不知道你在平时工作中是否遇到过乱码问题?我最早遇到的乱码问题还是刚开始学 C 语言编程时,有时候在 Console 上会输出“烫烫烫”这样的信息。在使用 MySQL 时,也遇到过各种乱码,乱码可能会以不同的形式出现。
那么在这一讲中,我们就来分析 MySQL 中出现乱码的几种不同情况,以及乱码产生的底层原因,从而掌握处理和避免乱码问题的方法。
编码与解码
平时我们会使用文字和符号来进行交流,比如“中文符号”就是一个有明确含义的词组。我们也知道计算机底层是使用二进制来存储和传输数据,那么计算机如何以二进制的形式来表示“中文符号”这个词组呢?这就涉及到字符的编码了。对于中文字符,比较常用的编码方式就包括 GBK、UTF8,当然也包括其他一些编码方式,但我们这里就不过多讨论了,因为底层原理是一样的。
“中文符号”使用 GBK 编码后,是这个样子的。

而使用 UTF8 编码时,是这个样子的。

我们可以在网上找到 GBK 的编码表,也可以找到 Unicode 的表,而 Unicode 可以用明确的算法转换成 UTF8 编码。这里我们提供一个简便的方法,使用 Python(python2) 来获取字符的编码。
### GBK
>>> u"中文符号".encode('gbk')
'\xd6\xd0\xce\xc4\xb7\xfb\xba\xc5'
### UTF8
>>> u"中文符号".encode('utf8')
'\xe4\xb8\xad\xe6\x96\x87\xe7\xac\xa6\xe5\x8f\xb7'现在你应该已经知道编码的过程了。程序在处理文本信息时,还涉及到解码。解码是编码的反向操作,将二进制的数据解析成一个个的字符,比如上面这段 GBK 编码后的数据,解码后就得到了原始的信息。
>>> '\xd6\xd0\xce\xc4\xb7\xfb\xba\xc5'.decode('gbk')
u'\u4e2d\u6587\u7b26\u53f7'
>>> print '\xd6\xd0\xce\xc4\xb7\xfb\xba\xc5'.decode('gbk')
中文符号到目前为止没有任何问题。但是我想请你思考一下:程序怎么知道一段特定的数据是采用哪种字符集编码的呢?
实际上没有办法仅仅依赖数据本身就得知数据的编码方式。很多乱码问题就是弄错了字符集而导致的。
接着上面的例子,如果程序以为数据使用了 UTF8 编码(但是实际上并不是),就会出现这种情况。
>>> '\xd6\xd0\xce\xc4\xb7\xfb\xba\xc5'.decode('utf8', errors='replace')
u'\ufffd\ufffd\ufffd\u0137\ufffd\ufffd\ufffd'
>>> print '\xd6\xd0\xce\xc4\xb7\xfb\xba\xc5'.decode('utf8', errors='replace')
���ķ���
由于这些数据中很多字节并不是合法的 UTF8 编码,无法解码成 Unicode,便使用了符号“�”来代替。
类似的,如果原始数据使用了 UTF8 编码,但错误地使用了 GBK 来解码,就会出现这种情况。
>>> '\xe4\xb8\xad\xe6\x96\x87\xe7\xac\xa6\xe5\x8f\xb7'.decode('gbk', errors='replace')
u'\u6d93\ufffd\u6783\u7ed7\ufe40\u5f7f'
>>> print '\xe4\xb8\xad\xe6\x96\x87\xe7\xac\xa6\xe5\x8f\xb7'.decode('gbk', errors='replace')
涓�枃绗﹀彿
上面我们见到了乱码产生的一些情况,而现实中其实还存在着更复杂一些的情况。
比如,发送者使用 GBK 编码,接收者接收到数据后,使用 UTF8 解码,然后又将数据以 UTF8 的方式编码后返回给发送者。发送者接收到数据后,再使用 GBK 来解码,就会遇到经典的“锟斤拷”问题。
### 发送者编码(GBK)
>>> u"中文符号".encode('gbk')
'\xd6\xd0\xce\xc4\xb7\xfb\xba\xc5'
### 接收者解码(UTF8) 和 编码(UTF8)
>>> '\xd6\xd0\xce\xc4\xb7\xfb\xba\xc5'.decode('utf8',errors='replace').encode('utf8')
'\xef\xbf\xbd\xef\xbf\xbd\xef\xbf\xbd\xc4\xb7\xef\xbf\xbd\xef\xbf\xbd\xef\xbf\xbd'
### 发送者解码(GBK)
>>> print '\xef\xbf\xbd\xef\xbf\xbd\xef\xbf\xbd\xc4\xb7\xef\xbf\xbd\xef\xbf\xbd\xef\xbf\xbd'.decode('gbk')
锟斤拷锟侥凤拷锟斤拷
类似的,有时可能还会遇到这种情况。
### 发送者编码(UTF8)
>>> u"中文符号".encode('utf8')
'\xe4\xb8\xad\xe6\x96\x87\xe7\xac\xa6\xe5\x8f\xb7'
### 接收者解码(GBK) 和 编码(UTF8)
>>> '\xe4\xb8\xad\xe6\x96\x87\xe7\xac\xa6\xe5\x8f\xb7'.decode('gbk', errors='replace').encode('utf8')
'\xe6\xb6\x93\xef\xbf\xbd\xe6\x9e\x83\xe7\xbb\x97\xef\xb9\x80\xe5\xbd\xbf'
### 发送者解码(GBK)
>>> '\xe6\xb6\x93\xef\xbf\xbd\xe6\x9e\x83\xe7\xbb\x97\xef\xb9\x80\xe5\xbd\xbf'.decode('gbk', errors='replace')
u'\u5a11\u64c4\u62f7\u93cb\u51aa\u7cad\u9515\ufffd\u5a07'
