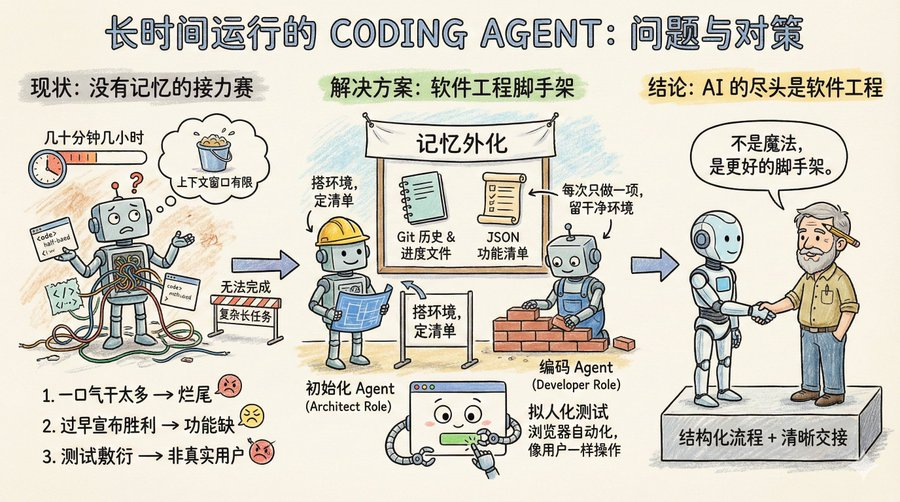
想象一下,一个软件团队在做一个大项目,但有个奇怪的规定:每个工程师只能工作几十分钟,最多几小时,干完就要换一个新的工程师。所以让这个团队完成简单项目任务还行,复杂一点需要长时间运行的项目,比如你让它克隆一个 claude .ai,它就做不到。
这其实就是 Coding Agent 的现状:没有记忆,上下文窗口长度有限。所以要它执行长时间任务,它还做不好。
Anthropic 的这篇博客:《Effective harnesses for long-running agents》,专门讨论了如何让 Agent 在跨越多个上下文窗口时依然能持续推进任务。
先看 Agent 在长任务中遇到的主要问题是什么?
主要三种:
第一种叫一口气干太多。比如你让 Agent 克隆一个 claude .ai 这样的网站,它会试图一次性搞定整个应用。结果上下文还没用完,功能写了一半,代码乱成一锅粥。下一个会话进来,面对半成品只能干瞪眼,花很多时间猜测前面到底做了什么。
第二种叫过早宣布胜利。项目做了一部分,后来的 Agent 看看环境,觉得好像差不多了,就直接收工。功能缺一大堆也不管。
第三种叫测试敷衍。Agent 改完代码,跑几个单元测试或者 curl 一下接口就觉得万事大吉,根本没有像真实用户那样端到端走一遍流程。
这三种失败模式的共同点是 Agent 不知道全局目标,也不知道该在哪里停下来、该留下什么给下一位。
那么 Anthropic 的解决方案是什么呢?
其实就是软件工程的一些现成的解决方案:引入类似人类团队的分工协作机制,将复杂任务拆解成小的可跟踪验证的任务,清晰的交接机制,并严格验证任务结果
一个初始化 Agent,它只在项目启动时出场一次,任务是搭好项目运行环境:有点像架构师的角色,写一个 init .sh 脚本方便后续启动开发服务器,建一个 claude-progress.txt 记录进度,做第一次 git 提交,最关键的是生成一份功能清单。
这份功能清单有多细?在克隆 claude .ai 的案例中,列了超过 200 条具体功能,比如用户能打开新对话、输入问题、按回车、看到 AI 回复。每一条初始状态都标记为失败,后续 Agent 必须逐条验证通过才能改成成功。
而且这里有个细节,这个清单不是用 Markdown 来写的,是一个 JSON 数组,因为 Anthropic 实验发现,相比 Markdown,模型在处理 JSON 时更不容易随意篡改或覆盖文件。
另一个是编码 Agent。在初始化项目后,后续就是它干活了,核心行为准则只有两条:一次只做一个功能,做完要留下干净的环境。
什么叫干净的环境?想象你往主分支提交代码的标准:没有严重 bug,代码整齐有文档,下一个人接手能直接开始新功能,不用先替你收拾烂摊子。
每次开工前,它先做几件事:
– 运行 pwd 看看自己在哪个目录
– 读 Git 日志和进度文件,搞清楚上一轮干了啥
– 看功能清单,挑一个最高优先级的未完成功能
– 跑一遍基础测试,确保 App 还能用
然后专心做一个功能,做完后:
– 写清楚的 Git commit message
– 更新 claude-progress.txt
– 只改功能清单里的状态字段,绝不删改需求本身
这个设计的巧妙之处在于,它把“记忆”外化成了文件和 Git 历史。每一轮的 Agent 不需要依赖上下文窗口里的碎片信息,而是模仿靠谱的人类工程师每天上班会做的事。先同步进度,确认环境正常,再动手干活。
测试环节的改进值得单独说。
原来 Agent 只会用代码层面的方式验证,比如跑单元测试或者调接口。问题是很多 bug 只有用户真正操作页面时才会暴露。
解决方案是给 Agent 配上浏览器自动化工具,比如 Puppeteer MCP。Agent 现在能像真人一样打开浏览器、点按钮、填表单、看页面渲染结果。Anthropic 放了一张动图,展示 Agent 测试克隆版 claude .ai 时自己截的图,确实是在像用户那样操作。
这招大幅提升了功能验证的准确率。当然也有边界,比如浏览器原生的 alert 弹窗,Puppeteer 捕捉不到,依赖弹窗的功能就容易出 bug。
这套方案还留了一些开放问题。
比如,到底是一个通用 Agent 全包好,还是搞专业分工?让测试 Agent 专门测,代码清理 Agent 专门收拾,也许效果更好。
再比如,这套经验是针对全栈 Web 开发优化的,能不能迁移到科研或金融建模这类长周期任务?应该可以,但需要实验验证。
响马
@xicilion
说:
ai 的尽头依旧是软件工程。
AI Agent 也不是魔法,它一样需要从人类软件工程中汲取经验,它也需要将复杂的任务进行分解成简单的任务,要有一个结构化的工作环境和清晰的交接机制。
人类工程师为什么能跨团队、跨时区协作?因为有 Git、有文档、有 Code Review、有测试。AI Agent 要想长时间自主工作,也得把这些东西搬过来。
Anthropic 的方案,不过是把软件工程的最佳实践变成了 Agent 能理解的提示词和工具链。不是让模型变得更聪明,而是给它提供更好的脚手架。
Anthropic 的思路值得借鉴。无论你用的是 Claude、GPT 还是别的模型,在设计多轮长任务时,都要想清楚,怎么让下一轮的 Agent 快速进入状态,怎么避免它重复造轮子或者把代码搞成一团乱麻。即使是单轮任务,也要清楚它是没有记忆的,你需要通过外部文件来帮助它“想起来”之前做过的事。
以现在模型的能力,Coding Agent 已经能做很多事情了,核心还是在于你是不是能像软件工程中那样,去分解好任务,设计好工作的流程。
原文:Effective harnesses for long-running agents https://anthropic.com/engineering/effective-harnesses-for-long-running-agents
翻译:https://baoyu.io/translations/effective-harnesses-for-long-running-agents