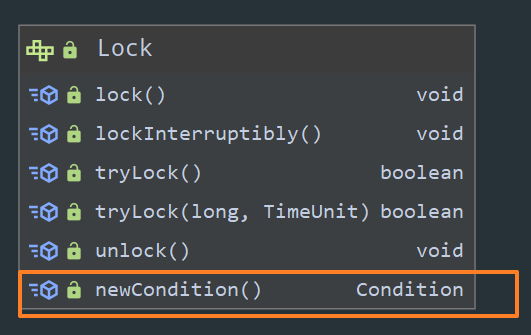
Lock 接口中总共只有六个方法,前面五种我们基本上已经讲的差不多了,今天我们要讲的最后一个方法 newCondition,它返回的就是一个 Condition 对象!
所以,Condition 对象是调用 Lock 对象的 newCondition 方法创建出来的,换句话说,Condition 的存在是依赖于 Lock 对象的。
下面我们来看下 Condition 的基本使用:
// 创建 Lock 对象
Lock lock = new ReentrantLock();
// 通过 Lock 对象创建 Condition 对象
Condition condition = lock.newCondition();
public void conditionWait() throws InterruptedException {
// 加锁
lock.lock();
try {
// 挂起线程
condition.await();
} finally {
// 解锁
lock.unlock();
}
}
public void conditionSignal() throws InterruptedException {
lock.lock();