>>> print '\xe6\xb6\x93\xef\xbf\xbd\xe6\x9e\x83\xe7\xbb\x97\xef\xb9\x80\xe5\xbd\xbf'.decode('gbk', errors='replace')
娑擄拷鏋冪粭锕�娇
MySQL 如何处理文本数据?
从上面的例子中可以看出,程序无法仅仅根据数据本身就知道具体的编码方式,而编码和解码时,如果使用了错误的字符集,就会出现乱码。
而 MySQL 处理文本数据时,存在一样的问题:
- 客户端发送过来的数据使用什么了编码格式?
- 服务器端处理数据时,应该使用哪种编码格式?
- 将数据存储到表里时,使用什么字符集进行编码?
- 将查询结果发送给客户端时,又应该如何编码数据?
MySQL 使用了一系列变量来告诉服务器,客户端发送过来的数据是怎么编码的,客户端希望接收到什么编码的数据。
表和列的字符集属性则告诉服务器,存储数据时应该怎么编码,读取数据时又应该怎么解码。
字符集变量
执行 show variables 命令就能查看到字符集相关的变量。
mysql> show variables like '%char%';
+--------------------------+------------------------------------------------------+
| Variable_name | Value |
+--------------------------+------------------------------------------------------+
| character_set_client | utf8mb3 |
| character_set_connection | utf8mb3 |
| character_set_database | big5 |
| character_set_filesystem | binary |
| character_set_results | utf8mb3 |
| character_set_server | utf8mb4 |
| character_set_system | utf8mb3 |在 MySQL 中,想避免产生乱码,首先需要正确地设置这些变量。下面的表格对这些变量做了简要的说明。

表和列的字符集属性
MySQL 中,所有字符类型的字段都有对应的字符集属性。表和列的字符集属性规定了以何种编码存储字符类数据。如果表的字符集属性设置不对,也容易引起乱码。
建表的时候,如果我们不指定表或列的字符集,MySQL 会基于一些规则来设置一个默认的字符集。
规则 1:建库时,如果不指定库的字符集,则根据参数 character_set_server 的配置来设置库的默认字符集。
mysql> show variables like '%character_set_server%';
+----------------------+--------+
| Variable_name | Value |
+----------------------+--------+
| character_set_server | latin1 |
+----------------------+--------+
1 row in set (0.00 sec)
### 建库时指定字符集
mysql> create database db_latin;
Query OK, 1 row affected (0.00 sec)
### 库的字符集从变量character_set_server中获取
mysql> show create database db_latin;
+----------+--------------------------------------------------------------------------------------------------------+
| Database | Create Database |
+----------+--------------------------------------------------------------------------------------------------------+
| db_latin | CREATE DATABASE `db_latin` /*!40100 DEFAULT CHARACTER SET latin1 */ /*!80016 DEFAULT ENCRYPTION='N' */ |
+----------+--------------------------------------------------------------------------------------------------------+规则 2:建表时,如果不指定表的字符集,则以表所在的数据库的字符集作为表的默认字符集。
### 指定库的字符集 UTF8
mysql> create database db_utf8 default character set utf8;
Query OK, 1 row affected, 1 warning (0.00 sec)
### 库的字符集为GBK
mysql> create database db_gbk default character set gbk;
Query OK, 1 row affected (0.00 sec)
### 建表时不指定字符集
mysql> create table db_utf8.t(a varchar(100));
Query OK, 0 rows affected (0.00 sec)
mysql> create table db_gbk.t(a varchar(100));
Query OK, 0 rows affected (0.00 sec)
### UTF8库中的表默认使用了UTF8字符集
mysql> show create table db_utf8.t\G
*************************** 1. row ***************************
Table: t
