内容纲要
前言
我们在使用 Elasticsearch 官方默认的分词插件时会发现,其对中文的分词效果不佳,经常分词后得效果不是我们想要的。
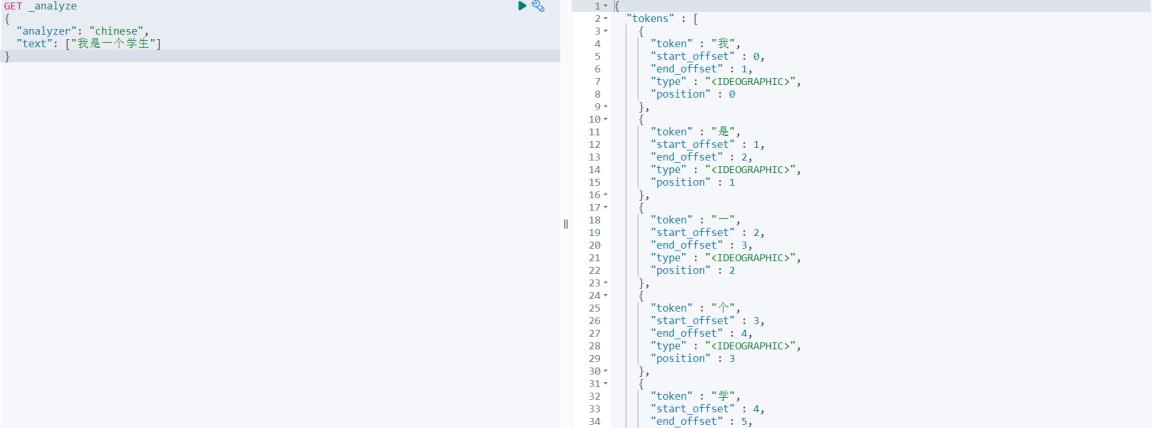
如:我是一个学生,被分词为:\"我\", \"是\" ,\"一\" ,\"个\" ,\"学\" ,\"生\"
GET _analyze
{
"analyzer": "chinese",
"text": ["我是一个学生"]
}
为了能够更好地对中文进行搜索和查询,就需要在Elasticsearch中集成好的分词器插件,而 IK 分词器就是用于对中文提供支持得插件。
集成 IK 分词器
1、下载
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
注意:选择下载的版本要与 Elasticsearch 版本对应。我们这里选择 8.1.0
2、安装
在安装目录得 plugins 目中,将下载得压缩包直接解压缩得里面即可

重启 Elasticsearch 服务
3、使用 IK 分词器
IK 分词器提供了两个分词算法:
- ik_smart: 最少切分
- Ik_max_word:最细粒度划分
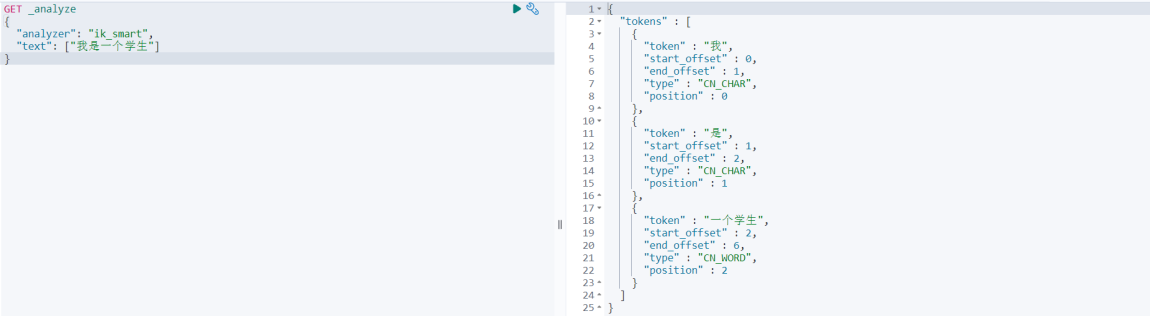
接下来使用 ik_smart 算法对之前得中文内容进行分词,明显会发现和默认分词器的区别。
GET _analyze
{
"analyzer": "ik_smart",
"text": ["我是一个学生"]
}得到结果 \"我\", \"是\", \"一个\", \"学生\"
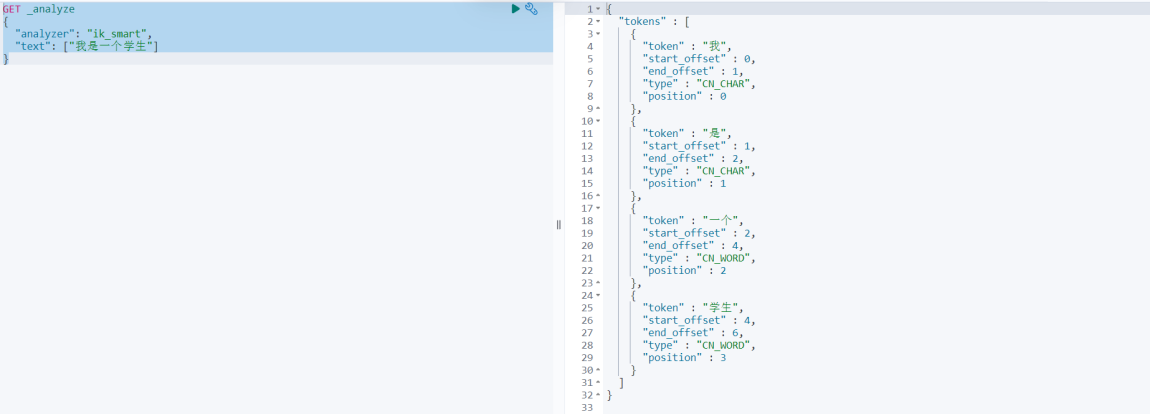
接下来,再对比 ik_max_word 算法分词后的效果
得到结果 \"我\", \"是\", \"一个\", \"一\", \"个\", \"学生\"

4、自定义分词效果
我们在使用 IK 分词器时会发现其实有时候分词的效果也并不是我们所期待的,有时一些特殊得术语会被拆开,比如上面得中文“一个学生”希望不要拆开,怎么做呢?其实 IK 插件给我们提供了自定义分词字典,我们就可以添加自己想要保留得字了。

接下来我们修改配置文件:IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">test.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>重启 Elasticsearch 服务器查看效果
GET _analyze
{
"analyzer": "ik_smart",
"text": ["我是一个学生"]
}得到结果:\"我\", \"是\", \"一个学生\"