try {
// 唤醒线程
condition.signal();
} finally {
lock.unlock();
}
}底层原理
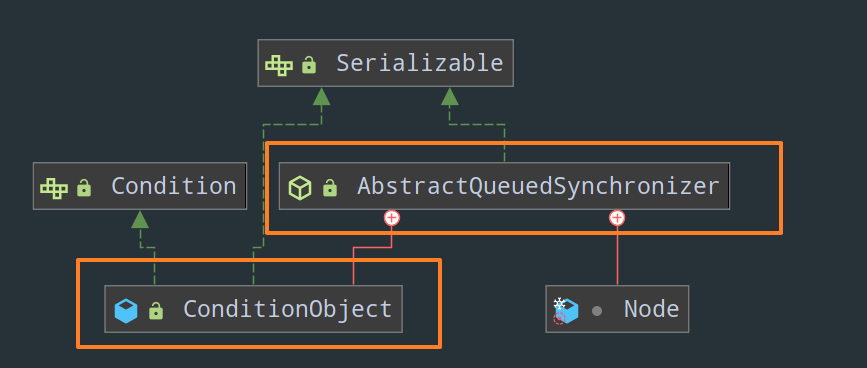
看一下哪些类实现了 Conditioin 接口:

o nice~ 这不是我们熟悉的 AQS 吗,点进去瞅瞅:

ConditionObject 是 AQS 的一个内部类,它实现了 Condition 接口:
那 ConditionObject 具体是如何实现阻塞 await 和唤醒 signal 线程的呢?
队列!
在之前的文章《通俗易懂之 AQS》中,我们提到过,如果没竞争到锁,这个线程就会进入 CLH 队列。
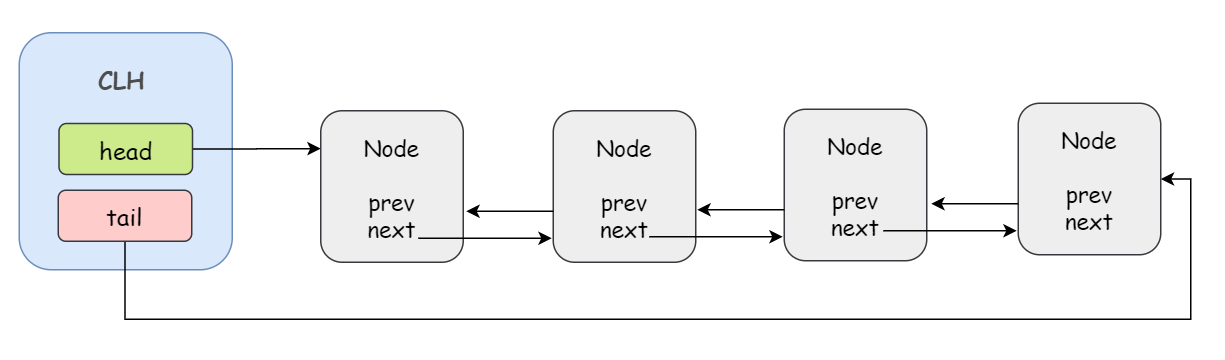
为了和今天我们要讲的 Condition 中的等待队列进行区分,我们把 AQS 中的 CLH 队列称为同步队列。
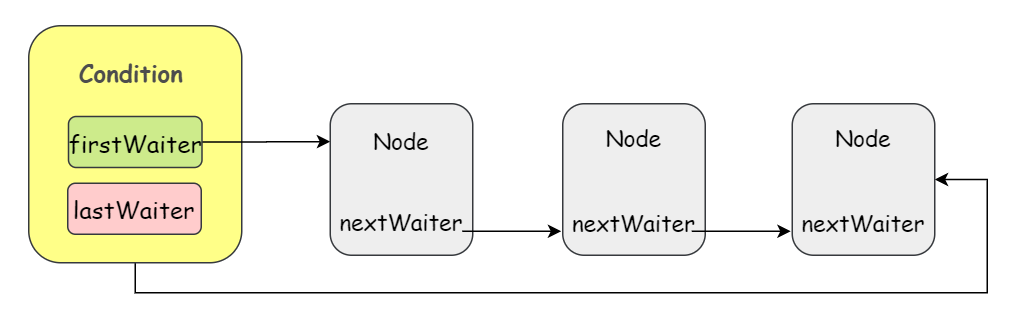
可以看到,Condition 中等待队列的节点实现和同步队列是一样的,用的都是 AQS 中的 Node 节点。
不同之处在于,CLH 同步队列是一个 FIFO 的双向队列,而 Condition 等待队列是一个 FIFO 的单向队列!