Create Table: CREATE TABLE `t` (
`a` varchar(100) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3
1 row in set (0.01 sec)
### GBK库中的表默认使用了GBK字符集
mysql> show create table db_gbk.t\G
*************************** 1. row ***************************
Table: t
Create Table: CREATE TABLE `t` (
`a` varchar(100) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=gbk
1 row in set (0.00 sec)规则 3:建表时,如果不指定字段的字符集,则字段的字符集设置为表的默认字符集。
规则 4:如果显式指定字段的字符集,则以指定的字符集为准。
mysql> alter table db_gbk.t add c1 varchar(10),
add c2 varchar(10) character set utf8mb4;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
### 列C2使用了跟表不一样的字符集。但一般我们建议不要这么用。
mysql> show create table db_gbk.t\G
*************************** 1. row ***************************
Table: t
Create Table: CREATE TABLE `t` (
`a` varchar(100) DEFAULT NULL,
`c1` varchar(10) DEFAULT NULL,
`c2` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=gbk
1 row in set (0.00 sec)一般情况下,我们建议都在建表的时候显式指定表的字符集。同一个表的多个字段尽量使用相同的字符集,不混合使用多个字符集。同一个库里的多个表,也使用同样的字符集。混合使用不同的字符集就会导致一些问题:
- 容易发生乱码问题。
- 表连接时可能会发生隐式类型转换,导致查询无法用到一些索引,从而影响查询的性能。关于这一点,后续的课程中还会有具体的例子,这里不再展开。
下面我们借助这个图,对文本数据在客户端、MySQL 服务端、存储引擎之间的传输和处理时如何编码和解码做一个小结。

- 服务端认为客户端发送过来的数据的字符集是 character_set_client。
- 如果 character_set_connection 和 character_set_client 设置不一样,MySQL Server 端会将数据转换成 character_set_connection 指定的字符集。
- 数据存储到表里时,根据表结构定义中指定的字符集进行转换。如果字符集一致,则这一步不需要进行转换。
- 数据返回到客户端时,按 character_set_results 的设置进行编码。
MySQL 中乱码是如何产生的?
这里我们再来回顾一下前面讲解的几个关键点。
1、文本数据在传输、处理、存储时涉及到编码和解码的过程。
2、编码和解码时,如果使用了错误的字符集,就会产生乱码。
3、MySQL 使用了一系列的变量来指定文本处理不同阶段使用的字符集。
4、MySQL 字符类型的字段都有对应的字符集属性,规定了存储数据时应该如何编码。
实际上,MySQL 中会产生乱码,主要也是因为字符集相关的变量(character_set_client, character_set_connection,character_set_result)设置不正确,或者表和字段的字符集属性设置不对。
接下来,我们通过几个具体的例子来演示 MySQL 中乱码是如何产生的。在这些例子中,我们都会使用 MySQL 自带的客户端。应用程序从数据库读写数据时,过程基本上也是一样的。
我们先提供一个用来判断当前终端编码的简便方法,就是使用 MySQL 的 hex 函数。
这是一个 GBK 编码的终端。
mysql> select hex('中文符号');
+------------------+
| hex('中文符号') |
+------------------+
| D6D0CEC4B7FBBAC5 |
+------------------+这是一个 UTF8 编码的终端。
mysql> select hex('中文符号');
+--------------------------+
| hex('中文符号') |
+--------------------------+
| E4B8ADE69687E7ACA6E58FB7 |
+--------------------------+乱码情况 1:表的字符集属性设置错误
下面这个例子中,因为表使用了 latin1 字符集,而 latin1 不支持中文,因此写入中文时会报错。
mysql> use db1;
Database changed
mysql> create table t_latin(a varchar(100))charset latin1;
Query OK, 0 rows affected (0.01 sec)
mysql> insert into t_latin values('中文');
ERROR 1366 (HY000): Incorrect string value: '\xE4\xB8\xAD\xE6\x96\x87' for column 'a' at row 1错误的解决方法:MySQL 客户端执行将字符集改为 latin1,然后再插入数据,看起来好像能正常读写中文了。
mysql> set names 'latin1';
Query OK, 0 rows affected (0.00 sec)
mysql> insert into t_latin values('中文');
Query OK, 1 row affected (0.00 sec)
mysql> select * from t_latin;
+--------+
| a |
+--------+
| 中文 |
+--------+
1 row in set (0.00 sec)这是错误的方法(只是作为一个例子演示,真实场景下千万不要这么做),有非常大的隐患。
首先统计字符数时,可以看到结果是不对的。
mysql> set names 'latin1';
Query OK, 0 rows affected (0.00 sec)
mysql> select a, char_length(a) from t_latin;
+--------+----------------+
| a | char_length(a) |
+--------+----------------+
| 中文 | 6 |
+--------+----------------+
1 row in set (0.00 sec)而且在一个设置正常的环境下,读取到的数据会变成乱码。
mysql> select * from t_latin;
+----------------+
| a |
+----------------+
| ä¸æ–‡ |
+----------------+
1 row in set (0.00 sec)这个问题的根本原因在于,latin1 字符集无法存储中文。解决方法就是使用能正确存储中文的字符集,比如 GBK 或 UTF8。
如果你已经遇到这样的问题,可以使用一些方法进行补救。比如:
-
使用 msyqldum 导出数据,字符集指定为 latin1。
mysqldump -uroot --default-character-set=latin1 db1 t_latin > t_latin.sql -
根据数据的原始编码,修改 mysqldump 生成的 sql 文件。在我们的案例中,原始编码为 UTF8,可以这么修改。
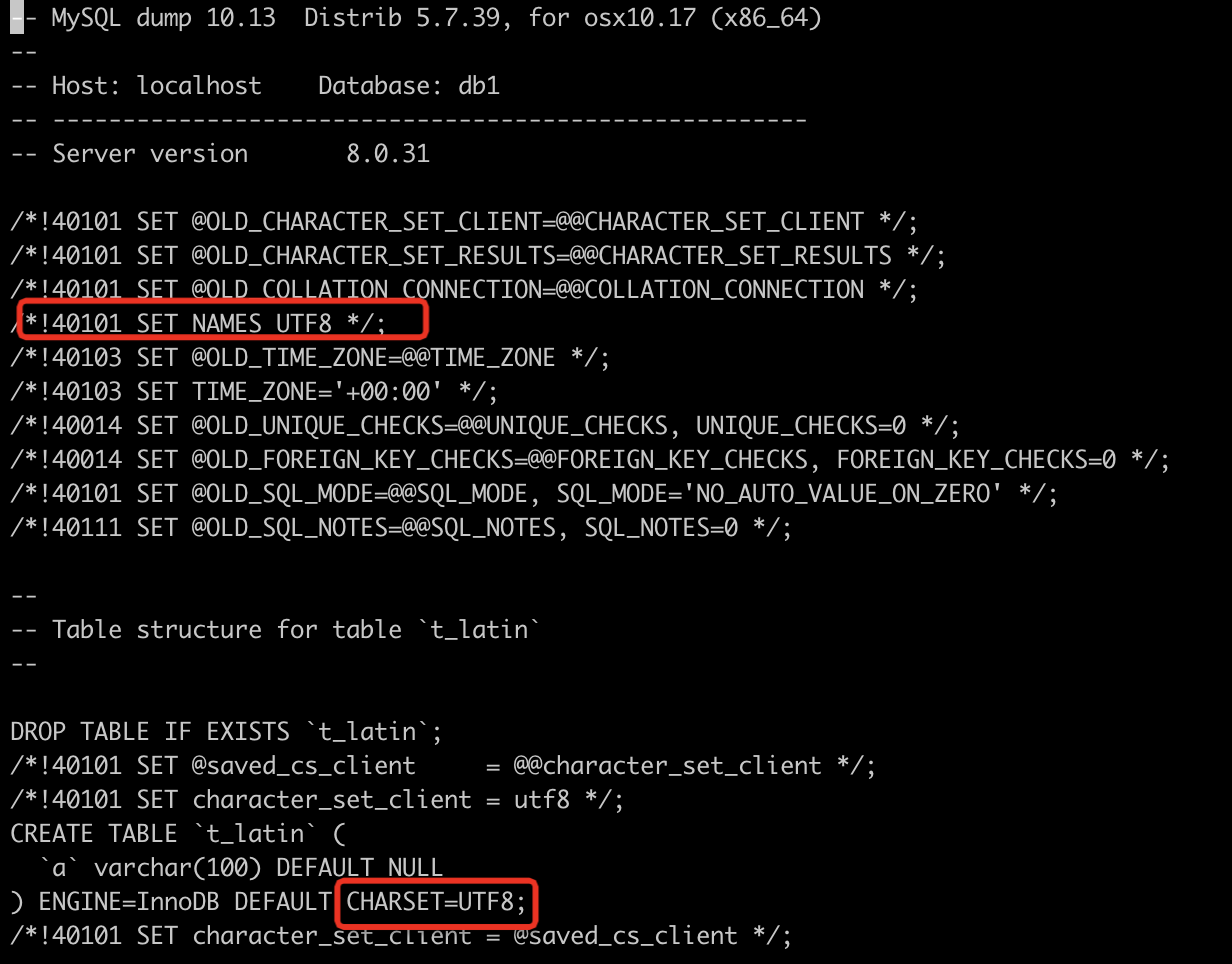
-
重新导入数据。
mysql -uroot db1 < t_latin.sql
这样处理后,数据就恢复正常了。
mysql> select a, char_length(a), hex(a) from t_latin;
+--------+----------------+--------------+
| a | char_length(a) | hex(a) |
+--------+----------------+--------------+
| 中文 | 2 | E4B8ADE69687 |
+--------+----------------+--------------+当然,操作前需要先备份好数据。处理时,也需要先暂停应用程序,避免在处理过程中写入新的有问题的数据。
乱码情况 2:character_set_result 和终端的编码不一致
终端的字符编码为 UTF8。
先准备一些(正确的)测试数据。
mysql> create table t_char1(a varchar(30)) charset utf8mb4;
Query OK, 0 rows affected (0.01 sec)
mysql> insert into t_char1 values('中文符号');
Query OK, 1 row affected (0.00 sec)
mysql> select a, hex(a) from t_char1;
+--------------+--------------------------+
| a | hex(a) |
+--------------+--------------------------+
| 中文符号 | E4B8ADE69687E7ACA6E58FB7 |
+--------------+--------------------------+
1 row in set (0.00 sec)在 UTF8 环境下,如果 character_set_results 设置为 GBK,查询数据时会看到乱码。
mysql> set character_set_results=gbk;
Query OK, 0 rows affected (0.00 sec)
mysql> select a,hex(a) from t_char1;
+----------+--------------------------+
| a | hex(a) |
+----------+--------------------------+
| ���ķ�� | E4B8ADE69687E7ACA6E58FB7 |
+----------+--------------------------+
1 row in set (0.01 sec)由于 character_set_results 设置为 GBK,MySQL 将返回的数据以 GBK 方式编码。同时因为终端是 UTF8 环境,按 UTF8 编码的数据进行解码,但是 UTF8 编码无法解析这一串数据,无法解码的数据使用了符号“�”进行替代,因此我们看到了一串问号。
我们可以使用以下 Python 代码来模拟这个过程。
>>> u"中文符号".encode('gbk')
'\xd6\xd0\xce\xc4\xb7\xfb\xba\xc5'
>>> u"中文符号".encode('gbk').decode('utf8', errors='replace')
u'\ufffd\ufffd\ufffd\u0137\ufffd\ufffd\ufffd'
>>> print u"中文符号".encode('gbk').decode('utf8', errors='replace')
���ķ���反过来,如果我们使用了 GBK 终端,那么 character_set_results 需要设置为 GBK。

mysql> set names gbk;