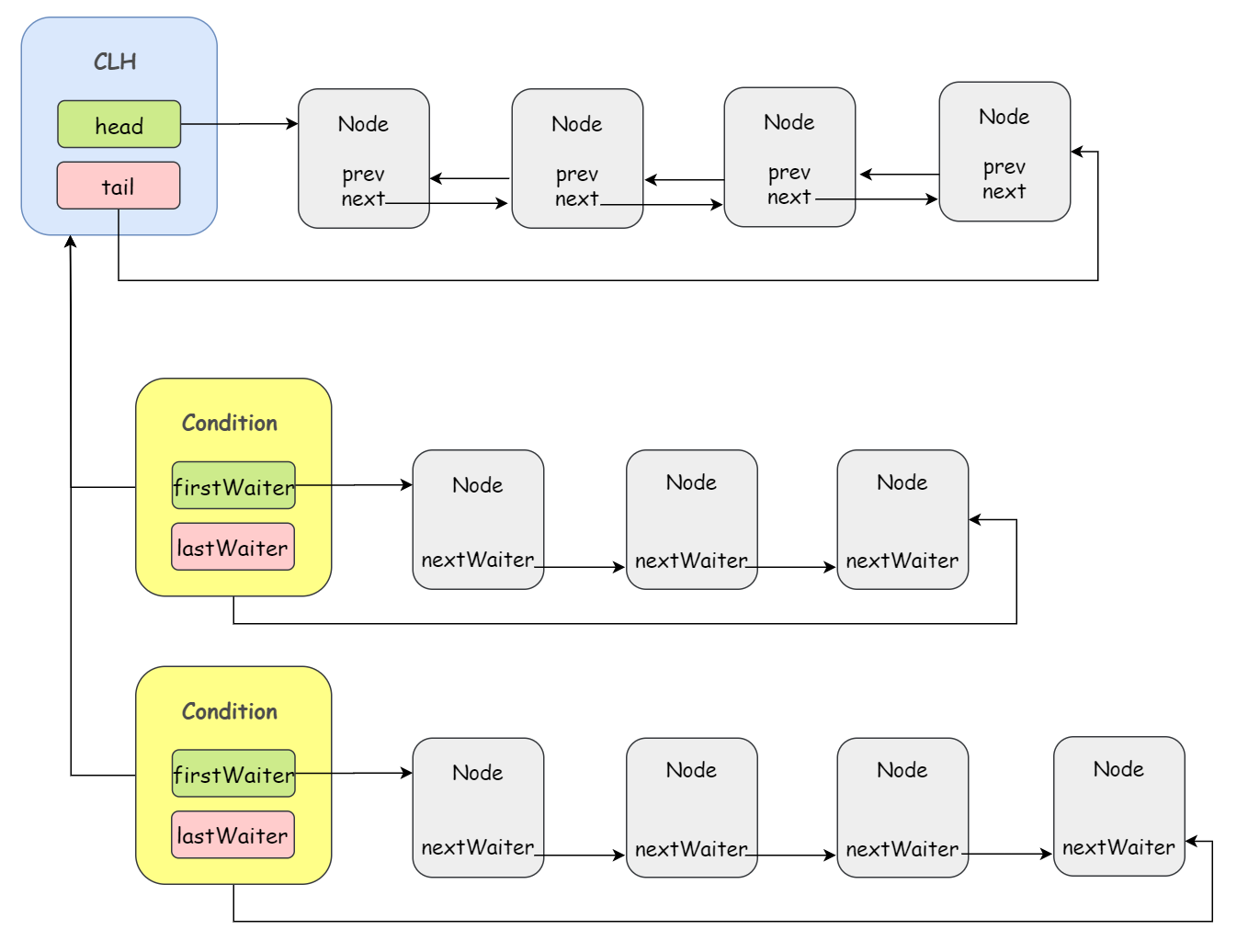
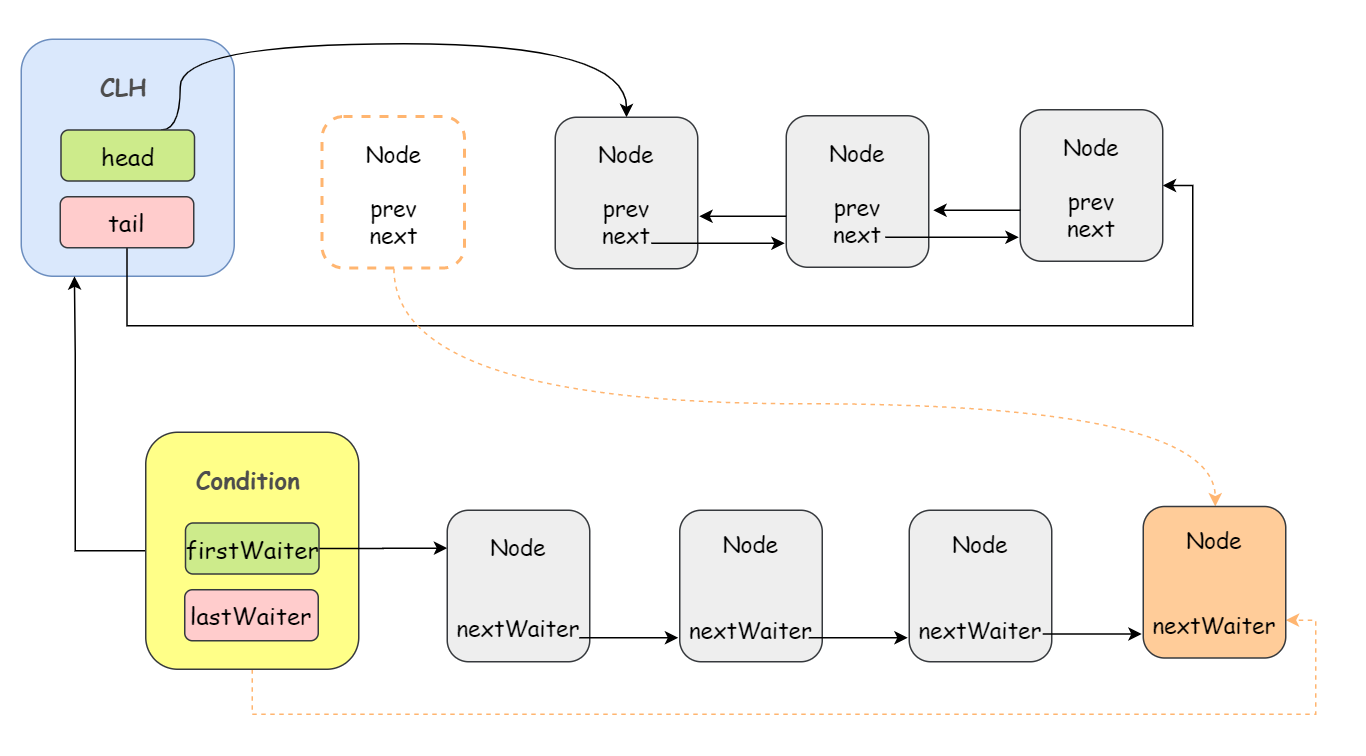
一个 Condition 包含一个等待队列,一个 Lock 对象可以构造出多个 Condition 对象,也就是说,一个 Lock 对象可以拥有一个同步队列和多个等待队列:
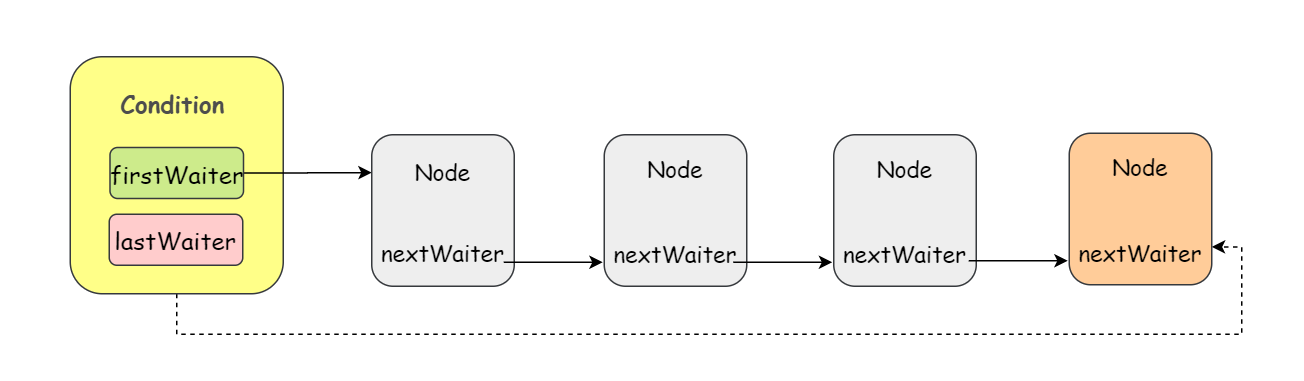
await
Condition 拥有首节点(firstWaiter)和尾节点(lastWaiter)。当前线程调用Condition.await() 方法,将会以当前线程构造节点,并将节点从尾部加入等待队列。
不同于 CLH 同步队列在尾部添加节点时需要使用 CAS 操作,Condition 等待队列不需要 CAS 的保证,因为 Condition 和随着 Lock 的出现而出现的,也即调用 await 方法的线程必定是获取了 Lock 的线程,不会有其他线程来争夺这个添加尾部节点的操作。
如下图所示:
看到这里各位可能会有点困惑,CLH 同步队列和 Condition 等待队列的区别是什么?
我来帮大家梳理一下:
首先回顾一下,如果当前线程没竞争到锁,这个线程就会进入 CLH 同步队列;CLH 同步队列 中的第一个节点就是成功获取同步资源的节点,首节点的线程在释放同步资源时,将会唤醒器其后继节点,而后继节点被唤醒后,就会重新尝试加锁;
而 await 这个方法,一定是当前占据锁的线程调用的,当前占据锁的线程就是 CLH 同步队列的首节点,对吧。也就是说,CLH 同步队列的首节点(称为 A)调用 await 方法暂时释放掉了它所持有的锁,这样,它的后继节点就会被唤醒去尝试加锁。
那 A 节点去哪里了呢?Condition 等待队列的尾部!
简单来说,当调用 await 方法时,相当于将 CLH 同步队列的首节点移动到 Condition 等待队列的尾部。
signal
同样的,signal 这个方法,一定是当前占据锁的线程调用的。
await 方法是将 CLH 同步队列的首节点移动到 Condition 等待队列的尾部,那么 signal 方法就是相反的,将 Condition 等待队列的首节点移动到 CLH 同步队列的尾部

需要注意的是,其实从图中也可以看出来,当前线程调用 signal 方法的时候,并不会释放掉自身持有的锁,这和 synchronized 的 notify 方法是一致的。
signalAll 方法就很好理解了,就是将等待队列中所有节点全部移动到同步队列中。
1 Comment
Comments are closed.