Query OK, 0 rows affected (0.00 sec)
mysql> select a,hex(a) from t_char1;
+----------+--------------------------+
| a | hex(a) |
+----------+--------------------------+
| 中文符号 | E4B8ADE69687E7ACA6E58FB7 |
+----------+--------------------------+
1 row in set (0.00 sec)如果 character_set_results 设置为 UTF8,则会出现另一种乱码的现象。
mysql> set character_set_results=utf8;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> select a,hex(a) from t_char1;
+--------------+--------------------------+
| a | hex(a) |
+--------------+--------------------------+
| 涓枃绗﹀彿 | E4B8ADE69687E7ACA6E58FB7 |
+--------------+--------------------------+
1 row in set (0.00 sec)这种情况下,由于 character_set_results 为 UTF8,因此 MySQL 将数据按 UTF8 方式进行编码后传输给客户端。但是由于客户端是 GBK 的编码,因此以 GBK 的方式对返回的数据进行解码。
下面的 Python 代码模拟了这个过程。
>>> u"中文符号".encode('utf8')
'\xe4\xb8\xad\xe6\x96\x87\xe7\xac\xa6\xe5\x8f\xb7'
>>> u"中文符号".encode('utf8').decode('gbk', errors='replace')
u'\u6d93\ufffd\u6783\u7ed7\ufe40\u5f7f'
>>> print u"中文符号".encode('utf8').decode('gbk', errors='replace')
涓�枃绗﹀彿上面演示的这两种乱码现象,都是由于 character_set_results 的设置和真实环境的编码不匹配引起的。虽然看上去有乱码,但实际上数据库中存储的数据没有任何问题,因此解决方法也简单,只要将 character_set_results 的设置和终端的字符编码设置成一样就可以了。
乱码情况 3:character_set_client 和终端的编码不一致
如果 character_set_client 的设置和终端的编码不一致,那么在写入数据时,就会产生乱码。我们分两种情况来讨论。
UTF8 终端,character_set_client 设置为 GBK
终端是 UTF8 编码,但是 character_set_client 错误地设置成了 GBK,此时如果写入数据,可以发现 insert 语句产生了 warning,提示编码转换存在问题。
mysql> create table t_utf8(a varchar(30)) charset utf8;
Query OK, 0 rows affected, 1 warning (0.02 sec)
mysql> set character_set_client='gbk';
Query OK, 0 rows affected (0.00 sec)
mysql> insert into t_utf8 values('中文符号');
Query OK, 1 row affected, 1 warning (0.00 sec)
mysql> show warnings;
+---------+------+-------------------------------------------------------------------------+
| Level | Code | Message |
+---------+------+-------------------------------------------------------------------------+
| Warning | 1300 | Cannot convert string '\xE4\xB8\xAD\xE6\x96\x87...' from gbk to utf8mb3 |
+---------+------+-------------------------------------------------------------------------+查看数据时,发现已经有乱码产生,而且数据库中存储的编码已经有问题了(存储了 E6B6933FE69E83E7BB97EFB980E5BDBF,正确的应该是 E4B8ADE69687E7ACA6E58FB7)。
-- 在设置正确的终端下查询数据
mysql> select a, hex(a) from t_utf8;
+------------------+----------------------------------+
| a | hex(a) |
+------------------+----------------------------------+
| 涓?枃绗﹀彿 | E6B6933FE69E83E7BB97EFB980E5BDBF |
+------------------+----------------------------------+
1 row in set (0.00 sec)由于数据库中存储的数据已经有问题了,原始数据可能会有丢失,我们可以尝试使用下面的方法来找回原始数据。
-- 终端为UTF8,将character_set_results设置为GBK
mysql> set names gbk;
Query OK, 0 rows affected (0.00 sec)
mysql> select a, hex(a) from t_utf8;
+-------------+----------------------------------+
| a | hex(a) |
+-------------+----------------------------------+
| �?��符号 | E6B6933FE69E83E7BB97EFB980E5BDBF |
+-------------+----------------------------------+
1 row in set (0.00 sec)可以看到,原始的文本为“中文符号”,我们还原了一部分数据“符号”。但是“中文”在转换过程中丢失了。
如果我们将 character_set_client 和 character_set_connection 全部都设置为 GBK,则数据写入时就会报错。
mysql> set character_set_client='gbk';
Query OK, 0 rows affected (0.00 sec)
mysql> set character_set_connection='gbk';
Query OK, 0 rows affected (0.00 sec)
mysql> insert into t_utf8 values('中文符号');
ERROR 1366 (HY000): Incorrect string value: '\xAD\xE6\x96\x87\xE7\xAC...' for column 'a' at row 1这说明了 MySQL 容忍了文本编码从 character_set_client 转换到 character_set_connection 时的错误。但如果往存储引擎中写入数据时编码转换有问题,语句就会失败,数据无法写入到数据库。
GBK 终端,character_set_client 设置为 UTF8
在这种情况下,终端是 GBK 环境,但是 character_set_client 错误地设置成了 UTF8,此时如果写入数据,可以发现 insert 语句产生了 warning,提示编码转换存在问题。
mysql> create table t_utf8_2(a varchar(30)) charset utf8;
Query OK, 0 rows affected, 1 warning (0.01 sec)
-- gbk终端
mysql> set character_set_client='utf8';
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> insert into t_utf8_2 values('中文符号');
Query OK, 1 row affected, 1 warning (0.01 sec)
mysql> show warnings;
+---------+------+-------------------------------------------------------------------------+
| Level | Code | Message |
+---------+------+-------------------------------------------------------------------------+
| Warning | 1300 | Cannot convert string '\xD6\xD0\xCE\xC4\xB7\xFB...' from utf8mb3 to gbk |
+---------+------+-------------------------------------------------------------------------+
1 row in set (0.00 sec)我们在一个编码设置正确的终端下查看数据。
mysql> select a, hex(a) from t_utf8_2;
+--------+--------------+
| a | hex(a) |
+--------+--------------+
| ?????? | 3F3F3F3F3F3F |
+--------+--------------+
1 row in set (0.00 sec)这种情况下,表里存储的数据全部变成了问号(0x3F 就是问号的 ascii 编码)。这种情况下,原始数据已经完全丢失了。
如果 character_set_client 和 character_set_connection 设置成一样,则数据转换发生在数据往存储引擎写入的过程中,语句会直接失败。
mysql> set names utf8;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> insert into t_utf8_2 values('中文符号');
ERROR 1366 (HY000): Incorrect string value: '\xD6\xD0\xCE\xC4\xB7\xFB...' for column 'a' at row 1总结一下,写入数据时,如果 character_set_client 的设置和数据的实际编码不一致,就可能会产生乱码,或者在写入数据时直接报错。如果写入了乱码数据,有可能无法获取到原先正确的数据。
乱码情况 4:表结构乱码
我们在执行 DDL 时,如果终端环境和数据库字符集参数(characte_set_client)设置不一致,并且 DDL 中使用了中文符号,也可能会产生乱码。这里产生乱码的原因和前面数据乱码的原因类似。这里简单举几个例子。
终端为 UTF8 环境,但是字符集错误地设置成了 GBK。
mysql> create database db_03;
Query OK, 1 row affected (0.00 sec)
mysql> use db_03
Database changed
mysql> create table 中文符号表_t_01(a int);
Query OK, 0 rows affected, 1 warning (0.01 sec)
mysql> show warnings;
+---------+------+-------------------------------------------------------------------------+
| Level | Code | Message |
+---------+------+-------------------------------------------------------------------------+
| Warning | 1300 | Cannot convert string '\xE4\xB8\xAD\xE6\x96\x87...' from gbk to utf8mb3 |
+---------+------+-------------------------------------------------------------------------+
1 row in set (0.00 sec)
mysql> show tables;
+---------------------+
| Tables_in_db_03 |
+---------------------+
| �?��符号表_t_01 |
+---------------------+
1 row in set (0.01 sec)我们到字符集为 UTF8 的终端下查看,发现表名依然是乱码。
mysql> set names utf8;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> show tables;
+----------------------------+
| Tables_in_db_03 |
+----------------------------+
| 涓?枃绗﹀彿琛╛t_01 |
+----------------------------+
1 row in set (0.00 sec)我们可以使用 Python 来模拟这个编码转换的过程。
### 原始编码
>>> u"中文符号表_t_01".encode('utf8')
'\xe4\xb8\xad\xe6\x96\x87\xe7\xac\xa6\xe5\x8f\xb7\xe8\xa1\xa8_t_01'
### 原始编码使用GBK解码后,再编码成UTF8
>>> u"中文符号表_t_01".encode('utf8').decode('gbk',errors='replace').encode('utf8')
'\xe6\xb6\x93\xef\xbf\xbd\xe6\x9e\x83\xe7\xbb\x97\xef\xb9\x80\xe5\xbd\xbf\xe7\x90\x9b\xe2\x95\x9bt_01'
### 这就是我们show tables看到的情况。
>>> print u"中文符号表_t_01".encode('utf8').decode('gbk',errors='replace').encode('utf8')
涓�枃绗﹀彿琛╛t_01如果我们在 GBK 编码的终端下,错误地将字符集设置成了 UTF8。
-- GBK终端
mysql> set names utf8;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> create table 中文符号表_t_02(a int);
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '???姆??疟?_t_02(a int)' at line 1
mysql> create table ` 中文符号表_t_02`(a i);
ERROR 1300 (HY000): Invalid utf8mb3 character string: '\xD6\xD0\xCE\xC4\xB7\xFB\xBA\xC5\xB1\xED_t_02'还好在这种情况下,DDL 直接失败了。
上面的例子里,我们特意使用了中文表名来做测试。MySQL 中表名、列名、表和列的注释都可以使用 Unicode,当然也包括中文。使用中文表名、列名的情况可能比较少见,但是表和字段的注释经常会使用中文,如果客户端字符集设置不对,就容易出现乱码。
乱码情况 5:数据导入导出时的字符集设置不对
我们在进行数据迁移的时候,如果某个环节字符集设置不对,就有可能会产生乱码。一般在进行数据迁移、数据导入导出后,需要重点检查下是否有乱码产生。mysqldump 是很常用的一个数据备份工具,接下来我们使用 mysqldump 来演示一个由于字符集设置不对而导致的乱码问题。
先创建一个测试表,准备一点测试数据。
mysql> create database db_emoji;
Query OK, 1 row affected (0.00 sec)
mysql> use db_emoji
Database changed
mysql> create table t_emoji(a varchar(30)) charset utf8mb4;
Query OK, 0 rows affected (0.01 sec)
mysql> insert into t_emoji values('row1:😀😀😀');
ERROR 1366 (HY000): Incorrect string value: '\xF0\x9F\x98\x80\xF0\x9F...' for column 'a' at row 1
### 使用emoji数据时,字符集需要设置为utf8mb4
mysql> set names utf8mb4;
Query OK, 0 rows affected (0.00 sec)
mysql> insert into t_emoji values('row1:😀😀😀');
Query OK, 1 row affected (0.00 sec)
mysql> insert into t_emoji values('row2:no emoji chars');
Query OK, 1 row affected (0.00 sec)
### 我们确认表里的数据没有问题
mysql> select * from t_emoji;
+---------------------+
| a |
+---------------------+
| row1:😀😀😀 |
| row2:no emoji chars |
+---------------------+
2 rows in set (0.00 sec)接下来我们使用 mysqldump 来备份刚刚创建的表。
$ mysqldump -uroot db_emoji > db_emoji.sql我们知道 mysqldump 产生的是数据库的逻辑备份,会将库表里的数据以 INSERT 语句的方式导出。
$ grep 'INSERT INTO' db_emoji.sql
INSERT INTO `t_emoji` VALUES ('row1:???'),('row2:no emoji chars');检查后发现 emoji 字符都被替换成了问号。如果我们将刚刚备份出来的数据恢复到数据库,就会发现数据有问题了。
解决这个问题,需要在备份时指定正确的字符集。
$ mysqldump --default-character-set utf8mb4 -uroot db_emoji > db_emoji_utf8mb4.sql
$ grep 'INSERT INTO' db_emoji_utf8mb4.sql
INSERT INTO `t_emoji` VALUES ('row1:😀😀😀'),('row2:no emoji chars');可以看到,将字符集指定为 utf8mb4 后,导出的数据就没有问题了。因此,在使用 mysqldump 备份时,建议统一都指定 utf8mb4 字符集。
总结时刻
在这一讲中,我们学习了文本编码和解码的一般过程,以及乱码产生的几种情况。我们还学习了 MySQL 如何处理文本编码,以及在使用 MySQL 时你可能会遇到的几种乱码问题,并给出了相应的解决方法。
最后总结一下几个关键点。
-
根据需要存储和处理的文本类型决定使用哪种字符集。一般如果要处理中文,可以选择 GBK 或 UTF8 字符集。GBK 使用双字节存储一个汉字,在空间上有一定的优势。UTF8 适用性更广。
-
客户端需要设置正确的字符集。字符集的设置要和程序中数据的实际编码保持一致。
-
MySQL 中,建议使用 utf8mb4 字符集。因为 MySQL 中 UTF8 字符集实际上是 utf8mb3,无法存储 4 字节的 Unicode 编码,如 emoji 字符。
-
数据库中,建议选择一种统一的字符编码,尽量避免使用多种不同的字符集。
思考
某一个项目发布时,执行了以下数据初始化脚本。
mysql> CREATE TABLE `t_b` (
-> `a` varchar(30) DEFAULT NULL
-> ) ENGINE=InnoDB DEFAULT CHARSET=gbk;
Query OK, 0 rows affected (0.03 sec)
mysql> set names gbk;
Query OK, 0 rows affected (0.00 sec)
mysql> insert into t_b values('中文符号');
Query OK, 1 row affected (0.00 sec)对数据进行检查后,没有发现任何问题。
mysql> select * from t_b;
+--------------+
| a |
+--------------+
| 中文符号 |
+--------------+
1 row in set (0.00 sec)但是另外一个同事查询这个表时,发现无论怎么设置字符集,查出来都是乱码。
mysql> set names utf8;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> select * from t_b;
+------------------+
| a |
+------------------+
| 娑??鏋冪粭锕褰? |
+------------------+
1 row in set (0.00 sec)
mysql> set names gbk;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from t_b;
+--------------+
| a |
+--------------+
| 涓枃绗﹀彿 |
+--------------+
1 row in set (0.00 sec)这位同事找到了你,请你帮忙分析为什么会出现这样的问题?应该如何解决呢?
要点总结
- 乱码产生的原因主要是由于字符集编码和解码不匹配导致的,程序无法准确判断数据的编码方式,因此容易出现乱码问题。
- MySQL中的字符集变量和表、列的字符集属性的设置对于避免乱码问题至关重要,需要正确设置这些变量和属性以确保数据的正确编码和解码。
- 通过正确设置字符集变量和表、列的字符集属性,可以有效避免MySQL中出现乱码问题,确保数据的正确编码和解码。
- 在进行数据迁移、数据导入导出后,需要重点检查是否有乱码产生,字符集设置不对可能会导致乱码问题。
- 在执行DDL时,如果终端环境和数据库字符集参数设置不一致,并且DDL中使用了中文符号,也可能会产生乱码。
- 在使用mysqldump备份时,建议统一都指定 utf8mb4 字符集。
- 根据需要存储和处理的文本类型决定使用哪种字符集,一般如果要处理中文,可以选择GBK或UTF8字符集。
- 客户端需要设置正确的字符集,要和程序中数据的实际编码保持一致。
- MySQL中,建议使用 utf8mb4 字符集,因为MySQL中UTF8字符集实际上是 utf8mb3,无法存储4字节的Unicode编码,如emoji字符。
- 数据库中,建议选择一种统一的字符编码,尽量避免使用多种不同的字符集。